前言
为了能够实时地了解线上业务数据,京东算法智能应用部打造了一款基于ClickHouse的实时计算分析引擎,给业务团队提供实时数据支持,并通过预警功能发现潜在的问题。
本文结合了引擎开发过程中对资源位数据进行聚合计算业务场景,对数据实时聚合计算实现秒级查询的技术方案进行概述。ClickHouse是整个引擎的基础,故下文首先介绍了ClickHouse的相关特性和适合的业务场景,以及最基础的表引擎MergeTree。接下来详细的讲述了技术方案,包括Kafka数据消费到数据写入、结合ClickHouse特性建表、完整的数据监控,以及从几十亿数据就偶现查询超时到几百亿数据也能秒级响应的优化过程。
ClickHouse
- ClickHouse是Yandex公司内部业务驱动产出的列式存储数据库。为了更好地帮助自身及用户分析网络流量,开发了ClickHouse用于在线流量分析,一步一步最终形成了现在的ClickHouse。在存储数据达到20万亿行的情况下,也能做到90%的查询能够在1秒内返回结果。
- ClickHouse能够实现实时聚合,一切查询都是动态、实时的,用户发起查询的那一刻起,整个过程需要能做到在一秒内完成并返回结果。ClickHouse的实时聚合能力和我们面对的业务场景非常符合。
- ClickHouse支持完整的DBMS。支持动态创建、修改或删除数据库、表和视图,可以动态查询、插入、修改或删除数据。
- ClickHouse采用列式存储,数据按列进行组织,属于同一列的数据会被保存在一起,这是后续实现秒级查询的基础。
列式存储能够减少数据扫描范围,数据按列组织,数据库可以直接获取查询字段的数据。而按行存逐行扫描,获取每行数据的所有字段,再从每一行数据中返回需要的字段,虽然只需要部分字段还是扫描了所有的字段,按列存储避免了多余的数据扫描。
另外列式存储压缩率高,数据在网络中传输更快,对网络带宽和磁盘IO的压力更小。
除了完整的DBMS、列式存储外,还支持在线实时查询、拥有完善的SQL支持和函数、拥有多样化的表引擎满足各类业务场景。
正因为ClickHouse的这些特性,在它适合的场景下能够实现动态、实时的秒级别查询。
适合的场景
读多于写。数据一次写入,多次查询,从各个角度对数据进行挖掘,发现数据的价值。
大宽表,读大量行聚合少量列。选择少量的维度列和指标列,对大宽表的数据做聚合计算,得出少量的结果集。
数据批量写入,不需要经常更新、删除。数据写入完成后,相关业务不要求经常对数据更新或删除,主要用于查询分析数据的价值。
ClickHouse适合用于商业智能领域,广泛应用于广告流量、App流量、物联网等众多领域。借助ClickHouse可以实时计算线上业务数据,如资源位的点击情况,以及并对各资源位进行bi预警。
MergeTree
MergeTree系列引擎是最基础的表引擎,提供了主键索引、数据分区等基本能力。了解这部分内容,是后续开发和优化的基础和方向。
分区
指定表数据分区方式,支持多个列,但单个列分区查询效果最好。有数据写入时属于同一分区的数据最终会被合并到同一个分区目录,不同分区的数据永远不会被合并在一起。结合业务场景设置合理的分区可以减少查询时数据文件的扫描范围。
排序
在一个数据片段内,数据以何种方式排序。当使用多个字段排序时ORDER BY(T1,T2),先按照T1排序,相同值再按照T2排序。
MergeTree存储结构
一张数据表的完整物理结构依次是数据表、分区以及各分区下具体的数据文件。分区下具体的数据文件包括一级索引、每列压缩文件、每列字段标记文件,了解他们的存储和查询原理,为后面建表、聚合计算的优化提供方向。
- 一级索引文件,存放稀疏索引,通过ORDER BY或PRIMARY KEY声明,使用少量的索引能够记录大量数据的区间位置信息,内容生成规则跟排序字段有关,且索引数据常驻内存,取用速度快。借助稀疏索引,可以排除主键范围外的数据文件,从而有效减少数据扫描范围,加速查询速度;
- 每列压缩数据文件,存储每一列的数据,每一列字段都有独立的数据文件;
- 每列字段标记文件,每一列都有对应的标记文件,保存了列压缩文件中数据的偏移量信息,与稀疏索引对齐,又与压缩文件对应,建立了稀疏索引与数据文件的映射关系。不能常驻内存,使用LRU缓存策略加快其取用速度。
在读取数据时,需通过标记数据的位置信息才能够找到所需要的数据,分为读取压缩数据块和读取数据块两个步骤。
掌握数据存储和查询的过程,后续建表和查询有理论支持。
1)数据写入
每批数据的写入,都会生成一个新的分区目录,后续会异步的将相同分区的目录进行合并。按照索引粒度,会分别生成一级索引文件、每个字段的标记和压缩数据文件。写入过程如下图:

2)查询过程
查询过程通过指定WHERE条件,不断缩小数据范围。借助分区能找到数据所在的数据块,一级索引查找具体的行数区间信息,从标记文件中获取数据压缩文件中的压缩文件信息。查询过程如下图:

查询语句如果没有匹配到任务索引,会扫描所有分区目录,这种操作给整个集群造成较大压力。
引用官方文档中的例子对查询过程进行说明。以(CounterID, Date) 为主键,排序好的索引的图示会是下面这样:

- 指定查询如下:
- CounterID in ('a', 'h'),服务器会读取标记号在[0, 3)和[6, 8) 区间中的数据。
- CounterID IN ('a', 'h') AND Date = 3,服务器会读取标记号在[1, 3)和[7, 8)区间中的数据。
- Date = 3,服务器会读取标记号在[1, 10]区间中的数据。
ClickHouse支持集群部署,在查询分布式表时,集群会将每个节点的数据进行合并,得到所有节点的数据后返回结果。MergeTree系列表引擎支持副本,如ReplicatedMergeTree表引擎建表存放明细数据,接下来介绍的两种表引擎都继承自MergeTree,但又有各自的特殊功能。
- ReplacingMergeTree实现数据去重
在建表时设置ORDER BY排序字段作为判断重复数据的唯一键,在合并分区的时候会触发删除重复数据,能够一定程度上解决数据重复的问题。
- AggregatingMergeTree
在合并分区的时候按照定义的条件聚合数据,将需要聚合的数据预先计算出来,在聚合查询时直接使用结果数据,以空间换时间的方法提高查询性能。该引擎需要使用AggregateFunction类型来处理所有列。
了解了ClickHouse相关内容后,接下来将介绍完整的技术方案。
技术方案及查询优化
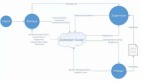
资源位的数据来源包括Kafka的实时数据和hdfs里面存储的离线数据。实时数据通过Flink实时任务写入ClickHouse,离线数据通过建立MapReduce定时任务写入ClickHouse。
架构图
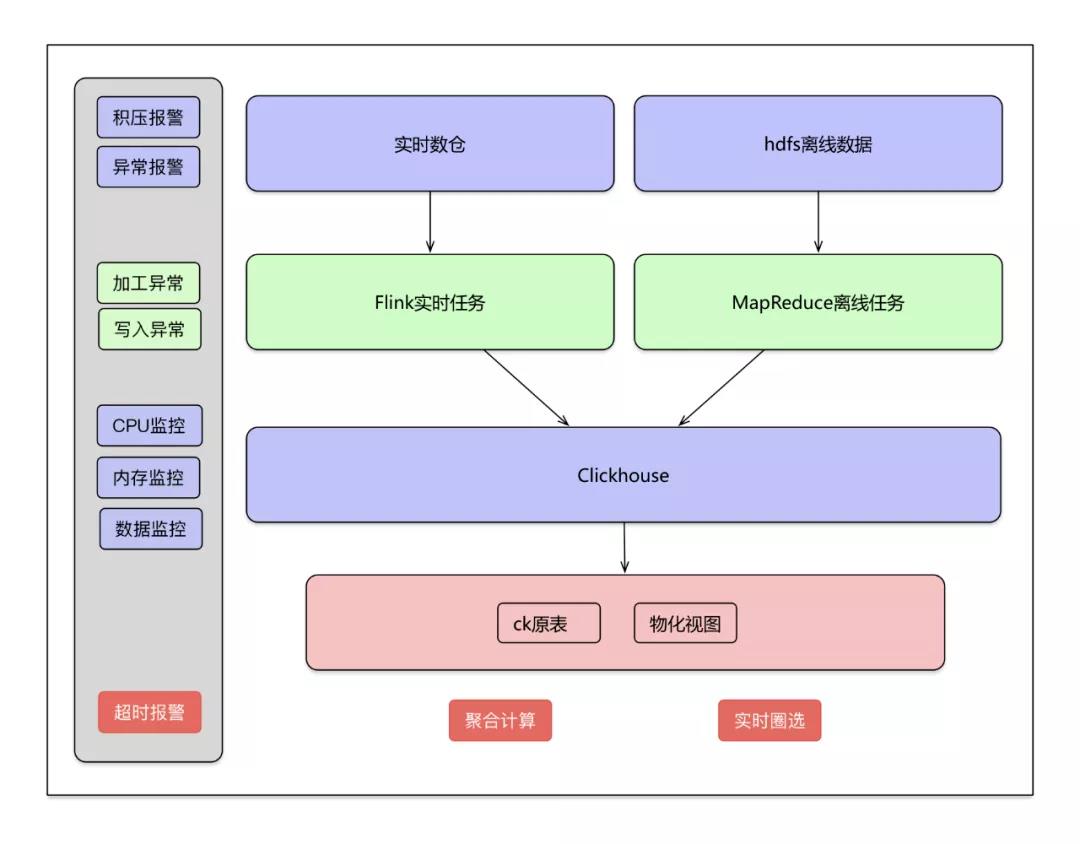
实时数据入库
实时数据从实时数据到写入CK过程:
- 各业务线产生的实时数据写入kafka通道,根据数据量分配不同的分区个数。
- 创建的flink任务对各个业务的kafka数据进行消费,每个业务处理过程会有所不同。一般包括过滤算子、数据加工算子、写入算子。
过滤算子,过滤掉不需要的数据,这个步骤非常重要,设置严格的数据评估标准,防止脏数据、不符合规则的数据写入集群。另外对脏数据的过滤要做好记录,在数据完整性测试过程中会用到。
数据加工算子,主要负责从实时数据流中解析出业务需要的数据,这个过程也要设置严格的校验逻辑,保证数据整洁;若涉及数据加工逻辑更新,要保证加工逻辑及时更新。
写入算子,采用批量写入方式,根据集群情况,设置合理的批次,实时查询和写入性能达到均衡。
写入ck过程可以通过域名连接分布式表,也可以通过nginx进程掌握一份集群机器IP列表,每个nginx进程自己轮询,均衡写入集群的每台机器,但需要保证写入ClickHouse的QPS不能太小,防止出现写入不均衡情况。
离线数据入库
- 离线数据建立定时任务,将hive表中的数据加工好,通过建立MapReduce定时任务,将加工后的数据写入ClickHouse。
- 离线数据入库过程同样包括过滤、数据加工、写入ClickHouse过程。
批量写入
在前面merge章节有介绍,每次数据写入都会产生临时分区目录,后续会异步的将相同分区的目录进行合并。写入过程会消耗集群的资源,所以一定采用批量写入方式,每批次写入条数看集群和数据情况(1万、5万、10万每批次可作为参考)。采用JDBC方式实现批量写入程序如下:
JDBC驱动,可以使用官方提供的驱动程序:
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.2.4</version>
</dependency>
- 1.
- 2.
- 3.
- 4.
- 5.
初始化Connection:
Class.forName(Ck.DRIVER);
Connection connection = DriverManager.getConnection(Ck.URL, Ck.USERNAME, Ck.PASSWORD);
connection.setAutoCommit(false);
- 1.
- 2.
- 3.
批量写入:
PreparedStatement state = null;
try {
state = connection.prepareStatement(INSERT_SQL);
for(控制写入批次)
{
state.set...(index, value);
state.addBatch();
}
state.executeBatch();
connection.commit();
}catch (SQLException e) {
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
建表
在开始建表前,对业务进行充分理解,了解集群数据的查询场景,在建表时规划好分区字段和排序规则,这个过程非常重要,是集群查询性能良好的基础。
例如我们面临的业务场景为,计算移动App每个点击按钮聚合PV和UV(需要去重),按天或者小时聚合计算,还有商品各种属性聚合计算的PV和UV。
选择分区字段。正如前面MergeTree章节介绍,ClickHouse支持分区,分区字段是每张表整个数据目录最外层结构,可以很大程度加快查询速度。
另外分区字段不易过多,分区过多就意味着数据目录更加复杂,在进行聚合计算时,肯定会影响整个集群的查询性能。目前我们遇到的业务场景,适合以时间字段(时分秒)来作为分区字段,toYYYYMMDD(ts)。
设置排序规则。数据会按照设置的排序字段先后顺序来进行存储,在进行聚合计算时也会按照聚合条件对相邻数据进行计算,但如果聚合条件不在排序字段里,集群会对当前分区的所有数据扫描一遍,这种查询就会慢很多,大量消耗集群的内存、CPU资源。我们应该避免这种情况出现,设置合理的排序规则才能以最快的速度聚合出我们想要的结果。
当前业务场景下,我们可以选择代表各个按钮的id和商品的属性作为排序字段。在进行聚合查询时,where条件下选择分区,排序规则卡出来需要的数据,能够很大程度提高查询速度。
所以在建表阶段就要充分了解未来的查询场景,选择合适的分区字段和排序规则。
另外,建表时候最重要的是选择合适的表引擎,每种表引擎的使命都不同,根据自身业务选择出最合适表引擎。当前业务场景我们可以选择ReplicatedMergeTree引擎存明细数据。
建表实例:
CREATE TABLE table_name
(
Event_ts DateTime,
T1 String,
T2 UInt32,
T3 String
) ENGINE = ReplicatedMergeTree('/clickhouse/ck.test/tables/{layer}-{shard}/table_name', '{replica}')
PARTITION BY toYYYYMM(Event_ts)
ORDER BY (T1, T2)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
进行到这里,完成了建表和数据写入,集群的查询速度一般还是可以的,在集群硬件还不差的情况下满足每次10几亿的数据的聚合查询没有问题,当然前提是是选择了分区和卡排序字段的基础上。
但数据再进一步多到百亿甚至近千亿数据,只是简单的设置分区和优化排序字段是很难做到实时秒级查询了。
查询优化
虽然在查询时卡了分区和排序条件,但随着存储的数据量增多,ClickHouse集群的查询压力会逐渐增加,出现查询速度慢情况。如果有大SQL请求发给了集群,会造成整个集群的CPU和内存升高,直到把整个集群内存打满,集群基本会处于瘫痪状态。对查询进行优化非常重要。
排查耗时SQL。耗时的SQL对整个集群造成很大的压力,要先找到解决耗时SQL的优化方案。当前业务场景下,能很容易发现聚合计算UV(去重)是比较消耗集群资源的。
对于聚合结果的场景,我们多次尝试优化方案后,通过建立物化视图,以空间换取时间,大部分聚合查询速度能提高10几倍。建立物化视图同样要先去了解业务场景,选择分区字段、ORDER BY字段,并选择count、sum、uniq等聚合函数。
物化视图建表语句:
CREATE MATERIALIZED VIEW test_db.app_hp_btn_event_test ON CLUSTER test_cluster ENGINE = ReplicatedAggregatingMergeTree( '/clickhouse/ck.test/tables/{layer}-{shard}/test_db/app_hp_btn_event_test', '{replica}') PARTITION BY toYYYYMMDD(time) ORDER BY(btn_id,cate2) TTL time + toIntervalDay(3) SETTINGS index_granularity = 8192
AS
SELECT
toStartOfHour(event_time) AS time,
btn_id,
countState(uid) PV,
uniqState(uid) AS UV
FROM
test_db.app_hp_btn_event_test
GROUP BY
btn_id,
toStartOfHour(event_time)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
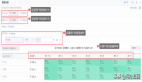
查询实例:
hour from test_db.app_hp_btn_event_test where toYYYYMMDD(time) = 20200608 group by hour
- 1.
避免明细数据join。ClickHouse更适合大宽表数据聚合查询,对于明细数据join的场景尽量避免出现。
集群硬件升级。软件的优化总是有限的,观察集群的CPU、内存、硬盘情况,集群的日常CPU、内存较高时,及时升级机器。
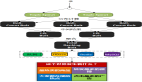
数据监控报警
完善的监控体系让我们及时得知引擎异常,同时也能时刻观测数据写入查询情况,掌握整个引擎的运行情况。
- 数据从消费到写入各个阶段异常信息。主要包括java.lang.NullPointerException、java.lang.ArrayIndexOutOfBoundsException等异常信息,大部分是因为数据源有所调整引起;
- 各个阶段添加报警功能,Kafka添加积压报警、核心算子计算逻辑添加异常报警、ck集群在mdc系统添加硬盘、cpu、内存预警;
- Grafana查询系统。主要包括CPU、内存、硬盘使用情况;
- 大SQL监控。查询耗时SQL和没有卡分区和排序字段的查询。
最后
ClickHouse自身有处理万亿数据的能力。在掌握了它的存储、查询、MergeTree原理后,创建符合业务要求的数据库表,执行符合ClickHouse特性的查询SQL,实现1000亿数据的秒级聚合查询并不是难事。
ClickHouse还有很多特性,需要在开发过程中不断地摸索和尝试。