













随着容器采用率和使用率的不断提高,Kubernetes(K8s)已成为容器编排的领先平台。 这是一个开源项目,拥有来自315多家公司的数万名贡献者,旨在保持可扩展性和不可知论性,并且它是每个主要云提供商的基础。
当您的容器正在生产中运行时,您希望生产环境尽可能稳定和有弹性,以避免灾难发生(请考虑每一次在线黑色星期五购物体验)。 当一个容器崩溃时,无论是在一天中的什么时候(或在夜晚的凌晨),另一个容器都需要启动起来代替它。 Kubernetes提供了一个框架,可从扩展到故障转移再到负载平衡等等,弹性地运行分布式系统。 并且有许多工具与Kubernetes集成在一起,可以满足您的需求。
最佳做法会随着时间而发展,因此不断进行研究和实验以寻求更好的Kubernetes开发方式总是好事。 由于它仍然是一项年轻技术,因此我们一直在寻求增进对它的理解和使用。
在本文中,我们将研究Kubernetes部署中的十种常见做法,这些做法在更高层次上具有更好的解决方案。 由于用户的自定义实现可能会有所不同,因此我不会深入探讨最佳实践。
- 将配置文件放在Docker映像的内部/旁边
- 不使用Helm或其他种类的模板
- 以特定顺序部署。 (应用程序应该不会崩溃,因为依赖关系尚未就绪。)
- 在没有设置内存和/或CPU限制的情况下部署Pod
- 在生产中将最新标签拉到容器中
- 通过杀死Pod来部署新的更新/修复,以便它们在重新启动过程中提取新的Docker映像
- 在同一集群中混合生产和非生产工作负载。
- 对于关键任务部署,不使用蓝绿部署或金丝雀部署。 (Kubernetes的默认滚动更新并不总是足够的。)
- 没有适当的指标来了解部署是否成功。 (您的健康检查需要应用程序支持。)
- 云供应商锁定:将自己锁定在IaaS提供商的Kubernetes或无服务器计算服务中
十个Kubernetes反模式
1. 将配置文件放在Docker映像的内部/旁边
该Kubernetes反模式与Docker反模式相关(请参阅本文的反模式5和8)。 容器为开发人员提供了一种方法,该方法基本上可以在生产环境中的整个软件生命周期(从dev / QA到staging到生产)中使用单个映像。
但是,通常的做法是为生命周期中的每个阶段提供自己的映像,每个阶段都使用针对其环境(QA,Staging或生产)的不同工件构建。 但是现在您不再部署已测试的产品。
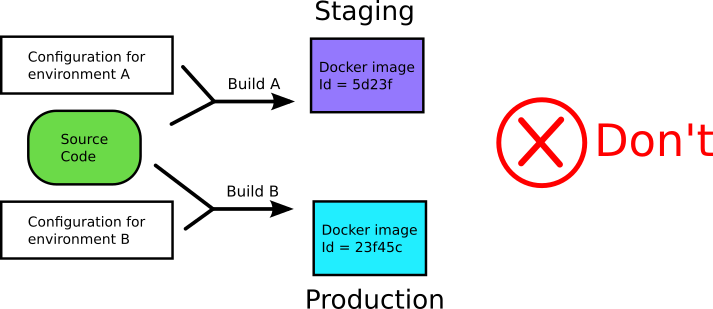
> Don't hardcode your configuration at build time (from https://codefresh.io/containers/docker-anti-
此处的最佳实践是外部化ConfigMap中的通用配置,而敏感信息(如API密钥和机密)可以存储在Secrets资源中(该资源具有Base64编码,但与ConfigMaps相同)。 ConfigMap可以作为卷安装,也可以作为环境变量传递,但是Secrets应该作为卷安装。 我之所以提到ConfigMap和Secrets,是因为它们是Kubernetes的本机资源,不需要集成,但是它们可能会受到限制。 还有其他可用的解决方案,例如HashiCorp的ZooKeeper和Consul用于配置映射,或HashiCorp的Vault,Keywhiz,Confidant等用于秘密,它们可能更适合您的需求。
当您将配置与应用程序分离后,就无需在需要更新配置时重新编译应用程序,并且可以在应用程序运行时对其进行更新。 您的应用程序在运行时而不是在构建过程中获取配置。 更重要的是,您在软件生命周期的所有阶段都使用相同的源代码。
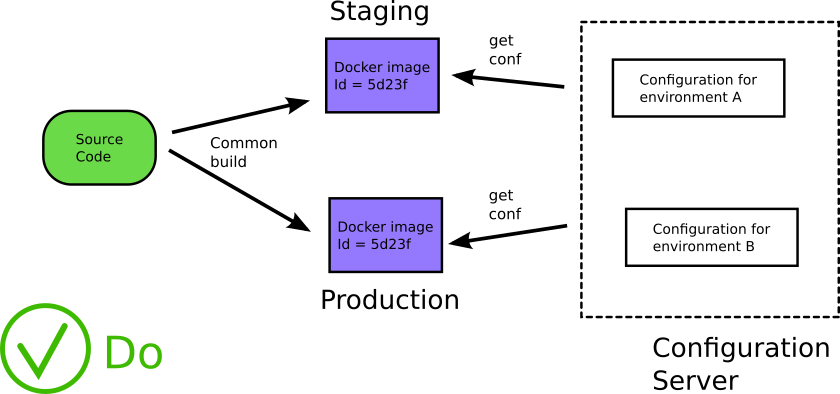
> Load configuration during runtime (from https://codefresh.io/containers/docker-anti-patterns/)
2. 不使用Helm或其他种类的模板
您可以通过直接更新YAML来管理Kubernetes部署。 推出新版本的代码时,您可能必须更新以下一项或多项内容:
- Docker映像名称
- Docker映像标签
- Replica 副本数
- Lable 服务标签
- Pod
- Configmap 等
如果您要管理多个集群并在开发,登台和生产环境中应用相同的更新,这可能会变得很乏味。 您基本上是在所有部署中进行少量修改的情况下修改相同文件。 它进行了大量的复制和粘贴,或搜索和替换,同时还了解部署YAML的目标环境。 在此过程中,有很多出错的机会:
- 拼写错误(版本号错误,图片名称拼写错误等)
- 使用错误的更新修改YAML(例如,连接到错误的数据库)
- 缺少要更新的资源,等等。
您可能需要在YAML中进行很多更改,如果您不密切注意,则很容易将一个YAML误认为另一个部署的YAML。
模板有助于简化Kubernetes应用程序的安装和管理。 由于Kubernetes没有提供本地的模板机制,因此我们必须在其他地方寻求这种管理。
Helm是第一个可用的包管理器(2015年)。 它被称为" Kubernetes的自制软件",并发展为包括模板功能。 Helm通过图表打包其资源,其中图表是描述一组相关的Kubernetes资源的文件的集合。 图表存储库中有1,400多个公开可用的图表(您也可以使用 helm search hub [keyword] [flags]),这些是可重复使用的配方,用于在Kubernetes上进行安装,升级和卸载。 使用Helm Chart,您可以修改values.yaml文件以设置Kubernetes部署所需的修改,并且每种环境都可以使用不同的Helm图表。 因此,如果您具有质量检查,过渡和生产环境,则只需管理三个Helm Chart,而无需在每个环境中的每个部署中修改每个YAML。
我们使用Helm的另一个优势是,如果出现问题,可以通过Helm回滚很容易地回滚到以前的版本:
- helm rollback <RELEASE> [REVISION] [flags]
如果要回滚到之前的先前版本,可以使用:
- helm rollback <RELEASE> 0
因此,我们将看到类似以下内容的内容:
- $ helm upgrade — install — wait — timeout 20 demo demo/
- $ helm upgrade — install — wait — timeout 20 — set
- readinessPath=/fail demo demo/$ helm rollback — wait — timeout 20 demo 1Rollback was a success.
Helm Chart 历史很好地跟踪了它:
- $ helm history demo
- REVISION STATUS DESCRIPTION
- 1 SUPERSEDED Install complete
- 2 SUPERSEDED Upgrade “demo” failed: timed out waiting for the condition
- 3 DEPLOYED Rollback to 1
除了Helm之外,还可以使用Google的Kustomize,它是一种流行的替代方法。
3. 按特定顺序部署事物
应用程序应该不会崩溃,因为依赖项尚未就绪。 在传统开发中,启动应用程序时,启动和停止任务有特定的顺序。 重要的是不要将这种思想带入容器编排中。 使用Kubernetes,Docker等,这些组件可以同时启动,因此无法定义启动顺序。 即使在应用程序启动并运行时,其依赖关系也可能失败或迁移,从而导致进一步的问题。 Kubernetes现实也充斥着无数潜在的通信故障,这些故障无法达到依赖关系,在此期间,pod可能崩溃或服务可能不可用。 网络延迟,例如信号微弱或网络连接中断,是导致通信失败的常见原因。
为简单起见,让我们研究一个假设的购物应用程序,该应用程序具有两项服务:库存数据库和店面用户界面。 在启动应用程序之前,后端服务必须启动,满足其所有检查并开始运行。 然后,前端服务可以启动,通过检查并开始运行。
假设我们已经使用kubectl wait命令强制执行了部署命令,例如:
- kubectl wait — for=condition=Ready pod/serviceA
但是,如果从不满足条件,则无法进行下一次部署,并且过程会中断。
这是部署顺序的简单流程:
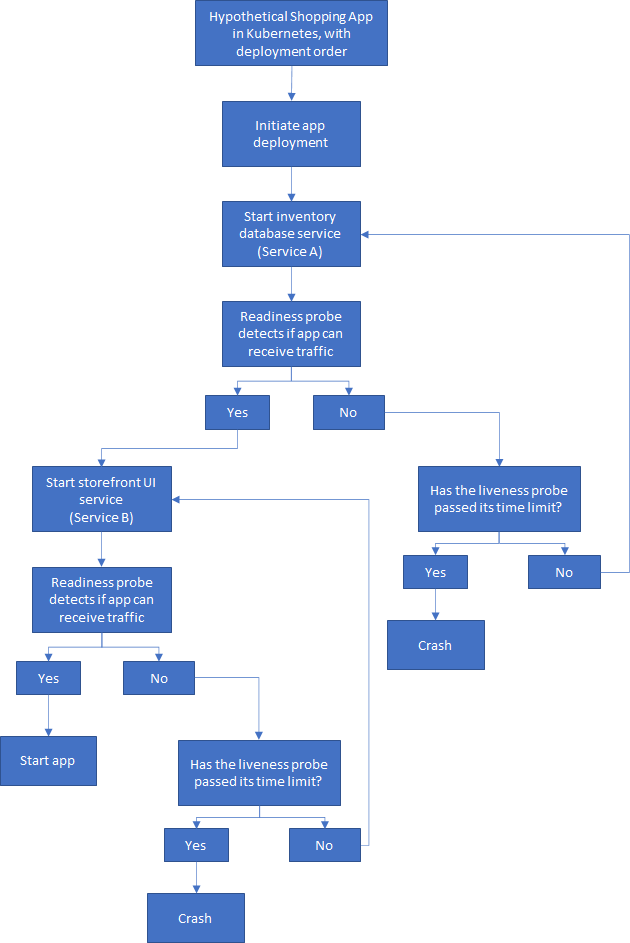
> This process cannot move forward until the previous step is complete
由于Kubernetes具有自我修复功能。 标准方法是让应用程序中的所有服务同时启动,并使容器崩溃并重新启动,直到它们全部启动并运行。 我让服务A和B独立启动(就像一个解耦的无状态云原生应用程序一样),但是出于用户体验的考虑,也许我可以告诉UI(服务B)显示漂亮的加载消息,直到服务A被 准备就绪,但是服务B的实际启动不应受到服务A的影响。
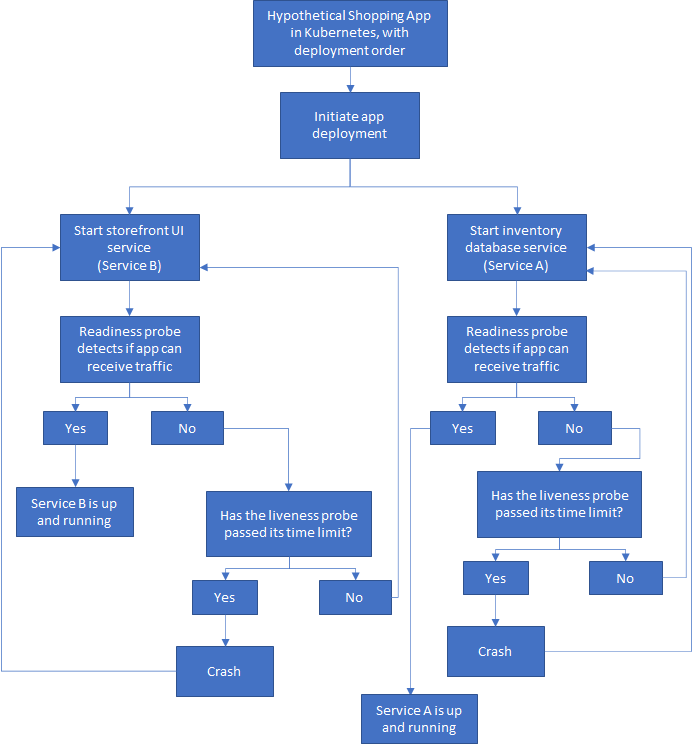
> Now when the pod crashes, Kubernetes restarts the service until everything is up and running. If y
当然,我们需要做的不仅仅是单纯依靠自我修复。 我们需要实施解决故障的解决方案,这些故障是不可避免的并会发生。 我们应该预料到它们会发生,并制定框架进行响应,以帮助我们避免停机和/或数据丢失。
在我的假设购物应用程序中,我的店面UI(服务B)需要库存(服务A)以便为用户提供完整的体验。 因此,如果出现部分故障,例如服务A短时间内不可用或崩溃等,系统仍应能够从问题中恢复。
像这样的瞬态故障是一种经常出现的可能性,因此,为了将其影响降至最低,我们可以实施重试模式。 重试模式可通过以下策略帮助提高应用程序的稳定性:
- 取消如果故障不是暂时性的,或者如果反复尝试该过程不太可能成功,则应用程序应取消该操作并报告异常,例如身份验证失败。 无效的凭证永远不会起作用!
- 重试如果故障是异常或罕见的,则可能是由于异常情况(例如,网络数据包损坏)引起的。 应用程序应立即重试该请求,因为不太可能再次发生相同的故障。
- 延迟后重试如果故障是由于常见情况(例如连接性或繁忙故障)引起的,那么最好先清除所有工作积压或流量,然后再重试。 该应用程序应等待,然后重试该请求。
- 您还可以使用指数退避来实现重试模式(以指数方式增加等待时间并设置最大重试次数)。
在创建弹性微服务应用程序时,实现断路模式也是重要的策略。 就像您家中的断路器将如何自动切换以保护您免受过大电流或短路造成的广泛损害一样,断路器模式为您提供了一种编写应用程序的方法,同时可以限制可能需要较长时间才能解决的意外故障的影响。 修复,例如部分失去连接性或服务完全失败。 在无法重试的情况下,应用程序应该能够接受失败的发生并做出相应的响应。
4. 部署没有设置内存和/或CPU限制的pod
资源分配取决于服务,并且在不测试实现的情况下很难预测容器可能需要哪些资源才能获得最佳性能。 一种服务可能需要固定的CPU和内存使用情况配置文件,而另一种服务的使用情况配置文件可能是动态的。
如果在未仔细考虑内存和CPU限制的情况下部署Pod,可能会导致资源争用和不稳定的环境。 如果容器没有内存或CPU限制,那么调度程序会将其内存利用率(和CPU利用率)视为零,因此可以在任何节点上调度无限数量的Pod。 这可能导致资源过量使用,并可能导致节点崩溃和kubelet崩溃。
如果未为容器指定内存限制,则可能有两种情况(这些情况也适用于CPU):
- 容器可以使用的内存量没有上限。 因此,容器可以使用其节点上的所有可用内存,可能会调用OOM(内存不足)杀手。 没有资源限制的容器发生OOM销毁情况的可能性更大。
- 命名空间(容器在其中运行)的默认内存限制已分配给容器。 群集管理员可以使用LimitRange指定内存限制的默认值。
声明群集中容器的内存和CPU限制,可以有效利用群集节点上的可用资源。 这有助于kube-scheduler确定Pod应该驻留在哪个节点上,以实现最有效的硬件利用率。
在设置容器的内存和CPU限制时,应注意不要请求超出限制的资源。 对于具有多个容器的容器,聚合资源请求不得超过设置的限制-否则,将永远不会调度容器。

> The resource request must not exceed the limit
将内存和CPU请求设置为低于其限制可以完成两件事:
- Pod在可用时可以使用内存/ CPU,从而导致活动大量爆发。
- 在突发期间,Pod仅限于合理数量的内存/ CPU。
最佳实践是将CPU请求保持在一个内核或以下,然后使用ReplicaSets进行扩展,从而提高了系统的灵活性和可靠性。
当您在同一集群中部署容器时,如果有不同的团队竞争资源,会发生什么情况? 如果该进程超出内存限制,则它将终止,而如果超过CPU限制,则将限制该进程(导致更差的性能)。
您可以通过名称空间设置中的资源配额和LimitRange控制资源限制。 这些设置有助于解决无限制或资源需求高的容器部署问题。
设置硬资源限制可能不是满足您需求的最佳选择。 另一个选择是在Vertical Pod自动缩放器资源中使用推荐模式。
5. 在生产中将"Latest"标签拉到容器中
使用Latest标签被认为是不良做法,尤其是在生产中。 由于各种原因,pod意外崩溃,因此它们可以随时下拉镜像。 不幸的是,在确定构建何时中断时,最新标签的描述性不是很高。 正在运行哪个版本的镜像? 上次工作是什么时候? 这在生产中尤其不利,因为您需要能够以最少的停机时间使事情恢复并运行。
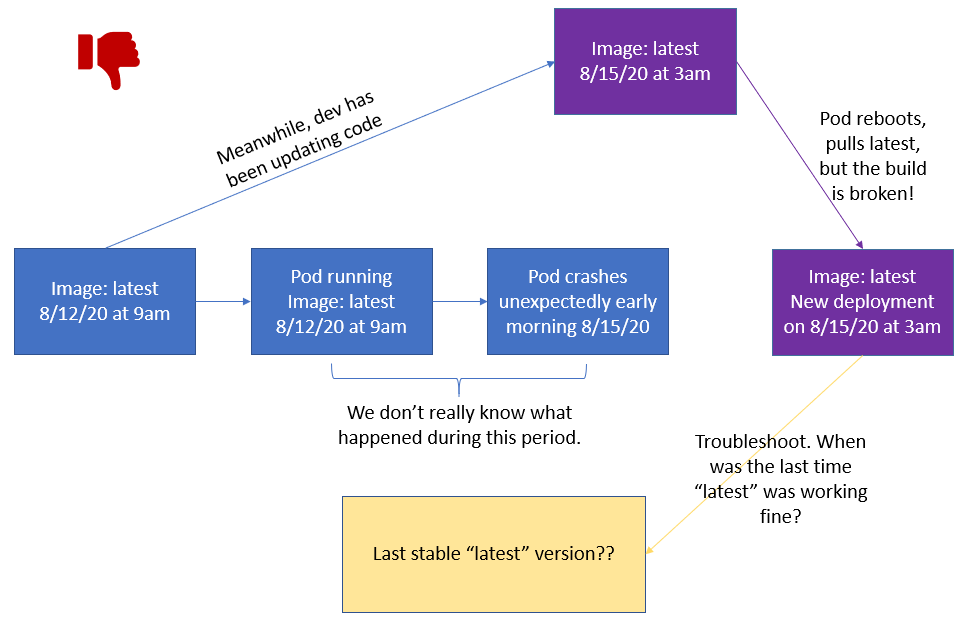
> You shouldn't use the latest tag in production.
默认情况下,imagePullPolicy设置为"Always",并且在重新启动图像时始终将其下拉。 如果您不指定标签,Kubernetes将默认为最新。 但是,只有在发生崩溃(当pod在重启时拉下映像)或更改部署pod的模板(.spec.template)时,才会更新部署。 请参阅此论坛讨论,以获取最新的示例在开发中无法正常工作。
即使您将imagePullPolicy更改为Always之外的其他值,如果需要重新启动(无论是由于崩溃还是故意重新启动),您的pod仍会拉取镜像。 如果使用版本控制并使用有意义的标记(例如v1.4.0)设置imagePullPolicy,则可以回滚到最新的稳定版本,并更容易地解决代码中何时何处出了问题。 您可以在语义版本规范和GCP最佳实践中阅读有关版本最佳实践的更多信息。
除了使用特定且有意义的Docker标签外,您还应该记住容器是无状态且不可变的。 它们也应该是短暂的(您应该将任何数据存储在容器外部的持久存储中)。 一旦启动了容器,就不应对其进行修改:没有补丁,没有更新,没有配置更改。 当需要更新配置时,应使用更新的配置部署新容器。
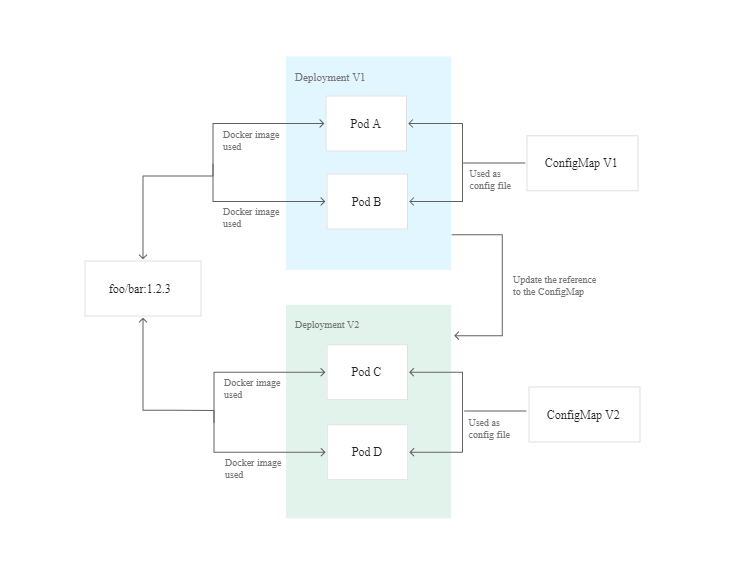
> Docker immutability, taken from Best Practices for Operating Containers.
这种不变性可以实现更安全,可重复的部署。 如果您需要重新部署旧映像,也可以更轻松地回滚。 通过使Docker映像和容器保持不变,您可以在每个单独的环境中部署相同的容器映像。 请参阅反模式1,以了解有关外部化配置数据以保持映像不变的信息。
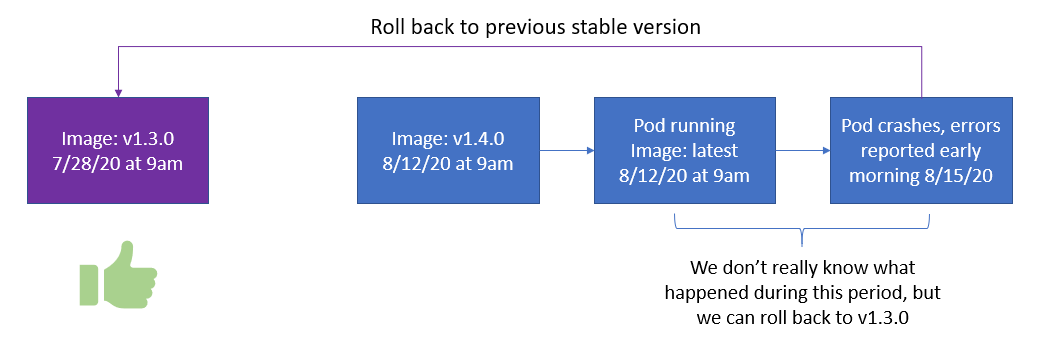
> We can roll back to the previous stable version while we troubleshoot.
6. 通过杀死Pod来部署新的更新/修复程序,以便它们在重启过程中提取新的Docker镜像
就像依靠最新标签来获取更新一样,依靠杀死Pod来推出新更新也是一种坏习惯,因为您不对代码进行版本控制。 如果您要杀死吊舱以在生产环境中提取更新的Docker映像,请不要这样做。 一旦将某个版本发布到生产环境中,就永远不能覆盖它。 如果出现问题,那么您将不知道哪里出问题或何时出问题,以及在进行故障排除时需要回滚代码的时间。
另一个问题是,重启容器以提取新的Docker镜像并不总是可行。 "只有且仅当更改了部署的Pod模板(即.spec.template)(例如,模板的标签或容器映像已更新)时,才会触发部署的推出。 其他更新,例如扩展部署,不会触发部署。"
您必须修改.spec.template才能触发部署。
更新您的Pod以提取新Docker映像的正确方法是对代码进行版本化(或增加修订/补丁),然后修改部署规范以反映有意义的标签(不是最新的,请参阅反模式5),以进一步讨论。 ,但类似于v1.4.0(针对新版本)或v1.4.1(针对补丁)。 然后Kubernetes将以零停机时间触发升级。
- Kubernetes使用新映像启动一个新容器。
- 等待健康检查通过。
- 删除旧的Pod。
7. 在同一集群中混合生产和非生产工作负载
Kubernetes支持名称空间功能,该功能使用户可以管理同一物理群集中的不同环境(虚拟群集)。 命名空间可视为在单个物理群集上管理不同环境的一种经济高效的方式。 例如,您可以在同一群集中运行暂存和生产环境,从而节省资源和金钱。 但是,在开发中运行Kubernetes与在生产中运行Kubernetes之间有很大的差距。
在同一集群上混合生产和非生产工作负载时,需要考虑很多因素。 例如,您必须考虑资源限制,以确保生产环境的性能不受影响(一种常见的做法是,在生产名称空间上不设置配额,在任何非生产名称空间上都设置配额。 )。
您还需要考虑隔离。 与生产环境相比,开发人员需要更多的访问权限和许可,您可能希望将它们尽可能地锁定。 虽然名称空间彼此隐藏,但默认情况下它们并未完全隔离。 这意味着开发人员命名空间中的应用程序可以在测试,登台或生产中调用应用程序(反之亦然),这不是一个好习惯。 当然,您可以使用NetworkPolicies设置规则以隔离名称空间。
但是,彻底测试资源限制,性能,安全性和可靠性非常耗时,因此不建议在与非生产工作负载相同的群集中运行生产工作负载。 与其将生产和非生产工作负载混合在同一个集群中,不如将单独的集群用于开发/测试/生产-这样您将获得更好的隔离和安全性。 对于CI / CD和升级,还应该尽可能地自动化,以减少人为错误的可能性。 您的生产环境需要尽可能牢固。
8. 不使用蓝绿部署或金丝雀部署关键任务
许多现代应用程序都有频繁的部署,范围从一个月内的几次更改到一天之内的多次部署。 微服务体系结构肯定可以实现这一点,因为只要它们能够协同工作以无缝执行,就可以在不同的周期上开发,管理和发布不同的组件。 当然,在推出更新时,保持应用程序全天候24/7显然很重要。
Kubernetes的默认滚动更新并不总是足够的。 执行更新的常见策略是使用默认的Kubernetes滚动更新功能:
- .spec.strategy.type==RollingUpdate
您可以在其中设置maxUnavailable(可用Pod的百分比或数量)和maxSurge字段(可选)来控制滚动更新过程。 如果实施得当,则滚动更新允许在Pod进行增量更新时以零停机时间进行逐步更新。 这是一个团队如何通过滚动更新以零停机时间更新其应用程序的示例。
但是,一旦将部署更新为下一个版本,就很难总是回去。 您应该有一个计划,将其回滚以防生产中断。 当您的Pod更新到下一个版本时,部署将创建一个新的ReplicaSet。 虽然Kubernetes将存储以前的ReplicaSets(默认情况下为10个,但是您可以使用spec.revisionHistoryLimit进行更改)。 副本集以诸如app6ff34b8374之类的名称随机存储,并且在部署应用程序YAML中找不到对副本集的引用。 您可以通过以下方式找到它:
- ReplicaSet.metadata.annotation
并使用以下命令检查修订:
- kubectl get replicaset app-6ff88c4474 -o yaml
查找修订号。 这很复杂,因为除非您在YAML资源中留下注释,否则发布历史记录不会保留日志(您可以使用— record标志来完成此操作:
- $kubectl rollout history deployment/appREVISION CHANGE-CAUSE1 kubectl create — filename=deployment.yaml — record=true
- 2 kubectl apply — filename=deployment.yaml — record=true
当您有数十个,数百个甚至数千个部署同时进行更新时,很难一次跟踪所有更新。 而且,如果您存储的修订全部包含相同的回归,那么您的生产环境将不会处于良好状态! 您可以在本文中详细了解有关使用滚动更新的信息。
其他一些问题是:
- 并非所有的应用程序都能够同时运行多个版本。
- 您的群集在更新中间可能会耗尽资源,这可能会中断整个过程。
这些都是在生产环境中遇到的非常令人沮丧和压力大的问题。
更可靠地更新部署的替代方法包括:
蓝绿(红黑)部署使用蓝色/绿色,同时存在完整的旧实例和新实例。 蓝色是活动版本,新版本已部署到绿色副本。 当绿色环境通过其测试和验证后,负载平衡器将流量切换到绿色,绿色即为蓝色环境,而旧版本则变为绿色。 由于我们维护了两个完整版本,因此执行回滚很简单-您需要做的就是切换回负载平衡器。
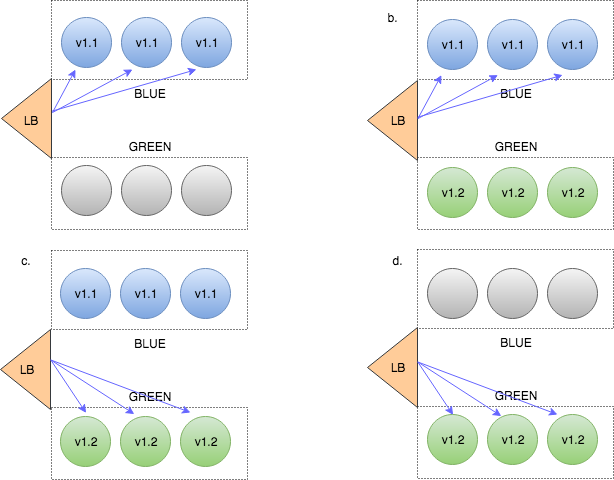
> The load balancer flips between blue and green to set the active version. From Continuous Deployme
其他优点包括:
- 由于我们从未直接部署到生产环境,因此当我们将绿色更改为蓝色时,压力非常小。
- 流量重定向会立即发生,因此不会造成停机。
- 可以进行大量测试以反映切换之前的实际生产。 (如前所述,开发环境与生产环境非常不同。)
Kubernetes不包括蓝色/绿色部署作为其本机工具之一。 在本教程中,您可以阅读有关如何在您的CI / CD自动化中实现蓝色/绿色的更多信息。
Canary版本Canary版本使我们能够在影响整个生产系统/用户群之前测试潜在问题并满足关键指标。 我们通过直接部署到生产环境(但仅部署到一小部分用户)来"进行生产测试"。 您可以选择基于百分比或由区域/用户位置,客户端类型和计费属性决定的路由。 即使部署到较小的子集,也必须仔细监视应用程序性能并衡量错误,这些指标也很重要-这些指标定义了质量阈值。 如果应用程序的行为符合预期,我们将开始传输更多的新版本实例以支持更多流量。
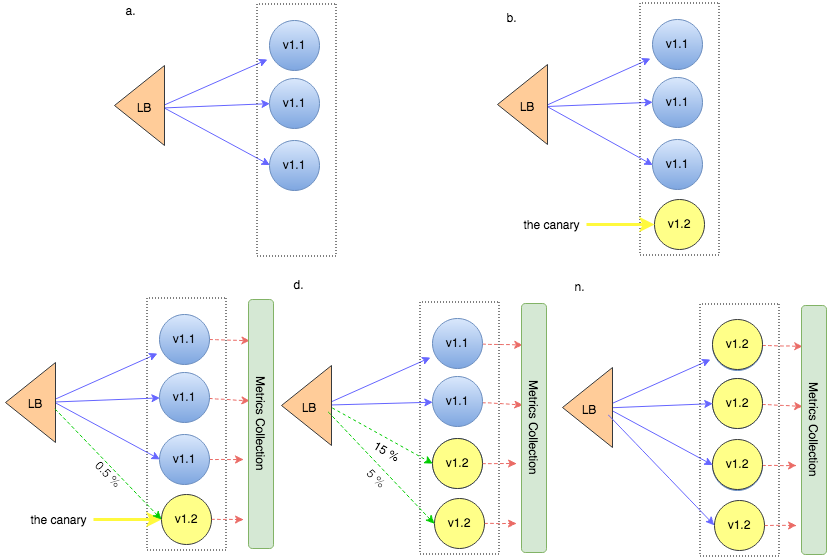
> The load balancer gradually releases the new version into production. From Continuous Deployment S
其他优点包括:
- 可观察性
- 测试生产流量的能力(很难获得真正的类似于生产的开发经验)
- 能够向一小部分用户发布版本,并在大版本发布之前获得实际反馈
- 快速失败。 由于我们直接将其部署到生产中,因此如果发生中断,我们可能会快速失败(即立即还原),并且它只会影响一部分,而不会影响整个社区。
9. 没有适当的指标来了解部署是否成功
您的健康检查需要应用程序支持。
您可以利用Kubernetes完成容器编排中的许多任务:
- 控制应用程序或团队的资源消耗(命名空间,CPU /内存,限制),以阻止应用程序消耗过多的资源
- 跨不同应用程序实例进行负载平衡,如果资源不足或主机死机,则将应用程序实例从一台主机移至另一台主机
- 自我修复—如果容器崩溃,则重新启动
- 如果将新主机添加到群集,则自动利用其他资源
- 和更多
因此,有时很容易忘记指标和监控。 但是,成功的部署并不是您的操作工作的终点。 最好积极主动,为意外的意外做好准备。 还有更多的层要监视,而K8s的动态特性使其很难进行故障排除。 例如,如果您没有密切关注可用资源,则pod的自动重新安排可能会导致容量问题,并且您的应用可能会崩溃或永远不会部署。 这在生产中尤其不幸,因为除非有人提交错误报告或您碰巧对其进行检查,否则您将不会知道。
监视面临着一系列挑战:需要监视很多层次,并且需要"在工程师身上保持相当低的维护负担"。 当运行在Kubernetes上的应用遇到问题时,有很多日志,数据和组件需要研究,尤其是当涉及到多个微服务时,与传统的单片架构相比,该问题将所有内容输出到一些日志中。
对应用程序行为的见解(例如应用程序的性能)可帮助您不断改进。 您还需要对容器,pod,服务和整个集群有一个整体的了解。 如果您可以确定应用程序如何使用其资源,则可以使用Kubernetes更好地检测和消除瓶颈。 要全面了解该应用程序,您需要使用诸如Prometheus,Grafana,New Relic或Cisco AppDynamics等应用程序性能监视解决方案。
无论您是否决定使用监视解决方案,这些都是Kubernetes文档建议您密切跟踪的关键指标:
- 运行Pod及其部署
- 资源指标:CPU,内存使用率,磁盘I / O
- 容器原生指标
- 应用指标
10. 云供应商锁定:将自己锁定在IaaS提供商的Kubernetes或无服务器计算服务中
锁定有多种类型(如果您想了解更多信息,Martin Fowler会写一篇很棒的文章),但是供应商锁定否定了部署到云的主要价值:容器灵活性。 的确,选择合适的云提供商并非易事。 每个提供商都有其自己的接口,开放的API以及专有的规范和标准。 此外,一个提供商可能比其他提供商更适合您的需求,仅是因为您的业务需求发生了意外变化。
幸运的是,容器与平台无关且可移植,并且所有主要的提供商都具有与云无关的Kubernetes基础。 当您需要在云之间移动工作负载时,您不必重新架构或重写应用程序代码,因此您不必将自己锁定在云提供商中,因为您无法"提升和转移"。
以下是您应考虑采取的措施,以确保可以灵活地防止或最小化供应商锁定。
(1) 首先,房间整理:请阅读细则
谈判进入和退出策略。 许多供应商都使启动变得容易,并且很容易上瘾。 这可能包括免费试用或赠金之类的激励措施,但是随着您扩大规模,这些费用可能会迅速增加。
检查是否有自动续订,提早终止费用之类的内容,以及提供商在迁移到另一家供应商以及与退出相关的SLA时是否会帮助进行转换等方面的工作。
(2) 设计/设计您的应用程序,使其可以在任何云上运行
如果您已经在为云开发并使用云原生原理,那么您的应用程序代码很可能应该易于提升和转移。 围绕代码的事情可能将您锁定在云供应商中。 例如,您可以:
- 检查应用程序使用的服务和功能(例如数据库,API等)是否可移植。
- 检查您的部署和配置脚本是否特定于云。 某些云具有自己的本机或推荐的自动化工具,这些工具可能无法轻松转换为其他提供商。 有许多工具可用于协助云基础架构自动化,并且与许多主要云提供商兼容,例如Puppet,Ansible和Chef。 该博客有一个方便的图表,比较了常用工具的特性。
- 检查您的DevOps环境(通常包括Git和CI / CD)是否可以在任何云中运行。 例如,许多云具有自己特定的CI / CD工具,例如IBM Cloud Continuous Delivery,Azure CI / CD或AWS Pipelines,这可能需要额外的工作才能移植到另一个云供应商。 取而代之的是,您可以使用Codefresh之类的完整CI / CD解决方案,这些解决方案对Docker和Kubernetes具有强大的支持,并与许多其他流行工具集成。 还有许多其他解决方案,例如CI或CD,或两者都有,例如GitLab,Bamboo,Jenkins,Travis等。
- 检查是否需要在提供商之间更改测试过程。
(3) 您还可以选择遵循多云策略
借助多云策略,您可以从不同的云提供商中挑选和选择最适合您希望交付的应用程序类型的服务。 在计划多云部署时,应仔细考虑互操作性。
摘要
Kubernetes确实很受欢迎,但是很难上手,而且传统开发中有很多实践都无法转化为云原生开发。
在本文中,我们研究了:
- 将配置文件放在Docker映像的内部/旁边:将您的配置数据外部化。 您可以使用ConfigMap和Secrets或类似的东西。
- 不使用Helm或其他类型的模板:使用Helm或Kustomize可以简化您的容器编排并减少人为错误。
- 按照特定的顺序部署事物:应用程序不应崩溃,因为依赖项尚未就绪。 利用Kubernetes的自我修复机制并实现重试和断路器。
- 在没有设置内存和/或CPU限制的情况下部署Pod:您应该考虑设置内存和CPU限制以减少资源争用的风险,尤其是在与其他人共享群集时。
- 在生产中将Latest标签拉到容器中:切勿使用最新标签。 始终使用有意义的内容(例如v1.4.0 /根据语义版本规范),并使用不可变的Docker映像。
- 通过杀死Pod来部署新的更新/补丁,以便它们在重新启动过程中提取新的Docker映像:对代码进行版本控制,以便更好地管理发布。
- 在同一群集中混合生产和非生产工作负载:如果可以,在单独的群集中运行生产和非生产工作负载。 这样可以减少资源争用和环境意外过渡对生产环境造成的风险。
- 不对任务关键型部署使用蓝绿或金丝雀部署(Kubernetes的默认滚动更新并不总是足够):您应该考虑使用蓝绿部署或金丝雀版本,以减轻生产中的压力并获得更有意义的生产结果。
- 没有适当的指标来了解部署是否成功(您的运行状况检查需要应用程序支持):您应该确保监视部署,以免发生任何意外情况。 您可以使用Prometheus,Grafana,New Relic或Cisco AppDynamics之类的工具来帮助您更好地了解部署情况。
- 云供应商锁定:将自己锁定在IaaS提供商的Kubernetes或无服务器计算服务中:您的业务需求可能随时发生变化。 您不应无意间将自己锁定在云提供商中,因为您可以轻松地提升和转移云原生应用程序。
谢谢阅读!


















