背景
我相信大家在数据库优化的时候都会说到索引,我也不例外,大家也基本上能对数据结构的优化回答个一二三,以及页缓存之类的都能扯上几句,但是有一次阿里P9的一个面试问我:你能从计算机层面开始说一下一个索引数据加载的流程么?(就是想让我聊IO)
我当场就去世了....因为计算机网络和操作系统的基础知识真的是我的盲区,不过后面我恶补了,废话不多说,我们就从计算机加载数据聊起,讲一下换个角度聊索引。
正文
- MySQL的索引本质上是一种数据结构
让我们先来了解一下计算机的数据加载。
磁盘IO和预读:

先说一下磁盘IO,磁盘读取数据靠的是机械运动,每一次读取数据需要寻道、寻点、拷贝到内存三步操作。
寻道时间是磁臂移动到指定磁道所需要的时间,一般在5ms以下;
- 寻点是从磁道中找到数据存在的那个点,平均时间是半圈时间,如果是一个7200转/min的磁盘,寻点时间平均是600000/7200/2=4.17ms;
拷贝到内存的时间很快,和前面两个时间比起来可以忽略不计,所以一次IO的时间平均是在9ms左右。听起来很快,但数据库百万级别的数据过一遍就达到了9000s,显然就是灾难级别的了。
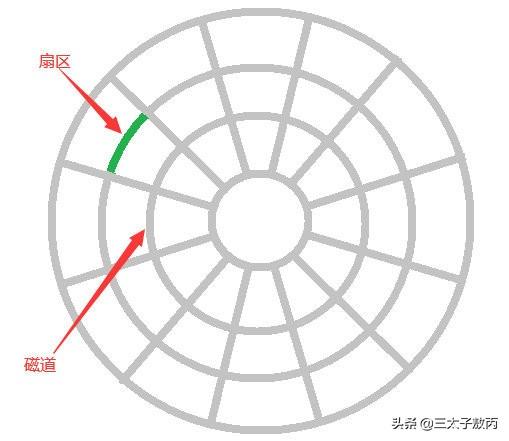
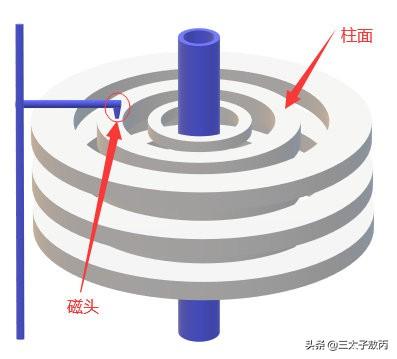
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了预读的优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。
每一次IO读取的数据我们称之为一页(page),具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO。
(突然想到个我刚毕业被问过的问题,在64位的操作系统中,Java中的int类型占几个字节?最大是多少?为什么?)
那我们想要优化数据库查询,就要尽量减少磁盘的IO操作,所以就出现了索引。
索引是什么?
- MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
- MySQL中常用的索引在物理上分两类,B-树索引和哈希索引。
本次主要讲BTree索引。
BTree索引
BTree又叫多路平衡查找树,一颗m叉的BTree特性如下:
树中每个节点最多包含m个孩子。
除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子(ceil()为向上取整)。
若根节点不是叶子节点,则至少有两个孩子。
所有的叶子节点都在同一层。
每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1 。
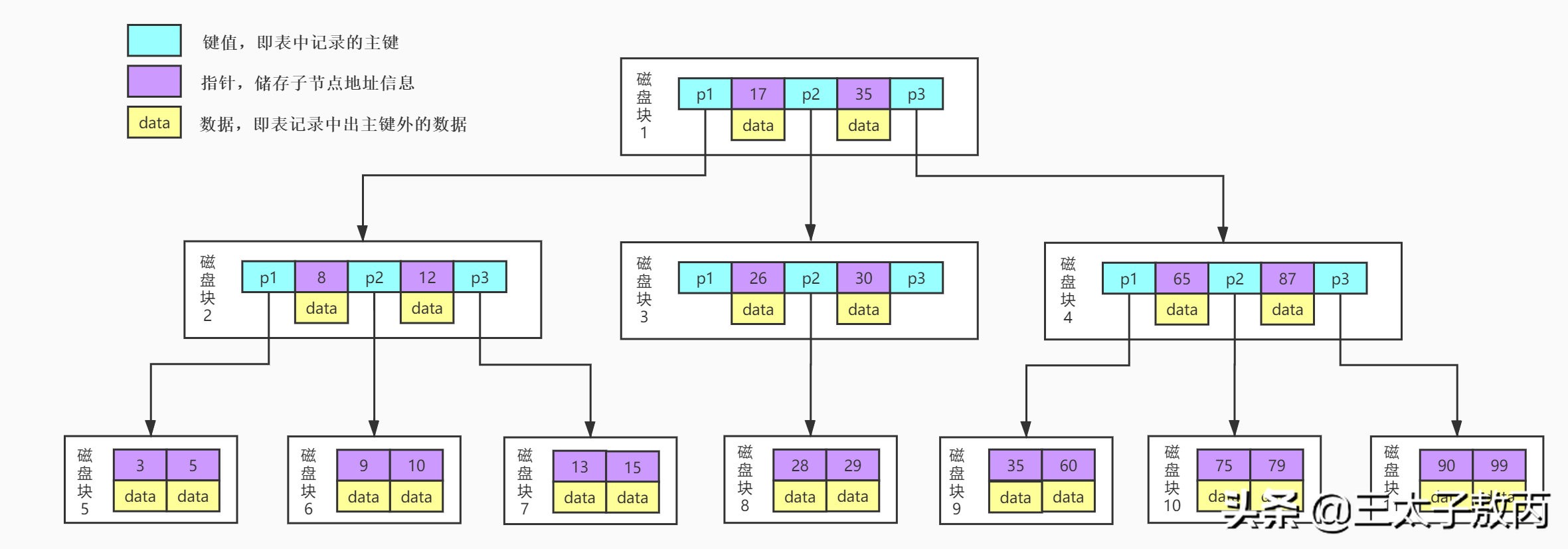
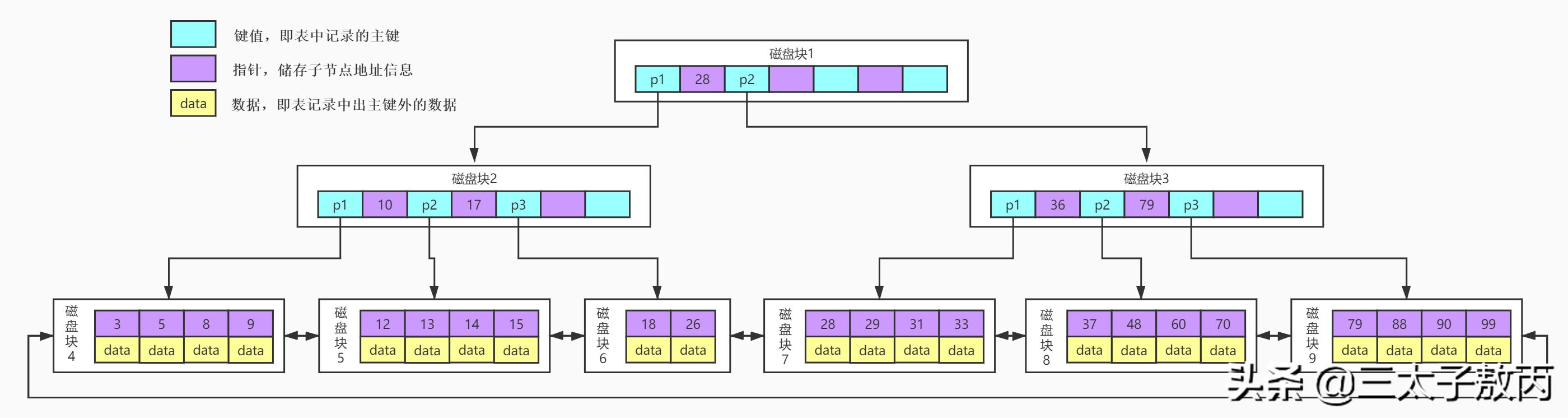
这是一个3叉(只是举例,真实会有很多叉)的BTree结构图,每一个方框块我们称之为一个磁盘块或者叫做一个block块,这是操作系统一次IO往内存中读的内容,一个块对应四个扇区,紫色代表的是磁盘块中的数据key,黄色代表的是数据data,蓝色代表的是指针p,指向下一个磁盘块的位置。
来模拟下查找key为29的data的过程:
- 根据根结点指针读取文件目录的根磁盘块1。【磁盘IO操作1次】
- 磁盘块1存储17,35和三个指针数据。我们发现17<29<35,因此我们找到指针p2。
- 根据p2指针,我们定位并读取磁盘块3。【磁盘IO操作2次】
- 磁盘块3存储26,30和三个指针数据。我们发现26<29<30,因此我们找到指针p2。
- 根据p2指针,我们定位并读取磁盘块8。【磁盘IO操作3次】
- 磁盘块8中存储28,29。我们找到29,获取29所对应的数据data。
由此可见,BTree索引使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
但是有没有什么可优化的地方呢?
我们从图上可以看到,每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。
B+Tree索引
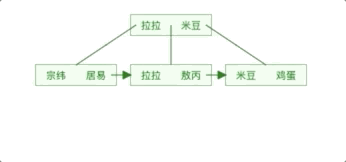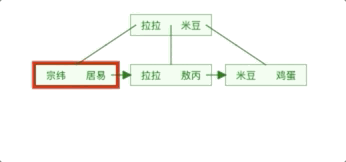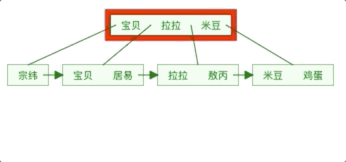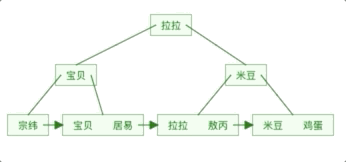
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
B+Tree相对于B-Tree有几点不同:
- 非叶子节点只存储键值信息, 数据记录都存放在叶子节点中, 将上一节中的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,所以B+Tree的高度可以被压缩到特别的低。
具体的数据如下:
- InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。
也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。(这种计算方式存在误差,而且没有计算叶子节点,如果计算叶子节点其实是深度为4了)
我们只需要进行三次的IO操作就可以从10亿条数据中找到我们想要的数据,比起最开始的百万数据9000秒不知道好了多少个华莱士了。
而且在B+Tree上通常有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。所以我们除了可以对B+Tree进行主键的范围查找和分页查找,还可以从根节点开始,进行随机查找。
数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。
上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据,辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。
当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据。
不过,虽然索引可以加快查询速度,提高 MySQL 的处理性能,但是过多地使用索引也会造成以下弊端:
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。
注意:索引可以在一些情况下加速查询,但是在某些情况下,会降低效率。
索引只是提高效率的一个因素,因此在建立索引的时候应该遵循以下原则:
- 在经常需要搜索的列上建立索引,可以加快搜索的速度。
- 在作为主键的列上创建索引,强制该列的唯一性,并组织表中数据的排列结构。
- 在经常使用表连接的列上创建索引,这些列主要是一些外键,可以加快表连接的速度。
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,所以其指定的范围是连续的。
- 在经常需要排序的列上创建索引,因为索引已经排序,所以查询时可以利用索引的排序,加快排序查询。
- 在经常使用 WHERE 子句的列上创建索引,加快条件的判断速度。
现在大家知道索引为啥能这么快了吧,其实就是一句话,通过索引的结构最大化的减少数据库的IO次数,毕竟,一次IO的时间真的是太久了。。。
总结
就面试而言很多知识其实我们可以很容易就掌握了,但是要以学习为目的,你会发现很多东西我们得深入到计算机基础上才能发现其中奥秘,很多人问我怎么记住这么多东西,其实学习本身就是一个很无奈的东西,既然我们不能不学那为啥不好好学?去学会享受呢?最近我也在恶补基础,后面我会开始更新计算机基础和网络相关的知识的。