












假定,你已经收集了一个数据集,建立了一个神经网络,并训练了您的模型。
但是,尽管你投入了数小时(有时是数天)的工作来创建这个模型,它还是能得到50-70%的准确率。这肯定不是你所期望的。
下面是一些提高模型性能指标的策略或技巧,可以大大提升你的准确率。
得到更多的数据
这无疑是最简单的解决办法,深度学习模型的强大程度取决于你带来的数据。增加验证准确性的最简单方法之一是添加更多数据。如果您没有很多训练实例,这将特别有用。
如果您正在处理图像识别模型,您可以考虑通过使用数据增强来增加可用数据集的多样性。这些技术包括从将图像翻转到轴上、添加噪声到放大图像。如果您是一个强大的机器学习工程师,您还可以尝试使用GANs进行数据扩充。

请注意,您使用的增强技术会更改图像的整个类。例如,在y轴上翻转的图像没有意义!
添加更多的层
向模型中添加更多层可以增强它更深入地学习数据集特性的能力,因此它将能够识别出作为人类可能没有注意到的细微差异。
这个技巧图解决的任务的性质。
对于复杂的任务,比如区分猫和狗的品种,添加更多的层次是有意义的,因为您的模型将能够学习区分狮子狗和西施犬的微妙特征。
对于简单的任务,比如对猫和狗进行分类,一个只有很少层的简单模型就可以了。
更多的层->更微妙的模型
更改图像大小
当您对图像进行预处理以进行训练和评估时,需要做很多关于图像大小的实验。
如果您选择的图像尺寸太小,您的模型将无法识别有助于图像识别的显著特征。
相反,如果您的图像太大,则会增加计算机所需的计算资源,并且/或者您的模型可能不够复杂,无法处理它们。
常见的图像大小包括64x64、128x128、28x28 (MNIST)和224x224 (vgg -16)。
请记住,大多数预处理算法不考虑图像的高宽比,因此较小尺寸的图像可能会在某个轴上收缩。

从一个大分辨率的图像到一个小尺寸的图像,比如28x28,通常会导致大量的像素化,这往往会对你的模型的性能产生负面影响
增加训练轮次
epoch基本上就是你将整个数据集通过神经网络传递的次数。以+25、+100的间隔逐步训练您的模型。
只有当您的数据集中有很多数据时,才有必要增加epoch。然而,你的模型最终将到达一个点,即增加的epoch将不能提高精度。
此时,您应该考虑调整模型的学习速度。这个小超参数决定了你的模型是达到全局最小值(神经网络的最终目标)还是陷入局部最小值。
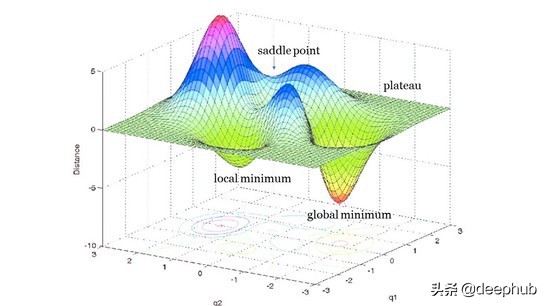
全局最小是神经网络的最终目标。
减少颜色通道
颜色通道反映图像数组的维数。大多数彩色(RGB)图像由三个彩色通道组成,而灰度图像只有一个通道。
颜色通道越复杂,数据集就越复杂,训练模型所需的时间也就越长。
如果颜色在你的模型中不是那么重要的因素,你可以继续将你的彩色图像转换为灰度。
你甚至可以考虑其他颜色空间,比如HSV和Lab。

RGB图像由三种颜色通道组成:红、绿、蓝
转移学习
迁移学习包括使用预先训练过的模型,如YOLO和ResNet,作为大多数计算机视觉和自然语言处理任务的起点。
预训练的模型是最先进的深度学习模型,它们在数百万个样本上接受训练,通常需要数月时间。这些模型在检测不同图像的细微差别方面有着惊人的巨大能力。
这些模型可以用作您的模型的基础。大多数模型都很好,所以您不需要添加卷积和池化
迁移学习可以大大提高你的模型的准确性~50%到90%!(来自英伟达的论文)
超参数
上面的技巧为你提供了一个优化模型的基础。要真正地调整模型,您需要考虑调整模型中涉及的各种超参数和函数,如学习率(如上所述)、激活函数、损失函数、甚至批大小等都是非常重要的需要调整的参数。
总结
这些技巧是希望大家在不知道如何去做的时候可以快速的找到提高的思路。
还有无数其他方法可以进一步优化你的深度学习,但是上面描述的这些方法只是深度学习优化部分的基础。
另外:每次改变深度学习模型时都要保存模型。这将帮助您重用先前的模型配置,如果它提供了更大的准确性。





















