












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
同样的脸,放上不同的声音,还可以做到如此同步。
当DeepFake口型造假,效果是这样。
有没有发现这几个人语音语调完全相同。
闭眼一听,完全猜不到到底是谁?吴恩达?马斯克?到底是谁在说话?
而和原有的视频对比,面部变化也不明显,效果非常自然。

△用YouTube知名数码博主Linus配口型
这是一个名为Wav2Lip的模型——用来生成准确的唇语同步视频的新方法,来自印度海德拉巴大学的新研究。
任何人物身份,甚至包括卡通人物,任何语音和语言,都可以将口型视频高精度同步到任何目标语音。
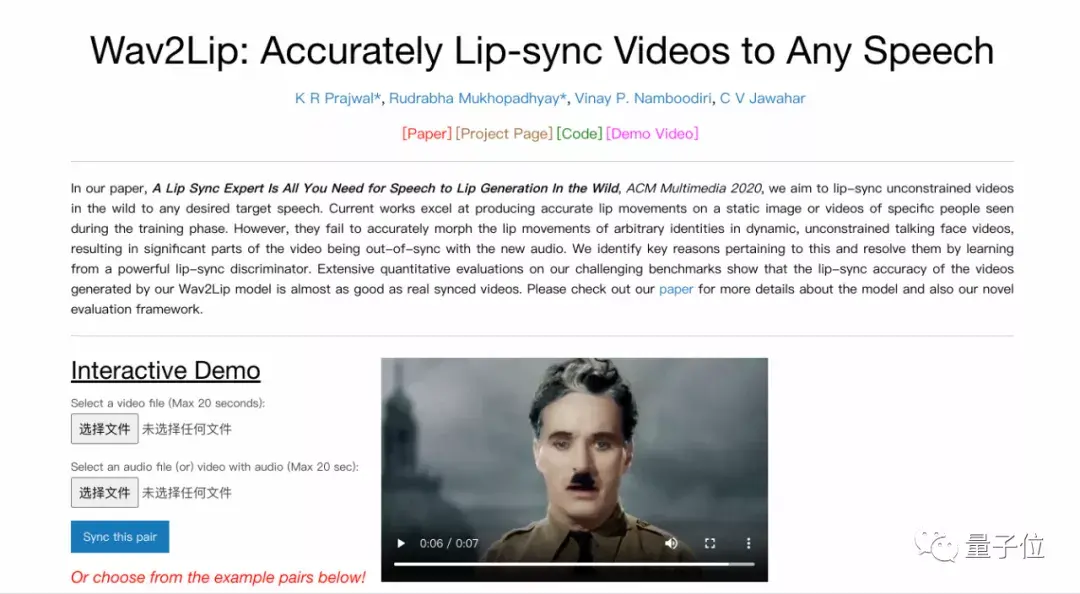
目前该项目已开源,可以去体验一下Demo版~只需上传20s的视频和音频文件就可以一键生成。
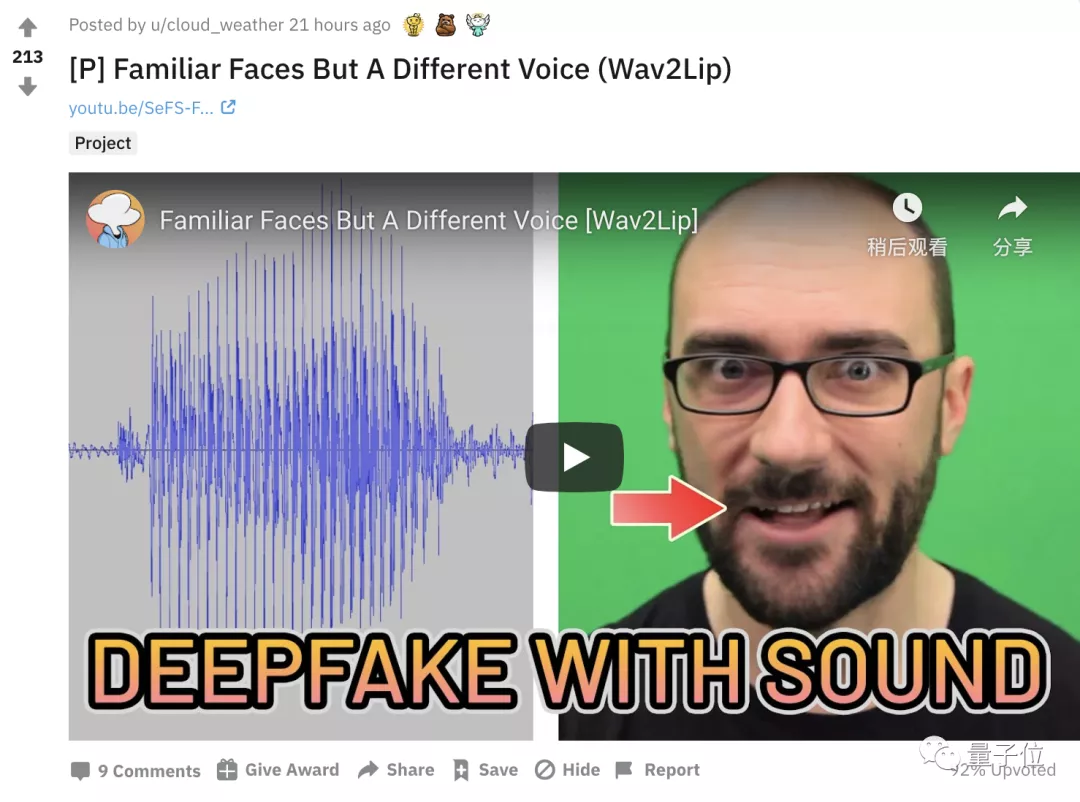
这项研究在Reddit上一经发布,21小时内就获得200+的热度。
对于这项研究的应用前景,作者说,可以应用在外文在线讲座、配音电影、新闻发布会,让人物和声音的融合更加自然,还省去大量的人力物力。
嗯,胥渡吧、淮秀帮这些配音团队或许可以用的上!
Wav2Lip模型
现有的研究,主要聚焦于在静态图像、或是对视频中的特定人物生成准确的唇语动作。
但问题在于,无法准确的对动态图像,比如正在说话的人物,唇部动作进行变形,从而导致内容与新音频无法做到完全同步。
就像是当你在看音画不同步的电影时,是不是很难受。
于是,研究人员找到了出现这一问题的关键原因,并通过一个「唇语同步辨别器」来解决。

具体而言,有两个关键原因,现有研究中所使用的损失函数,即L1重构损失和LipGAN中的判别器损失都不能减少错误的唇语同步生成。
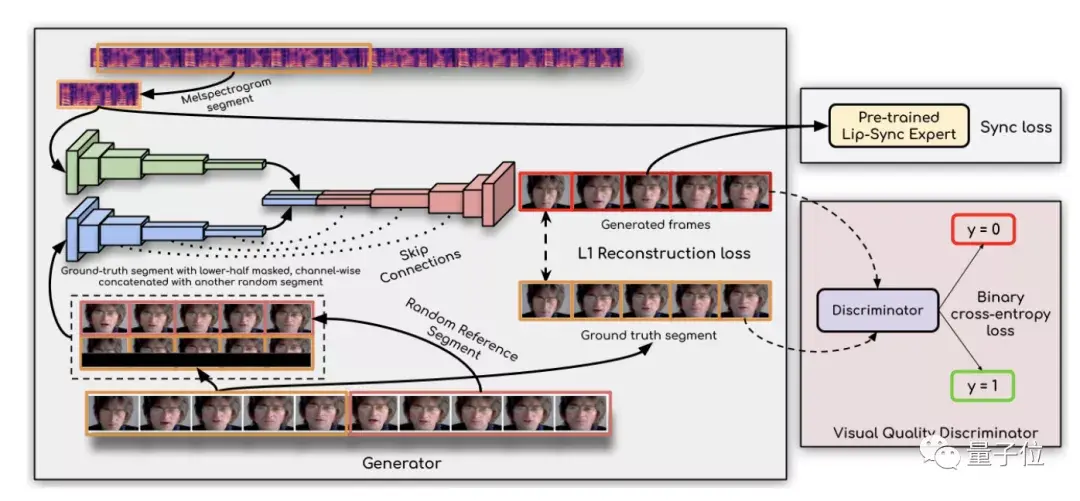
于是,研究人员就直接通过一个预先训练好的判别器「well-trained lip-sync expert」,来检测唇语同步的错误,这一判别结果已经相当准确。
此外,研究人员还发现,在产生噪声的面孔上进一步微调,会阻碍判别器测量唇部同步的能力,从而也会影响生成的唇形。
最后,还采用视觉质量鉴别器来提高视觉质量和同步精度。
举个例子,黄色和绿色框的是本次提出的模型,红色框为现有的最佳方法,文字是他们正在说的语句。
可以看到模型产生的唇形比现有的唇形更加准确、自然。
模型训练结果
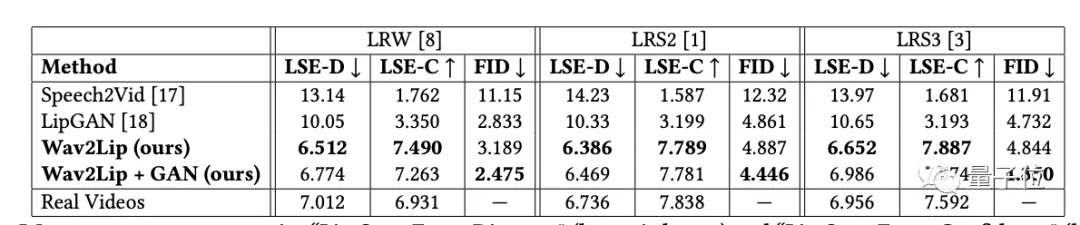
在模型训练阶段,作者提出了两个新指标, “Lip-Sync Error-Distance”(越低越好)和 “Lip-Sync Error-Confidence”(越高越好),这两个指标可以测量视频的中的唇语同步精度。
结果发现,使用Wav2Lip生成的视频几乎和真实的同步视频一样好。
需要注意的是,这个模型只在LRS2上的训练集上进行了训练,在对其他数据集的训练时需要对代码进行少量修改。
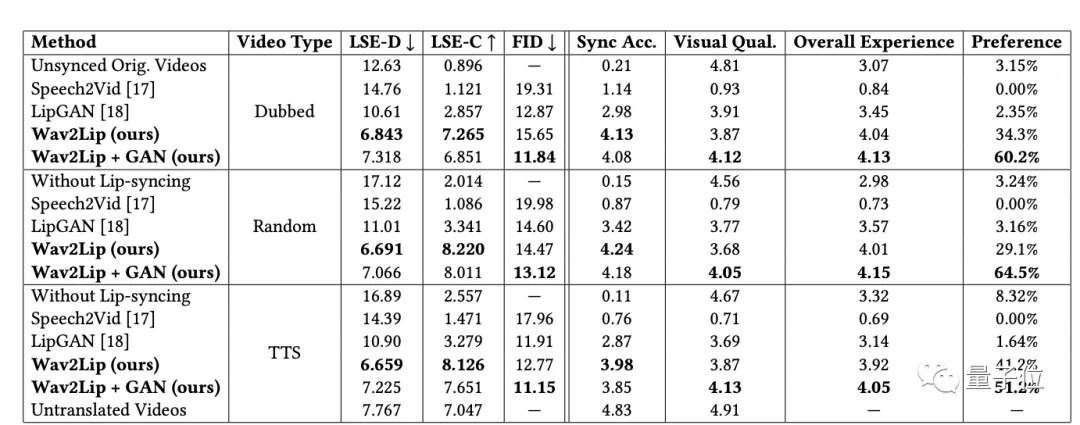
进一步的,还对现实的三种视频类型进行了评估。
结果均表明,Wav2Lip模型都能产生高质量、准确的唇语同步视频,不过,在对TTS生成的语音进行唇语同步时,还有改进的空间。
你觉得这项研究如何?
目前,项目已经开源,可以自行去体验一下Demo版哦~
再次提醒:只需上传20s的视频和音频文件,就可以一键生成哦!
论文地址:
https://arxiv.org/abs/2008.10010
Demo演示视频:
https://www.youtube.com/watch?v=SeFS-FhVv3g&feature=youtu.be
GitHub地址:
https://github.com/Rudrabha/Wav2Lip
Demo网址:
https://bhaasha.iiit.ac.in/lipsync/




















