












湖加速即为数据湖加速,是指在数据湖架构中,为了统一支持各种计算,对数据湖存储提供适配支持,进行优化和缓存加速的中间层技术。那么为什么需要湖加速?数据湖如何实现“加速”?本文将从三个方面来介绍湖加速背后的原因,分享阿里云在湖加速上的实践经验和技术方案。
在开源大数据领域,存储/计算分离已经成为共识和标准做法,数据湖架构成为大数据平台的首要选择。基于这一范式,大数据架构师需要考虑三件事情:
- 第一,选择什么样的存储系统做数据湖(湖存储)?
- 第二,计算和存储分离后,出现了性能瓶颈,计算如何加速和优化(湖加速)?
- 第三,针对需要的计算场景,选择什么样的计算引擎(湖计算)?
湖存储可以基于我们熟悉的HDFS,在公共云上也可以选择对象存储,例如阿里云OSS。在公共云上,基于对象存储构建数据湖是目前业界最主流的做法,我们这里重点探讨第二个问题,结合阿里云上的EMR JindoFS优化和实践,看看数据湖怎么玩“加速”。
湖加速
在数据湖架构里,湖存储(HDFS,阿里云OSS)和湖计算(Spark,Presto)都比较清楚。那么什么是湖加速?大家不妨搜索一下…(基本没有直接的答案)。湖加速是阿里云EMR同学在内部提出来的,顾名思义,湖加速即为数据湖加速,是指在数据湖架构中,为了统一支持各种计算,对数据湖存储提供适配支持,进行优化和缓存加速的中间层技术。这里面出现较早的社区方案应该是Alluxio,Hadoop社区有S3A Guard,AWS有EMRFS,都适配和支持AWS S3,Snowflake在计算侧有SSD缓存,Databricks有DBIO/DBFS,阿里云有EMR JindoFS,大体都可以归为此类技术。
那么为什么需要湖加速呢?这和数据湖架构分层,以及相关技术演进具有很大关系。接下来,我们从三个方面的介绍来寻找答案。分别是:基础版,要适配;标配版,做缓存;高配版,深度定制。JindoFS同时涵盖这三个层次,实现数据湖加速场景全覆盖。
基础版:适配对象存储
以Hadoop为基础的大数据和在AWS上以EC2/S3为代表的云计算,在它们发展的早期,更像是在平行的两个世界。等到EMR产品出现后,怎么让大数据计算(最初主要是MapReduce)对接S3,才成为一个真实的技术命题。对接S3、OSS对象存储,大数据首先就要适配对象接口。Hadoop生态的开源大数据引擎,比如Hive和Spark,过去主要是支持HDFS,以Hadoop Compatible File System(HCFS)接口适配、并支持其他存储系统。机器学习生态(Python)以POSIX接口和本地文件系统为主,像TensorFlow这种深度学习框架当然也支持直接使用HDFS 接口。对象存储产品提供REST API,在主要开发语言上提供封装好的SDK,但都是对象存储语义的,因此上述这些流行的计算框架要用,必须加以适配,转换成HCFS接口或者支持POSIX。这也是为什么随着云计算的流行,适配和支持云上对象存储产品成为Hadoop社区开发的一个热点,比如S3A FileSytem。阿里云EMR团队则大力打造JindoFS,全面支持阿里云OSS并提供加速优化。如何高效地适配,并不是设计模式上增加一层接口转换那么简单,做好的话需要理解两种系统(对象存储和文件系统)背后的重要差异。我们稍微展开一下:
第一,海量规模。
对象存储提供海量低成本存储,相比文件系统(比如HDFS),阿里云OSS更被用户认为可无限扩展。同时随着各种BI技术和AI技术的流行和普及,挖掘数据的价值变得切实可行,用户便倾向于往数据湖(阿里云OSS)储存越来越多不同类型的数据,如图像、语音、日志等等。这在适配层面带来的挑战就是,需要处理比传统文件系统要大许多的数据量和文件数量。千万级文件数的超大目录屡见不鲜,甚至包含大量的小文件,面对这种目录,一般的适配操作就失灵了,不是OOM就是hang在那儿,根本就不可用。JindoFS一路走来积累了很多经验,我们对大目录的listing操作和du/count这种统计操作从内存使用和充分并发进行了深度优化,目前达到的效果是,千万文件数超大目录,listing操作比社区版本快1倍,du/count快21%,整体表现更为稳定可靠。
第二,文件和对象的映射关系。
对象存储提供key到blob对象的映射,这个key的名字空间是扁平的,本身并不具备文件系统那样的层次性,因此只能在适配层模拟文件/目录这种层次结构。正是因为要靠模拟,而不是原生支持,一些关键的文件/目录操作代价昂贵,这里面最为知名的就是rename了。文件rename或者mv操作,在文件系统里面只是需要把该文件的inode在目录树上挪动下位置即可,一个原子操作;但是在对象存储上,往往受限于内部的实现方式和提供出来的标准接口,适配器一般需要先copy该对象到新位置,然后再把老对象delete掉,用两个独立的步骤和API调用。对目录进行rename操作则更为复杂,涉及到该目录下的所有文件的rename,而每一个都是上述的copy+delete;如果目录层次很深,这个rename操作还需要递归嵌套,涉及到数量巨大的客户端调用次数。对象的copy通常跟它的size相关,在很多产品上还是个慢活,可以说是雪上加霜。阿里云OSS在这方面做了很多优化,提供Fast Copy能力,JindoFS充分利用这些优化支持,结合客户端并发,在百万级大目录rename操作上,性能比社区版本接近快3X。
第三,一致性。
为了追求超大并发,不少对象存储产品提供的是最终一致性(S3),而不是文件系统常见的强一致性语义。这带来的影响就是,举个栗子,程序明明往一个目录里面刚刚写好了10个文件,结果随后去list,可能只是部分文件可见。这个不是性能问题,而是正确性了,因此在适配层为了满足大数据计算的需求,Hadoop社区在S3A适配上花了很大力气处理应对这种问题,AWS自己也类似提供了EMRFS,支持ConsistentView。阿里云OSS提供了强一致性,JindoFS基于这一特性大大简化,用户和计算框架使用起来也无须担心类似的一致性和正确性问题。
第四,原子性。
对象存储自身没有目录概念,目录是通过适配层模拟出来的。对一个目录的操作就转化为对该目录下所有子目录和文件的客户端多次调用操作,因此即使是每次对象调用操作是原子的,但对于用户来说,对这个目录的操作并不能真正做到原子性。举个例子,删除目录,对其中任何一个子目录或文件的删除操作失败(包含重试),哪怕其他文件删除都成功了,这个目录删除操作整体上还是失败。这种情况下该怎么办?通常只能留下一个处于中间失败状态的目录。JindoFS在适配这些目录操作(rename,copy,delete and etc)的时候,结合阿里云 OSS 的扩展和优化支持,在客户端尽可能重试或者回滚,能够很好地衔接数据湖各种计算,在pipeline 上下游之间保证正确处理。
第五,突破限制。
对象存储产品是独立演化发展的,少不了会有自己的一些独门秘籍,这种特性要充分利用起来可能就得突破HCFS抽象接口的限制。这里重点谈下对象存储的高级特性Concurrent MultiPartUpload (CMPU),该特性允许程序按照分片并发上传part的方式高效写入一个大对象,使用起来有两个好处,一个是可以按照并发甚至是分布式的方式写入一个大对象,实现高吞吐,充分发挥对象存储的优势;另外一个是,所有parts都是先写入到一个staging区域的,直到complete的时候整个对象才在目标位置出现。利用阿里云OSS这个高级特性,JindoFS开发了一个针对MapReduce模型的Job Committer,用于Hadoop,Spark 和类似框架,其实现机制是各个任务先将计算结果按照part写入到临时位置,然后作业commit的时候再complete这些结果对象到最终位置,实现无须rename的效果。我们在Flinkfile sink connector支持上也同样往计算层透出这方面的额外接口,利用这个特性支持了Exactly-Once的语义。
标配版:缓存加速
数据湖架构对大数据计算的另外一个影响是存/算分离。存储和计算分离,使得存储和计算在架构上解耦,存储朝着大容量低成本规模化供应,计算则向着弹性伸缩,丰富性和多样化向前发展,在整体上有利于专业化分工和大家把技术做深,客户价值也可以实现最大化。但是这种分离架构带来一个重要问题就是,存储带宽的供应在一些情况下可能会跟计算对存储带宽的需求不相适应。计算要跨网络访问存储,数据本地性消失,访问带宽整体上会受限于这个网络;更重要的是,在数据湖理念下,多种计算,越来越多的计算要同时访问数据,会竞争这个带宽,最终使得带宽供需失衡。我们在大量的实践中发现,同一个OSS bucket,Hive/Spark数仓要进行ETL,Presto要交互式分析,机器学习也要抽取训练数据,这个在数据湖时代之前不可想象,那个时候也许最多的就是MapReduce作业了。这些多样化的计算,对数据访问性能和吞吐的需求却不遑多让甚至是变本加厉。常驻的集群希望完成更多的计算;弹性伸缩的集群则希望尽快完成作业,把大量节点给释放掉节省成本;像Presto这种交互式分析业务方希望是越快越好,稳定亚秒级返回不受任何其他计算影响;而GPU训练程序则是期望数据完全本地化一样的极大吞吐。像这种局面该如何破呢?无限地增加存储侧的吞吐是不现实的,因为整体上受限于和计算集群之间的网络。有效地保证丰富的计算对存储带宽的需求,业界早已给出的答案是计算侧的缓存。Alluxio一直在做这方面的事情,JindoFS核心定位是数据湖加速层,其思路也同出一辙。下面是它在缓存场景上的架构图。
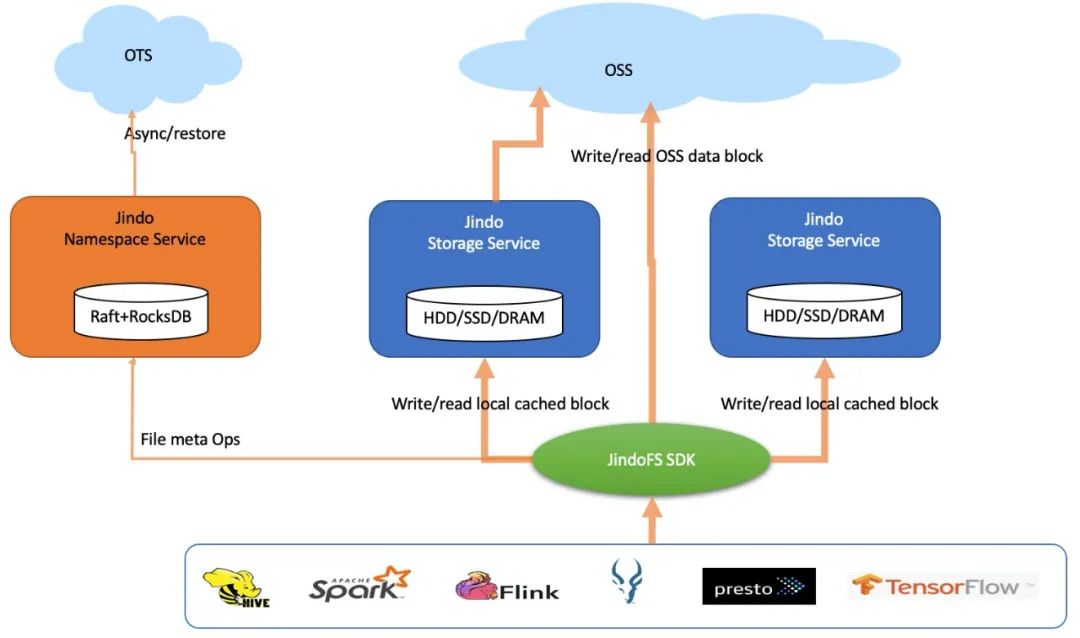
JindoFS在对阿里云OSS适配优化的同时,提供分布式缓存和计算加速,刚刚写出去的和重复访问的数据可以缓存在本地设备上,包括HDD,SSD和内存,我们都分别专门优化过。这种缓存加速是对用户透明的,本身并不需要计算额外的感知和作业修改,在使用上只需要在OSS适配的基础上打开一个配置开关,开启数据缓存。叠加我们在适配上的优化,跟业界某开源缓存方案相比,我们在多个计算场景上都具有显著的性能领先优势。基于磁盘缓存,受益于我们能够更好地balance多块磁盘负载和高效精细化的缓存块管理,我们用TPC-DS 1TB进行对比测试,SparkSQL性能快27%;Presto大幅领先93%;在HiveETL场景上,性能领先42%。JindoFS 的 FUSE支持完全采用 native 代码开发而没有 JVM 的负担,基于SSD缓存,我们用TensorFlow程序通过JindoFuse来读取JindoFS上缓存的OSS数据来做训练,相较该开源方案性能快40%。
在数据湖架构下在计算侧部署缓存设备引入缓存,可以实现计算加速的好处,计算效率的提升则意味着更少的弹性计算资源使用和成本支出,但另一方面毋庸讳言也会给用户带来额外的缓存成本和负担。如何衡量这个成本和收益,确定是否引入缓存,需要结合实际的计算场景进行测试评估,不能一概而论。
高配版:深度定制,自己管理文件元数据
我们在JindoFS上优化好OSS适配,把Jindo分布式缓存性能做到效能最大化,能满足绝大多数大规模分析和机器学习训练这些计算。现有的JindoFS大量部署和使用表明,无论Hive/Spark/Impala这种数仓作业,Presto交互式分析,还是TensorFlow训练,我们都可以在计算侧通过使用阿里云缓存定制机型,来达到多种计算高效访问OSS数据湖的吞吐要求。可是故事并没有完,数据湖的架构决定了计算上的开放性和更加多样性,上面这些计算可能是最主要的,但并不是全部,JindoFS在设计之初就希望实现一套部署,即能覆盖各种主要场景。一个典型情况是,有不少用户希望JindoFS能够完全替代HDFS,而不只是Hive/Spark够用就可以了,用户也不希望在数据湖架构下还要混合使用其他存储系统。整理一下大概有下面几种情况需要我们进一步考虑。
第一、上面讨论对象存储适配的时候我们提到,一些文件/目录操作的原子性需求在本质上是解决不了的,比如文件的rename,目录的copy,rename和delete。彻底解决这些问题,完全满足文件系统语义,根本上需要自己实现文件元数据管理,像HDFS NameNode那样。
第二、HDFS有不少比较高级的特性和接口,比如支持truncate,append,concat,hsync,snapshot和Xattributes。像HBase依赖hsync/snapshot,Flink依赖truncate。数据湖架构的开放性也决定了还会有更多的引擎要对接上来,对这些高级接口有更多需求。
第三、HDFS重度用户希望能够平迁上云,或者在存储方案选择上进行微调,原有基于HDFS的应用,运维和治理仍然能够继续使用。在功能上提供Xattributes支持,文件权限支持,Ranger集成支持,甚至是auditlog支持;在性能上希望不低于HDFS,最好比HDFS还好,还不需要对NameNode调优。为了也能够享受到数据湖架构带来的各种好处,该如何帮助这类用户基于OSS进行架构升级呢?
第四、为了突破S3这类对象存储产品的局限,大数据业界也在针对数据湖深度定制新的数据存储格式,比如Delta,Hudi,和Iceberg。如何兼容支持和有力优化这类格式,也需要进一步考虑。
基于这些因素,我们进一步开发和推出JindoFS block模式,在OSS对象存储的基础上针对大数据计算进行深度定制,仍然提供标准的HCFS接口,因为我们坚信,即使同样走深度定制路线,遵循现有标准与使用习惯对用户和计算引擎来说更加容易推广和使用,也更加符合湖加速的定位和使命。JindoFS block模式对标HDFS,不同的是采取云原生的架构,依托云平台我们做了大量简化,使得整个系统具有弹性,轻量和易于运维的特点和优势。
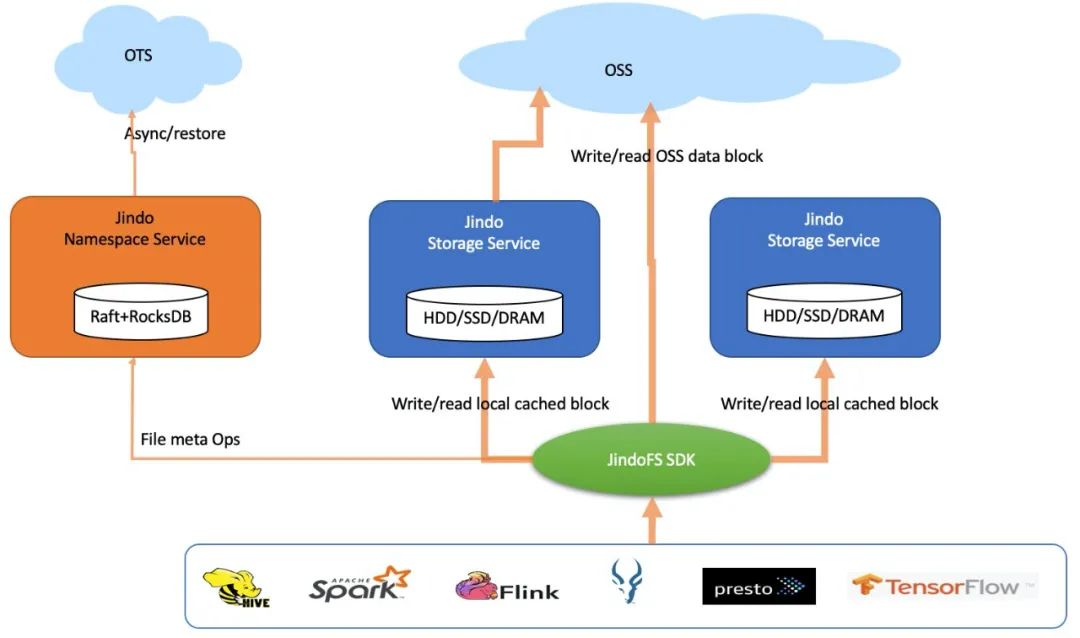
如上图示,是JindoFS在block模式下的系统架构,整体上重用了JindoFS缓存系统。在这种模式下,文件数据是分块存放在OSS上,保证可靠和可用;同时借助于本地集群上的缓存备份,可以实现缓存加速。文件元数据异步写入到阿里云OTS数据库防止本地误操作,同时方便JindoFS集群重建恢复;元数据在正常读写时走本地RocksDB,内存做LRU缓存,因此支撑的文件数在亿级;结合元数据服务的文件/目录级别细粒度锁实现,JindoFS在大规模高并发作业高峰的时候表现比HDFS更稳定,吞吐也更高。我们用HDFS NNBench做并发测试,对于最关键的open和create操作,JindoFS的IOPS比HDFS高60%。在千万级超大目录测试上,文件listing操作比HDFS快130%;文件统计du/count操作比HDFS快1X。借助于分布式Raft协议,JindoFS支持HA和多namespaces,整体上部署和维护比HDFS简化太多。在IO吞吐上,因为除了本地磁盘,还可以同时使用OSS带宽来读,因此在同样的集群配置下用DFSIO实测下来,读吞吐JindoFS比HDFS快33%。
JindoFS在湖加速整体解决方案上进一步支持block模式,为我们拓宽数据湖使用场景和支持更多的引擎带来更大的想象空间。目前我们已经支持不少客户使用HBase,为了受益于这种存/算分离的架构同时借助于本地管理的存储设备进行缓存加速,我们也在探索将更多的开源引擎对接上来。比如像Kafka,Kudu甚至OLAP新贵ClickHouse,能不能让这些引擎专注在它们的场景上,将它们从坏盘处理和如何伸缩这类事情上彻底解放出来。原本一些坚持使用HDFS的客户也被block模式这种轻运维,有弹性,低成本和高性能的优势吸引,通过这种方式也转到数据湖架构上来。如同对OSS的适配支持和缓存模式,JindoFS这种新模式仍然提供完全兼容的HCFS和FUSE支持,大量的数据湖引擎在使用上并不需要增加额外的负担。
总结
行文至此,我们做个回顾和总结。基于数据湖对大数据平台进行架构升级是业界显著趋势,数据湖架构包括湖存储、湖加速和湖分析,在阿里云上我们通过 JindoFS 针对各种场景提供多种数据湖加速解决方案。阿里云推出的专门支持数据湖管理的Data Lake Formation,可全面支持数据湖。
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】
























