












近日,两个外国小哥Kartik Godawat 和 Deepak Rawat 开发了一个 Jupyter 插件Text2Code,可以将自然语言查询转换成相关的 Python 数据分析代码。
如果能创建一个桌面软件,将自然语言直接转换成相关的 Python 数据分析代码,工作就方便了。
这不,有俩「好事」的程序员耐不住寂寞,把这个工具做出来。
灵感来自GPT-3,自然语言直接转代码
2020年6月,OpenAI 推出了GPT-3,它不仅具有未来的 NLP 相关的诸多功能,而且还能够生成 React 代码和shell命令。
俩人从中得到了灵感,他们意识到在做数据分析的时候,我们经常忘记不经常使用的 pandas 命令或者语法,需要去搜索,从 StackOverflow 复制代码然后需要相应地修改变量和列名。
最初他们试图把这个问题作为一个聊天机器人来解决,并试图使用Rasa,但因为缺乏合适的训练数据而夭折了。
他们决定开发一个监督学习模型,该模型可以吃进自然语言和代码的对应语料,然后进行训练,完整的pipeline包含了下面几个步骤:
生成训练数据
为了模拟终端的用户想向系统查询的内容,我们开始尝试用英语描述一些命令的格式。
例如:
display a line plot showing $colname on y-axis and $colname on x-axis from $varname
然后,我们通过使用一个非常简单的生成器来替换 $colname 和 $varname 来生成数据,以获得训练集中的变量。

意图匹配
在生成数据之后,需要为特定的意图映射到一个唯一的「意图id」,并使用通用语句编码器获取用户query的embedding,然后用我们预先定义好的意图query(生成的数据)来得到余弦距离。
「通用句子编码器」-Universal Sentence Encoder类似于 word2vec,会生成相应的embedding,唯一的区别是这里的嵌入是用于句子而不是单词。

命名实体识别
相同的生成数据可以被用来训练一个自定义的实体识别模型,这个模型可以用来检测columns,varaibles,library的名字。
为此,作者还研究了 HuggingFace 模型,但最终决定使用 Spacy 来训练模型,主要是因为 HuggingFace 模型是基于Transformer的模型,与 Spacy 相比有点过于复杂繁重。

填充模板
一旦实体被正确识别并且意图被正确匹配,填充模板就变得非常容易。
例如,“ show 5 rows from df”这个查询将生成两个实体: 一个变量和一个数值。这个模板代码编写起来很简单。

与Jupyter结合
这是所有步骤里最复杂的一步,因为为 Jupyter 编写如此复杂的扩展有点棘手,而且几乎没有文档或示例参考。
他们通过一些尝试并参考已经存在的扩展,最终将所有内容包装成一个单独的 Python 包,并且可以直接通过 pip 来安装。
单单一个Python包并不能直接使用,于是他们创建了一个前端以及一个服务器扩展,当 jupyter notebook启动时,就会被加载。前端向服务器发送查询以获取生成的模板代码,然后将其插入notebook的对应单元并执行它。
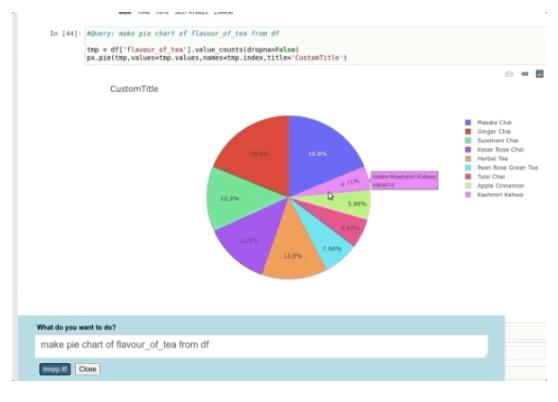
Text2Code的演示
模型也会失效,但数据分析师真的省事了
就像许多机器学习模型一样,有时候意图匹配和命名实体识别效果会很差,即使这个意图对人来说非常简单。
有时也会识别不到意图,就无法生成正确的代码,作者还考虑使用下面的方法来进一步改进插件的效果。
收集/生成高质量的英语训练数据,可以考虑从quroa,StackOverflow爬取更多的高赞回答,尝试用不同的方式来描述相同的内容,增强数据;收集真实世界的变量名和库名,而不是随机生成,使用基于Transformer的模型尝试命名实体识别。
如果这个模型训练的足够好,对数据分析师来,能省不少事了。
项目开源地址:
https://github.com/deepklarity/jupyter-text2code

























