本文转载自微信公众号「Java中文社群」,作者磊哥 。转载本文请联系Java中文社群公众号。
URL 去重在我们日常工作中和面试中很常遇到,比如这些:
可以看出,包括阿里,网易云、优酷、作业帮等知名互联网公司都出现过类似的面试题,而且和 URL 去重比较类似的,如 IP 黑/白名单判断等也经常出现在我们的工作中,所以我们本文就来“盘一盘”URL 去重的问题。
URL 去重思路
在不考虑业务场景和数据量的情况下,我们可以使用以下方案来实现 URL 的重复判断:
- 使用 Java 的 Set 集合,根据添加时的结果来判断 URL 是否重复(添加成功表示 URL 不重复);
- 使用 Redis 中的 Set 集合,根据添加时的结果来判断 URL 是否重复;
- 将 URL 都存储在数据库中,再通过 SQL 语句判断是否有重复的 URL;
- 把数据库中的 URL 一列设置为唯一索引,根据添加时的结果来判断 URL 是否重复;
- 使用 Guava 的布隆过滤器来实现 URL 判重;
- 使用 Redis 的布隆过滤器来实现 URL 判重。
以上方案的具体实现如下。
URL 去重实现方案
1.使用 Java 的 Set 集合判重
Set 集合天生具备不可重复性,使用它只能存储值不相同的元素,如果值相同添加就会失败,因此我们可以通过添加 Set 集合时的结果来判定 URL 是否重复,实现代码如下:
- public class URLRepeat {
- // 待去重 URL
- public static final String[] URLS = {
- "www.apigo.cn",
- "www.baidu.com",
- "www.apigo.cn"
- };
- public static void main(String[] args) {
- Set<String> set = new HashSet();
- for (int i = 0; i < URLS.length; i++) {
- String url = URLS[i];
- boolean result = set.add(url);
- if (!result) {
- // 重复的 URL
- System.out.println("URL 已存在了:" + url);
- }
- }
- }
- }
程序的执行结果为:
URL 已存在了:www.apigo.cn
从上述结果可以看出,使用 Set 集合可以实现 URL 的判重功能。
2.Redis Set 集合去重
使用 Redis 的 Set 集合的实现思路和 Java 中的 Set 集合思想思路是一致的,都是利用 Set 的不可重复性实现的,我们先使用 Redis 的客户端 redis-cli 来实现一下 URL 判重的示例:
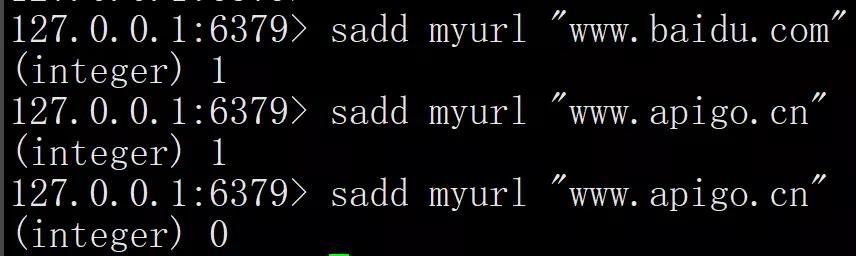
从上述结果可以看出,当添加成功时表示 URL 没有重复,但添加失败时(结果为 0)表示此 URL 已经存在了。
我们再用代码的方式来实现一下 Redis 的 Set 去重,实现代码如下:
- // 待去重 URL
- public static final String[] URLS = {
- "www.apigo.cn",
- "www.baidu.com",
- "www.apigo.cn"
- };
- @Autowired
- RedisTemplate redisTemplate;
- @RequestMapping("/url")
- public void urlRepeat() {
- for (int i = 0; i < URLS.length; i++) {
- String url = URLS[i];
- Long result = redisTemplate.opsForSet().add("urlrepeat", url);
- if (result == 0) {
- // 重复的 URL
- System.out.println("URL 已存在了:" + url);
- }
- }
- }
以上程序的执行结果为:
URL 已存在了:www.apigo.cn
以上代码中我们借助了 Spring Data 中的 RedisTemplate 实现的,在 Spring Boot 项目中要使用 RedisTemplate 对象我们需要先引入 spring-boot-starter-data-redis 框架,配置信息如下:
- <!-- 添加操作 RedisTemplate 引用 -->
- <dependency>
- <groupId>org.springframework.boot</groupId>
- <artifactId>spring-boot-starter-data-redis</artifactId>
- </dependency>
然后需要再项目中配置 Redis 的连接信息,在 application.properties 中配置如下内容:
- spring.redis.host=127.0.0.1
- spring.redis.port=6379
- #spring.redis.password=123456 # Redis 服务器密码,有密码的话需要配置此项
经过以上两个步骤之后,我们就可以在 Spring Boot 的项目中正常的使用RedisTemplate 对象来操作 Redis 了。
3.数据库去重
我们也可以借助数据库实现 URL 的重复判断,首先我们先来设计一张 URL 的存储表,如下图所示:

此表对应的 SQL 如下:
- /*==============================================================*/
- /* Table: urlinfo */
- /*==============================================================*/
- create table urlinfo
- (
- id int not null auto_increment,
- url varchar(1000),
- ctime date,
- del boolean,
- primary key (id)
- );
- /*==============================================================*/
- /* Index: Index_url */
- /*==============================================================*/
- create index Index_url on urlinfo
- (
- url
- );
其中 id 为自增的主键,而 url 字段设置为索引,设置索引可以加快查询的速度。
我们先在数据库中添加两条测试数据,如下图所示:
我们使用 SQL 语句查询,如下图所示:
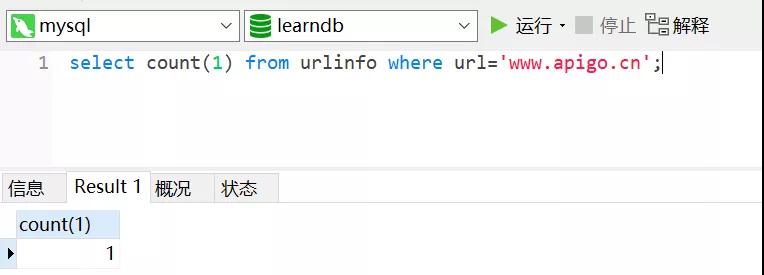
如果结果大于 0 则表明已经有重复的 URL 了,否则表示没有重复的 URL。
4.唯一索引去重
我们也可以使用数据库的唯一索引来防止 URL 重复,它的实现思路和前面 Set 集合的思想思路非常像。
首先我们先为字段 URL 设置了唯一索引,然后再添加 URL 数据,如果能添加成功则表明 URL 不重复,反之则表示重复。
创建唯一索引的 SQL 实现如下:
- create unique index Index_url on urlinfo
- (
- url
- );
5.Guava 布隆过滤器去重
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器的核心实现是一个超大的位数组和几个哈希函数,假设位数组的长度为 m,哈希函数的个数为 k。
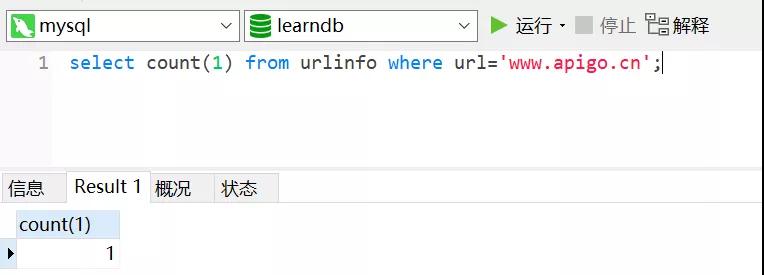
以上图为例,具体的操作流程:假设集合里面有 3 个元素 {x, y, z},哈希函数的个数为 3。首先将位数组进行初始化,将里面每个位都设置位 0。对于集合里面的每一个元素,将元素依次通过 3 个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为 1,查询 W 元素是否存在集合中的时候,同样的方法将 W 通过哈希映射到位数组上的 3 个点。如果 3 个点的其中有一个点不为 1,则可以判断该元素一定不存在集合中。反之,如果 3 个点都为 1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为 4、5、6 这 3 个点。虽然这 3 个点都为 1,但是很明显这 3 个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是 1,这是误判率存在的原因。
我们可以借助 Google 提供的 Guava 框架来操作布隆过滤器,实现我们先在 pom.xml 中添加 Guava 的引用,配置如下:
- <!-- 添加 Guava 框架 -->
- <!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
- <dependency>
- <groupId>com.google.guava</groupId>
- <artifactId>guava</artifactId>
- <version>28.2-jre</version>
- </dependency>
URL 判重的实现代码:
- public class URLRepeat {
- // 待去重 URL
- public static final String[] URLS = {
- "www.apigo.cn",
- "www.baidu.com",
- "www.apigo.cn"
- };
- public static void main(String[] args) {
- // 创建一个布隆过滤器
- BloomFilter<String> filter = BloomFilter.create(
- Funnels.stringFunnel(Charset.defaultCharset()),
- 10, // 期望处理的元素数量
- 0.01); // 期望的误报概率
- for (int i = 0; i < URLS.length; i++) {
- String url = URLS[i];
- if (filter.mightContain(url)) {
- // 用重复的 URL
- System.out.println("URL 已存在了:" + url);
- } else {
- // 将 URL 存储在布隆过滤器中
- filter.put(url);
- }
- }
- }
- }
以上程序的执行结果为:
URL 已存在了:www.apigo.cn
6.Redis 布隆过滤器去重
除了 Guava 的布隆过滤器,我们还可以使用 Redis 的布隆过滤器来实现 URL 判重。在使用之前,我们先要确保 Redis 服务器版本大于 4.0(此版本以上才支持布隆过滤器),并且开启了 Redis 布隆过滤器功能才能正常使用。
以 Docker 为例,我们来演示一下 Redis 布隆过滤器安装和开启,首先下载 Redis 的布隆过器,然后再在重启 Redis 服务时开启布隆过滤器,如下图所示:
布隆过滤器使用布隆过滤器正常开启之后,我们先用 Redis 的客户端 redis-cli 来实现一下布隆过滤器 URL 判重了,实现命令如下:
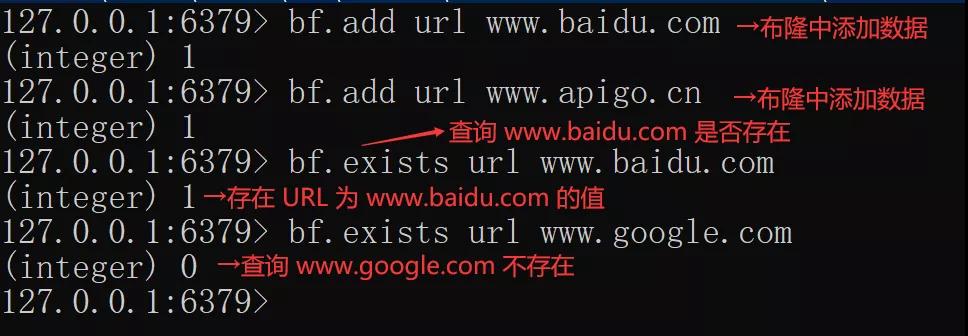
在 Redis 中,布隆过滤器的操作命令不多,主要包含以下几个:
- bf.add 添加元素;
- bf.exists 判断某个元素是否存在;
- bf.madd 添加多个元素;
- bf.mexists 判断多个元素是否存在;
- bf.reserve 设置布隆过滤器的准确率。
接下来我们使用代码来演示一下 Redis 布隆过滤器的使用:
- import redis.clients.jedis.Jedis;
- import utils.JedisUtils;
- import java.util.Arrays;
- public class BloomExample {
- // 布隆过滤器 key
- private static final String _KEY = "URLREPEAT_KEY";
- // 待去重 URL
- public static final String[] URLS = {
- "www.apigo.cn",
- "www.baidu.com",
- "www.apigo.cn"
- };
- public static void main(String[] args) {
- Jedis jedis = JedisUtils.getJedis();
- for (int i = 0; i < URLS.length; i++) {
- String url = URLS[i];
- boolean exists = bfExists(jedis, _KEY, url);
- if (exists) {
- // 重复的 URL
- System.out.println("URL 已存在了:" + url);
- } else {
- bfAdd(jedis, _KEY, url);
- }
- }
- }
- /**
- * 添加元素
- * @param jedis Redis 客户端
- * @param key key
- * @param value value
- * @return boolean
- */
- public static boolean bfAdd(Jedis jedis, String key, String value) {
- String luaStr = "return redis.call('bf.add', KEYS[1], KEYS[2])";
- Object result = jedis.eval(luaStr, Arrays.asList(key, value),
- Arrays.asList());
- if (result.equals(1L)) {
- return true;
- }
- return false;
- }
- /**
- * 查询元素是否存在
- * @param jedis Redis 客户端
- * @param key key
- * @param value value
- * @return boolean
- */
- public static boolean bfExists(Jedis jedis, String key, String value) {
- String luaStr = "return redis.call('bf.exists', KEYS[1], KEYS[2])";
- Object result = jedis.eval(luaStr, Arrays.asList(key, value),
- Arrays.asList());
- if (result.equals(1L)) {
- return true;
- }
- return false;
- }
- }
以上程序的执行结果为:
URL 已存在了:www.apigo.cn
总结
本文介绍了 6 种 URL 去重的方案,其中 Redis Set、Redis 布隆过滤器、数据库和唯一索引这 4 种解决方案适用于分布式系统,如果是海量的分布式系统,建议使用 Redis 布隆过滤器来实现 URL 去重,如果是单机海量数据推荐使用 Guava 的布隆器来实现 URL 去重。