随着语言模型越来越强大,用于特定任务的数据和度量标准越来越成为训练和评估的瓶颈。例如,摘要模型通常被训练用来预测人类参考摘要,并使用 ROUGE 进行评估,但是这些度量指标都没有触及真正的关注点——摘要质量。
近日,OpenAI 的一项研究表明,人们可以通过训练模型来优化人类偏好,进而显著提升摘要质量。具体而言,研究者收集了一个人类摘要比较的大型、高质量数据集,训练了一种模型来预测人类偏好的摘要,并使用该模型作为奖励函数通过强化学习来微调摘要策略。

论文链接:https://arxiv.org/pdf/2009.01325.pdf
项目地址:https://github.com/openai/summarize-from-feedback
研究者将该方法应用于 Reddit 帖子的摘要生成,结果显示该研究的模型显著优于人类参考摘要,以及仅通过监督学习进行微调的更大规模的模型。
研究中的模型还可以迁移至 CNN/DM 新闻文章,在不进行任何特定新闻微调的情况下生成几乎和人类参考摘要一样好的结果。
最后,研究者进行了扩展分析,以理解人类反馈数据集和微调模型。该研究确保奖励模型能够泛化到新数据集上,并且优化奖励模型的结果要比根据人类要求优化的 ROUGE 更佳。
该研究的主要贡献有:
研究表明,在英文摘要生成上,基于人类反馈的训练显著优于强大的基准训练;
人类反馈模型相较于监督模型能够更好地泛化到新的领域;
对其策略和奖励模型进行了扩展实验分析。
接下来详细解读 OpenAI 采用的研究方法以及相应的实验细节和结果。
方法与实验细节
高阶方法
研究者采用的方法适用于批处理设置。从一个初始策略开始,该策略通过对所需数据集(以 Reddit TL;DR 摘要数据集为示例)的监督学习进行微调。整个过程(如下图 2 所示)由可以迭代重复的三个步骤组成:
基于现有策略中收集样本,并将比较结果发送给人类;
从人类比较中学习奖励模型;
针对奖励模型优化策略。
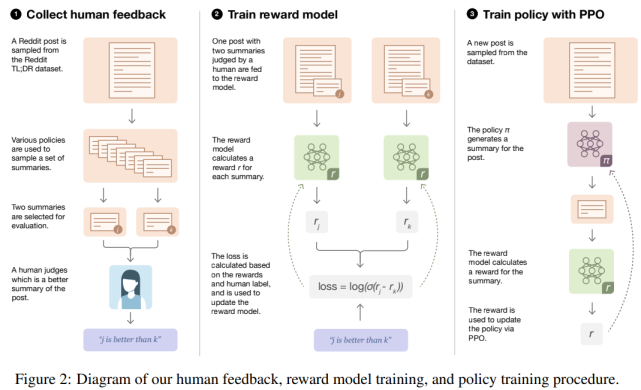
人类反馈、奖励模型训练和策略训练整体流程图。
数据集和任务
研究者使用 TL;DR 摘要数据集,它包含来自 reddit.com 上涉及各种主题(subreddit)约 300 万个帖子,以及原始发帖人(TL; DR)撰写的帖子摘要。
此外,研究者还对该数据集进行了过滤(请参阅附录 A)以确保数据集质量,包括使用一般人群可以理解的 subreddit 白名单。
研究者将 ground-truth 任务定义为生成一个模型,其中该模型生成长度少于 48 个 token 且尽可能好的摘要。此外,判断摘要质量的标准是:摘要如何忠实地将原文传达给一个只能阅读摘要而不阅读文章的读者。
收集人类反馈
先前根据人类反馈对语言模型进行微调的研究表明[66]:我们希望自身模型学习的质量与人类标签者实际评估的质量之间存在不匹配。这导致了模型生成摘要在标签者看来质量是好的,但在研究人员看来,质量却很低。
与 [66] 相比,研究者实现了两个改进来提高人类数据质量。首先,完全过渡到离线设置,在这里交替发送大量的比较数据给人工标签者,然后根据累积收集的数据重新训练模型;其次,与标签者保持亲密关系:给他们详细的指导,在共享的聊天室中回答他们的问题,并定期对他们的表现提供反馈。
模型
研究者使用的所有模型都是 GPT-3 风格的 Transformer 解码器,并对具有 13 亿(1.3B)和 67 亿(6.7B)参数的模型进行人类反馈实验。与 [12,44] 类似,研究者从预训练模型开始,以自动回归预测大型文本语料库中的下一个 token。
接着,通过监督学习对这些模型进行微调,根据过滤后的 TL; DR 数据集预测摘要(详细信息参见附录 B)。使用这些监督模型对初始摘要进行抽样,以收集比较结果,初始化策略和奖励模型,并作为评估基准。
最后,为了训练奖励模型,研究者从一个监督基准开始,然后添加一个随机初始化线性头(linear head)输出一个标量值。
研究者想要利用训练得到的奖励模型,来训练一个能够生成基于人类判断的高质量输出的策略。
实验
根据人类反馈生成 Reddit 帖子的摘要
与规模更大的监督策略相比,基于人工反馈训练的策略更可取。在 TL;DR 数据集上评估人工反馈策略的主要结果如下图 1 所示:
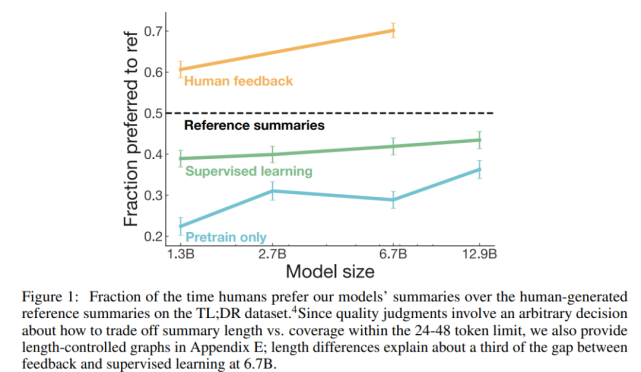
研究者衡量策略质量采用的指标是该数据集中由该策略生成的人们偏好的参考摘要所占的百分比。从图中可以看到,基于人工反馈训练的策略显著优于监督基准策略,并且 1.3B 的人工反馈模型也显著优于其 10 倍规模的监督模型(两者相对于参考摘要的原始偏好得分为 61% vs 43%)。
控制摘要长度
在判断摘要质量时,摘要长度是一个混淆因子(confounding factor)。摘要的目标长度是摘要生成任务的隐式部分,并且根据简洁性与涵盖性之间的预期权衡来判断生成长摘要还是短摘要。
该研究中的模型学会了生成更长的摘要,因此长度在质量改进中起到了很大的作用。
策略如何在基准上实现提升?
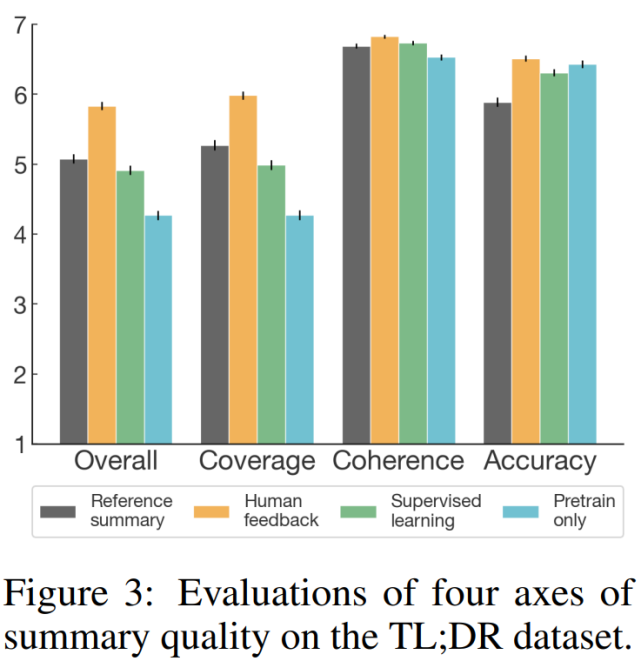
为了更好地了解该模型生成摘要与参考摘要和监督基准摘要三者之间的质量比较,研究者进行了一项补充分析,其中人类标签员使用 7-point 李克特量表(Likert scale)从四个指标(整体表现、涵盖性、连贯性和准确性)对摘要质量进行了评估。评估结果如下图 3 所示,表明从所有指标,特别是涵盖性来看,人类反馈模型优于监督基准模型。
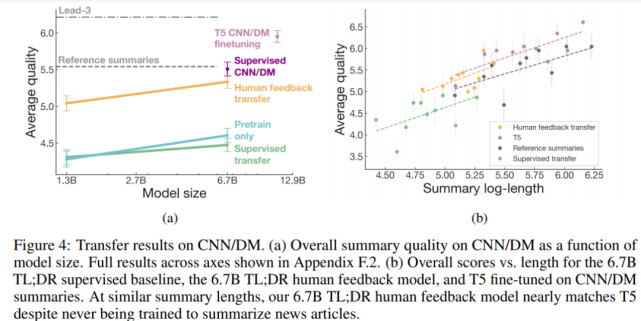
具备生成新闻文章摘要的迁移性
如下图 4 所示,人类反馈模型还可以在没有任何进一步训练的情况下,生成优秀的 CNN/DM 新闻文章摘要。
具体来讲,人类反馈模型在 TL;DR 数据集上显著优于通过监督学习训练的模型,以及仅在预训练语料库上训练的模型。尽管生成的摘要更短,6.7B 人类反馈模型的效果几乎相当于在 CNN/DM 参考摘要上进行微调的 6.7B 模型。
理解奖励模型
优化奖励模型
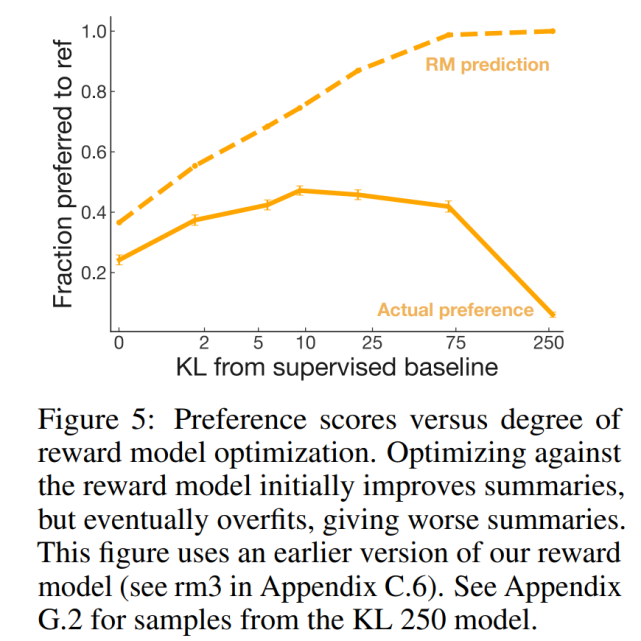
根据该研究的奖励模型进行优化应该使该研究的策略和人的偏好保持一致。但是奖励模型并不能完美地代表标签偏好。虽然该研究希望奖励模型能够泛化到训练期间不可见的摘要,但尚不清楚在奖励模型开始进行无用的评估之前,奖励模型能够优化多少。
为了回答这个问题,研究者创建了一系列针对奖励模型的早期版本进行优化的策略,这些策略都具有不同程度的优化强度,并要求标签者对将其样本与参考摘要进行比较。
奖励模型如何随着模型和数据量的增加进行扩展?
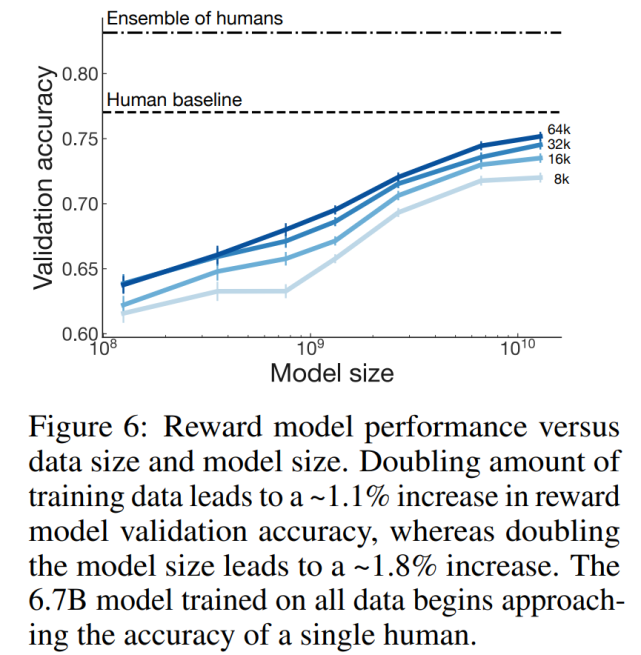
研究者进行了控制变量实验以确定数据量和模型大小如何影响奖励模型的性能。研究者训练了 7 个奖励模型,从 160M 到 13B 参数,从 8k 到 64k 的人类比较数据。
该研究发现,训练数据量增加一倍会导致奖励模型验证集准确率增加大约 1.1%,而模型大小增加一倍则会导致增加大约 1.8%。具体如下图 6 所示:
奖励模型学到了什么?
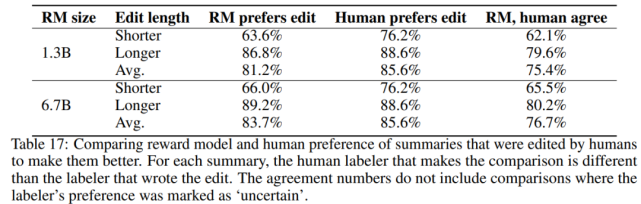
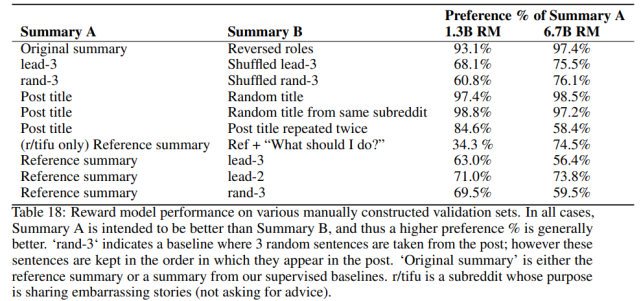
研究者在几个验证集中评估了该奖励模型,在下表 17 中给出了完整结果:
研究者发现该奖励模型泛化到评估 CNN/DM 摘要,具体如下表 18 所示:
分析用于摘要的自动度量指标
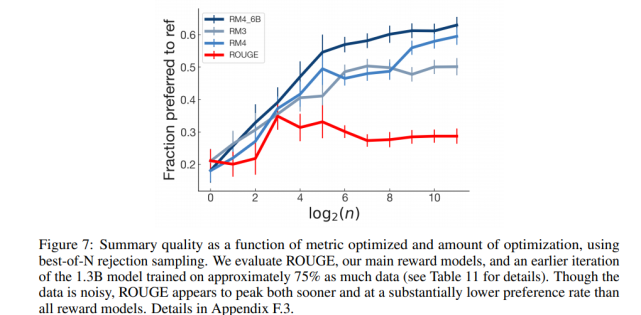
研究者研究了各种自动度量指标如何很好地预测人类的偏好,并将其与 RM 进行比较。具体来讲,研究者在基线监督模型下检查了 ROUGE、摘要长度、从帖子中复制的数量以及对数概率。
如下图 7 所示,使用简单的优化方案优化 ROGUE 并不能持续提高质量,与针对奖励模型的优化相比,针对 ROGUE 的优化不仅可以更快达到峰值,而且质量比率也大大降低。