前言
本文收录于专辑:http://dwz.win/HjK,点击解锁更多数据结构与算法的知识。
你好,我是彤哥。
上一节,我们一起学习了关于跳表的理论知识,相信通过上一节的学习,你一定可以给面试官完完整整地讲清楚跳表的来龙去脉,甚至能够边讲边画图。
然而,面试官说,既然你这么精通跳表,不如实现一个呗^^
我,我,实现就实现,谁怕谁,哼~~
本节,我将通过两种方式手写跳表,并结合画图,彻底搞定跳表实现的细节。
第一种方式为跳表的通用实现,第二种方式为彤哥自己发明的实现,并运用到HashMap的改写中。
好了,开始今天的学习吧,Let's Go!
文末有跳表和红黑树实现的HashMap的对比,不想看代码的同学也可以直达底部。
通用实现
通用实现主要参考JDK中的ConcurrentSkipListMap,在其基础上,简化,并优化一些东西,学好通用实现也有助于理解JDK中的ConcurrentSkipListMap的源码。
数据结构
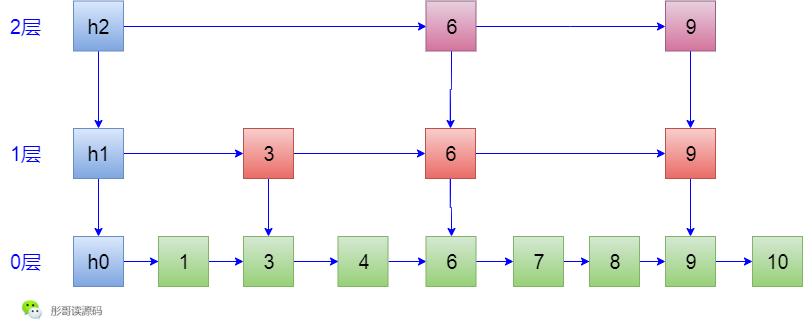
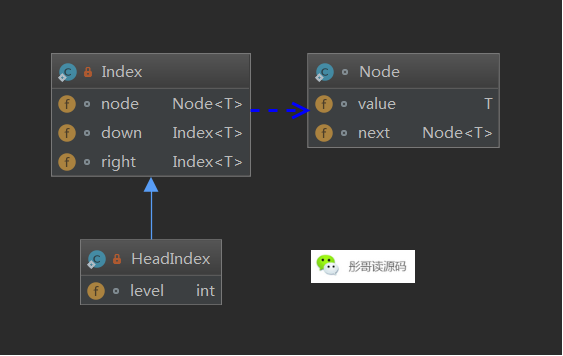
首先,我们要定义好实现跳表的数据结构,在通用实现中,将跳表的数据结构分成三种:
- 普通节点,处于0层的节点,存储数据,典型的单链表结构,包括h0
- 索引节点,包含着对普通节点的引用,同时增加向右、向下的指针
- 头索引节点,继承自索引节点,同时,增加所在的层级
类图大概是这样:
OK,给出代码如下:
友情提示:代码太长,请横屏观赏~~
- /**
- * 头节点:标记层
- * @param <T>
- */
- private static class HeadIndex<T> extends Index<T> {
- // 层级
- int level;
- public HeadIndex(Node<T> node, Index<T> down, Index<T> right, int level) {
- super(node, down, right);
- this.level = level;
- }
- }
- /**
- * 索引节点:引用着真实节点
- * @param <T>
- */
- private static class Index<T> {
- // 真实节点
- Node<T> node;
- // 下指针(第一层的索引实际上是没有下指针的)
- Index<T> down;
- // 右指针
- Index<T> right;
- public Index(Node<T> node, Index<T> down, Index<T> right) {
- this.node = node;
- this.down = down;
- this.right = right;
- }
- }
- /**
- * 链表中的节点:真正存数据的节点
- * @param <T>
- */
- static class Node<T> {
- // 节点元素值
- T value;
- // 下一个节点
- Node<T> next;
- public Node(T value, Node<T> next) {
- this.value = value;
- this.next = next;
- }
- @Override
- public String toString() {
- return (value==null?"h0":value.toString()) +"->" + (next==null?"null":next.toString());
- }
- }
查找元素
查找元素,是通过头节点,先尽最大努力往右,再往下,再往右,每一层都要尽最大努力往右,直到右边的索引比目标值大为止,到达0层的时候再按照链表的方式来遍历,用图来表示如下:
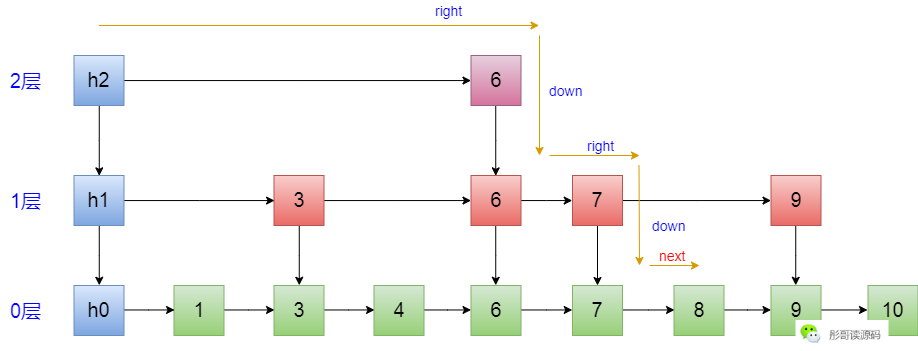
所以,整个过程分成两大步:
- 寻找目标节点前面最接近的索引对应的节点;
- 按链表的方式往后遍历;
请注意这里的指针,在索引中叫作right,在链表中叫作next,是不一样的。
这样一分析代码实现起来就比较清晰了:
- /**
- * 查找元素
- * 先找到前置索引节点,再往后查找
- * @param value
- * @return
- */
- public T get(T value) {
- System.out.println("查询元素:\u6b22\u8fce\u5173\u6ce8\u516c\u4f17\u53f7\u5f64\u54e5\u8bfb\u6e90\u7801\uff0c\u83b7\u53d6\u66f4\u591a\u67b6\u6784\u3001\u57fa\u7840\u3001\u6e90\u7801\u597d\u6587\uff01");
- if (value == null) {
- throw new NullPointerException();
- }
- Comparator<T> cmp = this.comparator;
- // 第一大步:先找到前置的索引节点
- Node<T> preIndexNode = findPreIndexNode(value, true);
- // 如果要查找的值正好是索引节点
- if (preIndexNode.value != null && cmp.compare(preIndexNode.value, value) == 0) {
- return value;
- }
- // 第二大步:再按链表的方式查找
- Node<T> q;
- Node<T> n;
- int c;
- for (q = preIndexNode;;) {
- n = q.next;
- c = cmp.compare(n.value, value);
- // 找到了
- if (c == 0) {
- return value;
- }
- // 没找到
- if (c > 0) {
- return null;
- }
- // 看看下一个
- q = n;
- }
- }
- /**
- *
- * @param value 要查找的值
- * @param contain 是否包含value的索引
- * @return
- */
- private Node<T> findPreIndexNode(T value, boolean contain) {
- /*
- * q---->r---->r
- * | |
- * | |
- * v v
- * d d
- * q = query
- * r = right
- * d = down
- */
- // 从头节点开始查找,规律是先往右再往下,再往右再往下
- Index<T> q = this.head;
- Index<T> r, d;
- Comparator<T> cmp = this.comparator;
- for(;;) {
- r = q.right;
- if (r != null) {
- // 包含value的索引,正好有
- if (contain && cmp.compare(r.node.value, value) == 0) {
- return r.node;
- }
- // 如果右边的节点比value小,则右移
- if (cmp.compare(r.node.value, value) < 0) {
- q = r;
- continue;
- }
- }
- d = q.down;
- // 如果下面的索引为空了,则返回该节点
- if (d == null) {
- return q.node;
- }
- // 否则,下移
- q = d;
- }
- }
添加元素
添加元素,相对来说要复杂得多。
首先,添加一个元素时,要先找到这个元素应该插入的位置,并将其添加到链表中;
然后,考虑建立索引,如果需要建立索引,又分成两步:一步是建立竖线(down),一步是建立横线(right);
怎么说呢?以下面这个图为例,现在要插入元素6,且需要建立三层索引:

首先,找到6的位置,走过的路径为 h1->3->3->4,发现应该插入到4和7之间,插入之:

然后,建立竖线,即向下的指针,一共有三层,因为超过了当前最高层级,所以,头节点也要相应地往上增加一层,如下:
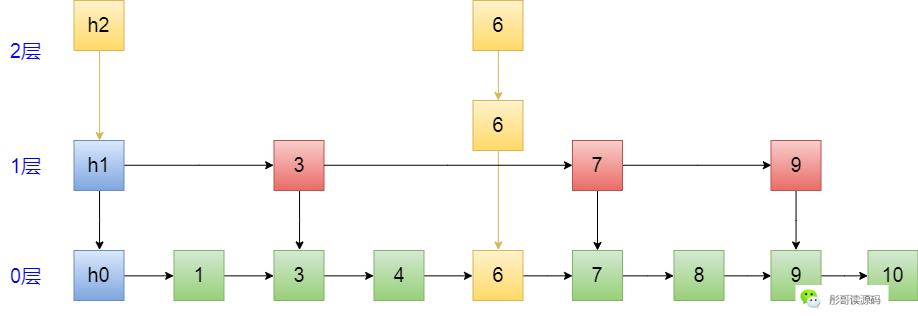
此时,横向的指针是一个都没动的。
最后,修正横向的指针,即 h2->6、3->6、6->7,修正完成则表示插入元素成功:
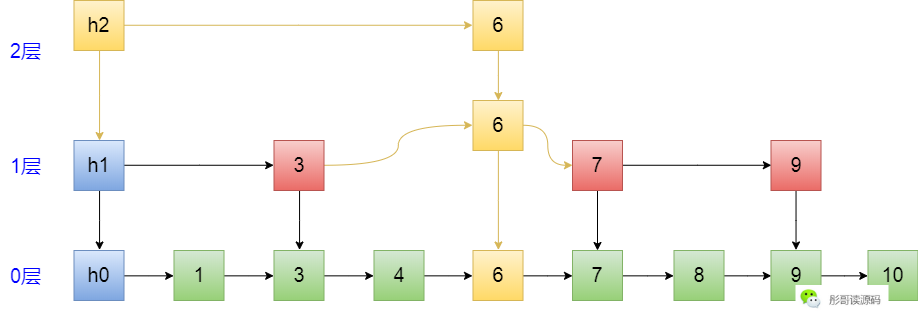
这就是插入元素的整个过程,Show You the Code:
- /**
- * 添加元素
- * 不能添加相同的元素
- * @param value
- */
- public void add(T value) {
- System.out.println("添加元素:\u6b22\u8fce\u5173\u6ce8\u516c\u4f17\u53f7\u5f64\u54e5\u8bfb\u6e90\u7801\uff0c\u83b7\u53d6\u66f4\u591a\u67b6\u6784\u3001\u57fa\u7840\u3001\u6e90\u7801\u597d\u6587\uff01");
- if (value == null) {
- throw new NullPointerException();
- }
- Comparator<T> cmp = this.comparator;
- // 第一步:先找到前置的索引节点
- Node<T> preIndexNode = findPreIndexNode(value, true);
- if (preIndexNode.value != null && cmp.compare(preIndexNode.value, value) == 0) {
- return;
- }
- // 第二步:加入到链表中
- Node<T> q, n, t;
- int c;
- for (q = preIndexNode;;) {
- n = q.next;
- if (n == null) {
- c = 1;
- } else {
- c = cmp.compare(n.value, value);
- if (c == 0) {
- return;
- }
- }
- if (c > 0) {
- // 插入链表节点
- q.next = t = new Node<>(value, n);
- break;
- }
- q = n;
- }
- // 决定索引层数,每次最多只能比最大层数高1
- int random = ThreadLocalRandom.current().nextInt();
- // 倒数第一位是0的才建索引
- if ((random & 1) == 0) {
- int level = 1;
- // 从倒数第二位开始连续的1
- while (((random >>>= 1) & 1) != 0) {
- level++;
- }
- HeadIndex<T> oldHead = this.head;
- int maxLevel = oldHead.level;
- Index<T> idx = null;
- // 如果小于或等于最大层数,则不用再额外建head索引
- if (level <= maxLevel) {
- // 第三步1:先连好竖线
- for (int i = 1; i <= level; i++) {
- idx = new Index<>(t, idx, null);
- }
- } else {
- // 大于了最大层数,则最多比最大层数多1
- level = maxLevel + 1;
- // 第三步2:先连好竖线
- for (int i = 1; i <= level; i++) {
- idx = new Index<>(t, idx, null);
- }
- // 新建head索引,并连好新head到最高node的线
- HeadIndex<T> newHead = new HeadIndex<>(oldHead.node, oldHead, idx, level);
- this.head = newHead;
- idx = idx.down;
- }
- // 第四步:再连横线,从旧head开始再走一遍遍历
- Index<T> qx, r, d;
- int currentLevel;
- for (qx = oldHead, currentLevel=oldHead.level;qx != null;) {
- r = qx.right;
- if (r != null) {
- // 如果右边的节点比value小,则右移
- if (cmp.compare(r.node.value, value) < 0) {
- qx = r;
- continue;
- }
- }
- // 如果目标层级比当前层级小,直接下移
- if (level < currentLevel) {
- qx = qx.down;
- } else {
- // 右边到尽头了,连上
- idx.right = r;
- qx.right = idx;
- qx = qx.down;
- idx = idx.down;
- }
- currentLevel--;
- }
- }
- }
删除元素
经过了上面的插入元素的全过程,删除元素相对来说要容易了不少。
同样地,首先,找到要删除的元素,从链表中删除。
然后,修正向右的索引,修正了向右的索引,向下的索引就不用管了,相当于从整个跳表中把向下的那一坨都删除了,等着垃圾回收即可。
其实,上面两步可以合成一步,在寻找要删除的元素的同时,就可以把向右的索引修正了。
以下图为例,此时,要删除7这个元素:
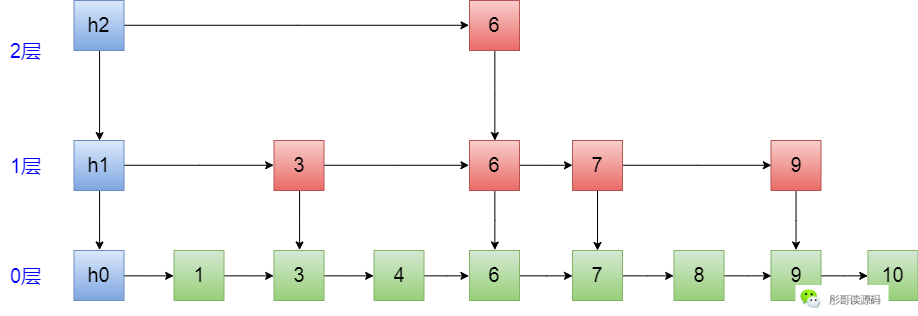
首先,寻找删除的元素的路径:h2->6->6,到这里的时候,正好看到右边有个7,把它干掉:
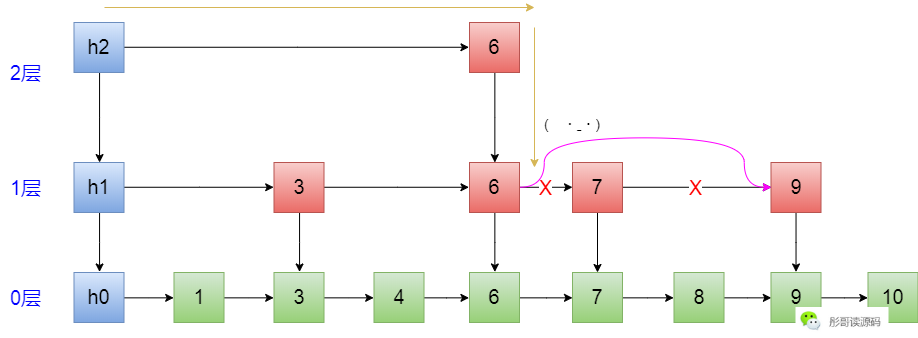
然后,继续往下,走到了绿色的6这里,再往后按链表的方式删除元素,这个大家都会了:
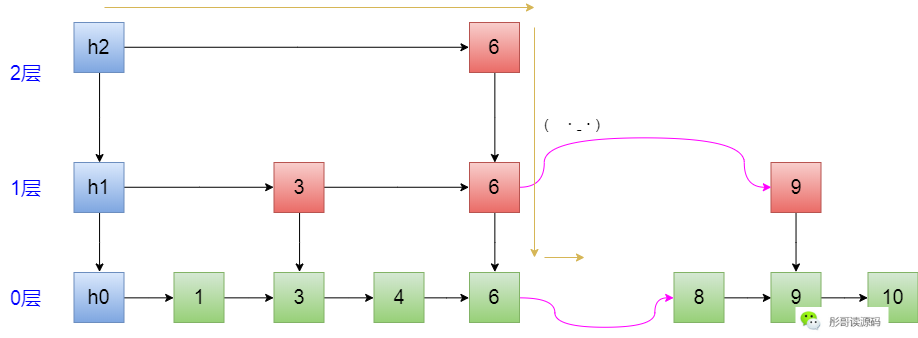
OK,给出删除元素的代码(查看完整代码,关注公众号彤哥读源码回复skiplist领取):
- /**
- * 删除元素
- * @param value
- */
- public void delete(T value) {
- System.out.println("删除元素:\u6b22\u8fce\u5173\u6ce8\u516c\u4f17\u53f7\u5f64\u54e5\u8bfb\u6e90\u7801\uff0c\u83b7\u53d6\u66f4\u591a\u67b6\u6784\u3001\u57fa\u7840\u3001\u6e90\u7801\u597d\u6587\uff01");
- if (value == null) {
- throw new NullPointerException();
- }
- Index<T> q = this.head;
- Index<T> r, d;
- Comparator<T> cmp = this.comparator;
- Node<T> preIndexNode;
- // 第一步:寻找元素
- for(;;) {
- r = q.right;
- if (r != null) {
- // 包含value的索引,正好有
- if (cmp.compare(r.node.value, value) == 0) {
- // 纠正:顺便修正向右的索引
- q.right = r.right;
- }
- // 如果右边的节点比value小,则右移
- if (cmp.compare(r.node.value, value) < 0) {
- q = r;
- continue;
- }
- }
- d = q.down;
- // 如果下面的索引为空了,则返回该节点
- if (d == null) {
- preIndexNode = q.node;
- break;
- }
- // 否则,下移
- q = d;
- }
- // 第二步:从链表中删除
- Node<T> p = preIndexNode;
- Node<T> n;
- int c;
- for (;;) {
- n = p.next;
- if (n == null) {
- return;
- }
- c = cmp.compare(n.value, value);
- if (c == 0) {
- // 找到了
- p.next = n.next;
- return;
- }
- if (c > 0) {
- // 没找到
- return;
- }
- // 后移
- p = n;
- }
- }
OK,到这里,跳表的通用实现就完事了,其实,你也可以发现,这里还是有一些可以优化的点的,比如right和next指针为什么不能合二为一呢?向下的指针能不能跟指向Node的指针合并呢?
关注公众号彤哥读源码,回复“skiplist”领取本节完整源码,包含测试代码。
为了尝试解决这些问题,彤哥又自己研究了一种实现,这种实现不再区分头索引节点、索引节点、普通节点,把它们全部合并成一个,大家都是一样的,并且,我将它运用到了HashMap的改造中,来看看吧。
彤哥独家实现
因为,正好要改造HashMap,所以,关于彤哥的独家实现,我会与HashMap的改造一起来讲解,新的HashMap,我们称之为SkiplistHashMap(前者),它不同于JDK中现有的ConcurrentSkipListMap(后者),前者是一个HashMap,时间复杂度为O(1),后者其实不是HashMap,它只是跳表实现的一种Map,时间复杂度为O(log n)。
另外,我将Skip和List两个单词合成一个了,这是为了后面造一个新单词——Skiplistify,跳表化,-ify词缀结尾,什么化,比如,treeify树化、heapify堆化。
好了,开始SkiplistHashMap的实现,Come On!
数据结构
让我们分析一下SkiplistHashMap,首先,它有一个数组,其次,出现冲突的时候先使用链表来存储冲突的节点,然后,达到一定的阈值时,将链表转换成跳表,所以,它至少需要以下两大种节点类型:
普通节点,单链表结构,存储key、value、hash、next等,结构简单,直接给出代码:
- /**
- * 链表节点,平凡无奇
- * @param <K>
- * @param <V>
- */
- static class Node<K extends Comparable<K>, V> {
- int hash;
- K key;
- V value;
- Node<K, V> next;
- public Node(int hash, K key, V value, Node<K, V> next) {
- this.hash = hash;
- this.key = key;
- this.value = value;
- this.next = next;
- }
- }
跳表节点,在通用实现中跳表节点分成了三大类:头索引节点、索引节点、普通节点,让我们仔细分析一下。
继续下面的内容,请先忘掉上面的三种节点,否则你是很难看懂的,trust me!
还是先拿一张图来对照着来:
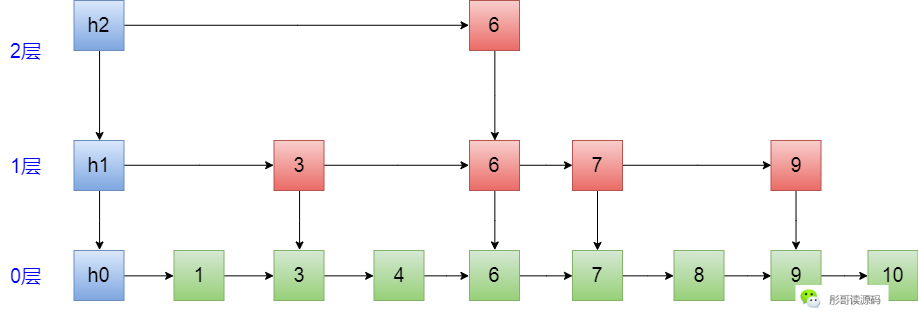
首先,我们把这张图压扁,是不是就只有一个一个的节点连成一条线了,也就是单链表结构:
- static class SkiplistNode<K extends Comparable<K>, V> {
- int hash;
- K key;
- V value;
- Node<K, V> next;
- }
然后,随便找一个节点,把它拉起来,比如3这个元素,首先,它有一个高度,这里它的高度为2,并且,每一层的这个3都有一个向右的指针(忘掉之前的三种节点类型),对不对,所以,这里把next废弃掉,变成nexts,记录每一层的这个3的下一个元素是谁:
- static class SkiplistNode<K extends Comparable<K>, V> {
- int hash;
- K key;
- V value;
- int maxLevel;
- Node<K, V>[] nexts;
- }
OK,不知道你理解了没有,我们试着按这种数据结构重画上面的图:
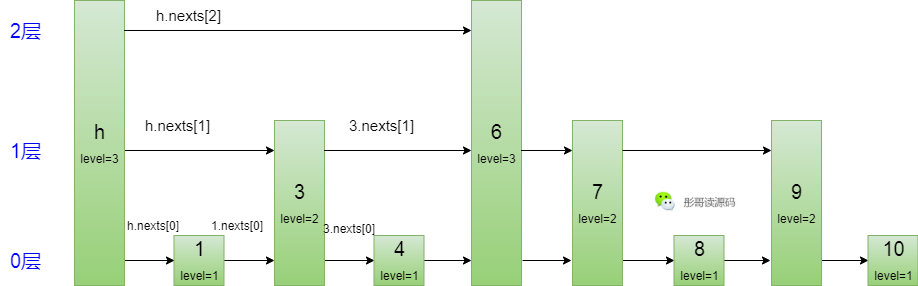
通过这种方式,就把上面三种类型的节点成功地变成了一个大节点,这个节点是有层高的,且每层都有一个向右的指针。
让我们模拟一下查找的过程,比如,要查询8这个元素,只需要从头节点的最高层,往右到6这个节点,6在2层向右为空了,所以转到1层,向右到7这个节点,7再向右看一下,是9,比8大,所以7向下到0层,再向右,找到8,所以,整个走过的路径为:h(2)->6(2)->6(1)->7(1)->7(0)->8(0)。
好了,原理讲完了,让我们看实现,先来个简单的。
跳表的查询元素
不再区分索引节点和普通节点后,一切都将变得简单,无脑向右,再向下,再向右即可,代码也变得非常简单。
- public V findValue(K key) {
- int level = this.maxLevel;
- SkiplistNode<K, V> q = this;
- int c;
- // i--控制向下
- for (int i = (level - 1); i >= 0; i--) {
- while (q.nexts[i] != null && (c = q.nexts[i].key.compareTo(key)) <= 0) {
- if (c == 0) {
- // 找到了返回
- return q.nexts[i].value;
- }
- // 控制向右
- q = q.nexts[i];
- }
- }
- return null;
- }
跳表的添加元素
添加元素,同样变得要简单很多,一切尽在注释中,不过,彤哥写这篇文章的时候才发现下面的代码中有个小bug,看看你能不能发现^^
- // 往跳表中添加一个元素(只有头节点可调用此方法)
- private V putValue(int hash, K key, V value) {
- // 1. 算出层数
- int level = randomLevel();
- // 2. 如果层数高出头节点层数,则增加头节点层数
- if (level > maxLevel) {
- level = ++maxLevel;
- SkiplistNode<K, V>[] oldNexts = this.nexts;
- SkiplistNode<K, V>[] newNexts = new SkiplistNode[level];
- for (int i = 0; i < oldNexts.length; i++) {
- newNexts[i] = oldNexts[i];
- }
- this.nexts = newNexts;
- }
- SkiplistNode<K, V> newNode = new SkiplistNode<>(hash, key, value, level);
- // 3. 修正向右的索引
- // 记录每一层最右能到达哪里,从头开始
- SkiplistNode<K, V> q = this; // 头
- int c;
- // 好好想想这个双层循环,先向右找到比新节点小的最大节点,修正之,再向下,再向右
- for (int i = (maxLevel - 1); i >= 0; i--) {
- while (q.nexts[i] != null && (c = q.nexts[i].key.compareTo(key)) <= 0) {
- if (c == 0) {
- V old = q.nexts[i].value;
- q.nexts[i].value = value;
- return old;
- }
- q = q.nexts[i];
- }
- if (i < level) {
- newNode.nexts[i] = q.nexts[i];
- q.nexts[i] = newNode;
- }
- }
- return null;
- }
- private int randomLevel() {
- int level = 1;
- int random = ThreadLocalRandom.current().nextInt();
- while (((random>>>=1) & 1) !=0) {
- level++;
- }
- return level;
- }
好了,关于SkiplistHashMap中跳表的部分我们就讲这么多,需要完整源码的同学可以关注个人公众号彤哥读源码,回复skiplist领取哈。
下面我们再来看看SkiplistHashMap中的查询元素和添加元素。
SkiplistHashMap查询元素
其实,跳表的部分搞定了,SkiplistHashMap的部分就非常简单了,直接上代码:
- public V get(K key) {
- int hash = hash(key);
- int i = (hash & (table.length - 1));
- Node<K, V> p = table[i];
- if (p == null) {
- return null;
- } else {
- if (p instanceof SkiplistNode) {
- return (V) ((SkiplistNode)p).findValue(key);
- } else {
- do {
- if (p.key.equals(key)) {
- return p.value;
- }
- } while ((p=p.next) != null);
- }
- }
- return null;
- }
SkiplistHashMap添加元素
添加元素参考HashMap的写法,将添加过程分成以下几种情况:
1.始化,先初始化;
2.数组对应位置无元素,直接放入;
3.数组对应位置有元素,又分成三种情况:
- 如果是SkipListNode类型,按跳表类型插入元素
- 如果该位置元素的key值正好与要插入的元素的key值相等,说明是重复元素,替换后直接返回
- 否则,按链表类型插入元素,且插入元素后判断是否要转换成跳表
4.插入元素后,判断是否需要扩容
上代码如下:
- /**
- * 添加元素:
- * 1. 未初始化,则初始化
- * 2. 数组位置无元素,直接放入
- * 3. 数组位置有元素:
- * 1)如果是SkipListNode类型,按跳表类型插入元素
- * 2)如果该位置元素的key值正好与要插入的元素的key值相等,说明是重复元素,替换后直接返回
- * 3)如果是Node类型,按链表类型插入元素,且插入元素后判断是否要转换成跳表
- * 4. 插入元素后,判断是否需要扩容
- *
- * @param key
- * @param value
- * @return
- */
- public V put(K key, V value) {
- if (key == null || value == null) {
- throw new NullPointerException();
- }
- int hash = hash(key);
- Node<K, V>[] table = this.table;
- if (table == null) {
- table = resize();
- }
- int len = table.length;
- int i = hash & (len - 1);
- Node<K, V> h = table[i];
- if (h == null) {
- table[i] = new Node<>(hash, key, value, null);
- } else {
- // 出现了hash冲突
- V old = null;
- if (h instanceof SkiplistNode) {
- old = (V) ((SkiplistNode)h).putValue(hash, key, value);
- } else {
- // 如果链表头节点正好等于要查找的元素
- if (h.hash == hash && h.key.equals(key)) {
- old = h.value;
- h.value = value;
- } else {
- // 遍历链表找到位置
- Node<K, V> q = h;
- Node<K, V> n;
- int binCount = 1;
- for(;;) {
- n = q.next;
- // 没找到元素
- if (n == null) {
- q.next = new Node<>(hash, key, value, null);
- if (++binCount>= SKIPLISTIFY_THRESHOLD) {
- skiplistify(table, hash);
- }
- break;
- }
- // 找到了元素
- if (n.hash == hash && n.key.equals(key)) {
- old = n.value;
- n.value = value;
- break;
- }
- // 后移
- q = n;
- ++binCount;
- }
- }
- }
- if (old != null) {
- return old;
- }
- }
- // 需要扩容了
- if (++size > threshold) {
- resize();
- }
- return null;
- }
这里有一个跳表化的过程,我使用的是最简单的方式实现的,即新建一个跳表头节点,然后把元素都put进去:
- // 跳表化
- private void skiplistify(Node<K, V>[] table, int hash) {
- if (table == null || table.length < MIN_SKIPLISTIFY_CAPACITY) {
- resize();
- } else {
- SkiplistNode<K, V> head = new SkiplistNode<>(0, null, null, 1);
- int i = hash & (table.length-1);
- Node<K, V> p = table[i];
- do {
- head.putValue(p.hash, p.key, p.value);
- } while ((p=p.next) != null);
- table[i] = head;
- }
- }
好了,关于跳表实现的HashMap我们就介绍完了。
最后一个问题
不管从原理还是实现过程,跳表都要比红黑树要简单不少,为什么JDK中不使用跳表而是使用红黑树来实现HashMap呢?
其实这个问题挺不好回答的,我在给自己挖坑,我简单从以下几个方面分析一下:
- 稳定度,跳表的随机性太大了,要实现O(log n)的时间复杂度,随机算法要做得很好才行,这方面可以对比看看ConcurrentSkipListMap和redis中zset的实现,而红黑树还算比较稳定;
- 范围查找,HashMap更多地是运用在查找单个元素,并没有范围查找这种需求,所以,使用跳表的必要性不大;
- 成熟度,红黑树是经过很多实践检验的,比如linux内核、epoll等,而跳表很少,目前已知的好像只有redis的zset使用了跳表;
- 空间占用,红黑树不管层高多少,每个节点稳定增加左右两个指针和颜色字段,而跳表不一样,随着层高的不断增加,每个元素需要增加的指针也会增加很多,比如,最高为16层,则head和最高的节点需要维护16个向右的指针,这个空间占用是很大的,所以,实现跳表一般也要指定最高只能达到多少层;
- 流程化,跳表实现可以多种多样,每个人写出来的跳表可能都不一样,但红黑树不一样,流程固化,每个人写出来的差异性不大;
- 可测试性,跳表很难测试,因为多次运行的结果肯定不一样,而红黑树不一样,只要元素顺序不变,运行的结果肯定是固定的,可测试性好很多;
目前,差不多只能想到这么多,你有想到的也可以告诉我。
后记
本节,我们一起用两种方式实现了跳表,并将其运用到了HashMap的改写中,相信通过本节的学习你一定可以自信地告诉面试官我可以手写跳表了。
本文转载自微信公众号「彤哥读源码」,可以通过以下二维码关注。转载本文请联系彤哥读源码公众号。