本文转载自微信公众号「小菜良记」,作者蔡不菜丶。转载本文请联系小菜良记公众号。
初始Kafka
1、介绍
Kafka 起初是由 Linkedin 公司采用 Scala 语言开发的一个多分区、多副本且基于 ZooKeeper协调的分布式消息系统,现己被捐献给 Apache 基金会 。目前 Kafka 已经定位为一个分布式流式处理平台,它以高吞吐、可持久化、可水平扩展、支持流数据处理等多种特性而被广泛使用。
2、使用场景
消息系统:Kafka 和传统的消息系统(消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka还提供了大多数消息系统难以实现的消息顺序性保障以及回溯消费的功能。
存储系统:Kafka把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于 Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置为 “永久” 或启用主题的日志压缩功能即可。
流式处理平台:Kafka 不仅为每个流行的流式处理框架里提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、交换和聚合等各类操作。
3、基本概念
Kafka体系架构包括若干 「Producer」,「Broker」,「Consumer」以及一个ZooKeeper集群。
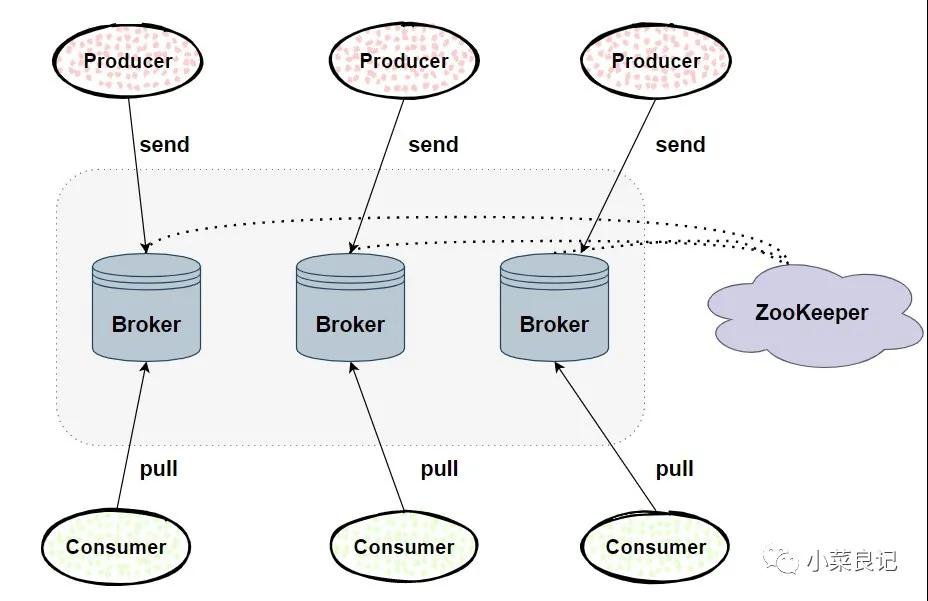
- ZooKeeper:是 Kafka 用来负责集群元数据的管理、控制器的选举等操作的。
- Producer:生产者,发送消息的一方。负责创建消息,然后将其投递到 Kafka 中。
- Consumer:消费者,接收消息的一方。连接到 Kafka 后接收消息,并进行相应的业务逻辑处理。
- Broker:服务代理节点。对于 Kafka 而言,Broker 可以简单地看作一个独立的 Kafka 服务节点或 Kafka 服务实例。大多数情况下也可以将 Broker 看作一台 Kafka 服务器,前提是这台服务器上只部署了一个 Kafka 实例。一个或多个Broker 组成了一个 Kafka 集群。
整体 Kafka 体系大概是由上面几部分构成。除此之外,还有两个特别重要的概念:主题(Topic)和分区(Partition)
- 主题:Kafka 中的消息以主题为单位进行归类,生产者负责将消息发送到特定的主题(发送到 Kafka 集群中的每一条消息都要指定一个主题),而消费者负责订阅主题并进行消费。
- 分区:主题是一个逻辑上的概念。还可以细分为多个分区,一个分区只属于单个主题,很多时候也会把分区称为主题分区(Topic-Partition)。同一主题下的不同分区包含的消息是不同的,分区在存储层面可以看作一个可追加的「日志文件」,消息在被追加到分区日志文件的时候都会分配一个特定的偏移量(offset)。offset 是消息在分区中的唯一标识,Kafka 通过它来保证消息在分区内的顺序性,不过offset并不跨越分区,也就是说,Kafka 保证的是分区有序而不是主题有序。
Kafka 为分区引入了多副本(Replica) 机制,通过增加副本数量可以提升容灾能力。
同一分区的不同副本中保存的是相同的消息(在同一时刻,副本之间并非完全一样),副本之间是“ 一主多从”的关系,其中 leader 副本负责处理读写请求 ,follower 副本只负责与 leader 副本的消息同步。副本处于不同的 broker 中 ,当 leader 副本出现故障时,从 follower 副本中重新选举新的 leader 副本对外提供服务。
「Kafka 通过多副本机制实现了故障的自动转移,当 Kafka 集群中某个 broker 失效时仍然能保证服务可用 。」
在我们继续了解 Kafka 之前,我们还需要明白几个关键词:
- AR(Assigned Replicas):分区中所有副本统称为 AR
- ISR(In-Sync Replicas):所有与 leader 副本保持一定程度同步的副本(包括 leader 副本在内)组成 ISR。ISR 集合是 AR 集合中的一个子集 。消息会先发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步,同步期间内follower 副本相对于 leader 副本而言会有一定程度的滞后 。
- OSR(Out-of-Sync Replicas):与 leader 副本同步滞后过多的副本(不包括 leader 副本)组成 OSR
由以上关系我们可以得出一个公式:AR=ISR+OSR
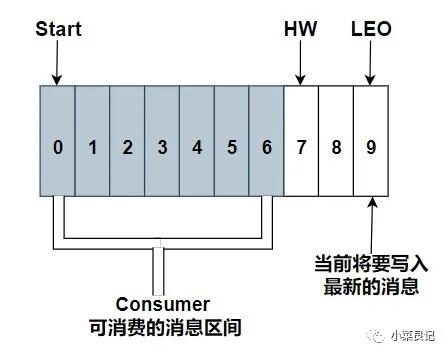
- HW(High Watermark):俗称高水位,是用来标识一个特定的消息偏移量(offset),消费者只能拉取到这个 offset 之前的消息
- LEO(LogStartOffset):下一条待写入消息的 offset
相信很多小伙伴看到这里有点不耐烦了,这 Kafka 怎么这么难,还能不能好好学习了
莫急莫急,理论知识咱们还是要先过一遍,这可不是劝退的开始,这是你成长的开始!下面小菜力求用最简朴的语句带你入最深的坑!
Kafka 之 生产大队
众所周知,Kafka 说高尚点是一个分布式消息队列,简单来说不就是一个消息队列。消息队列简单来说不就是推数据,拿数据的嘛。没错,高端的知识往往需要简单的理解。
那么数据从哪来,数据从生产队来!从编程的角度而言,生产大队里面有一群生产者(当然也可以只有一个),生产者就是负责向 Kafka 发送消息的应用程序。
客户端开发
生产过程大致得具备以下几个步骤方能生产:
- 配置生产者客户端参数以及创建响应的生产者实例
- 构建待发送的消息
- 发送消息
- 关闭生产者实例
「四大步骤一梭子解决生产问题」
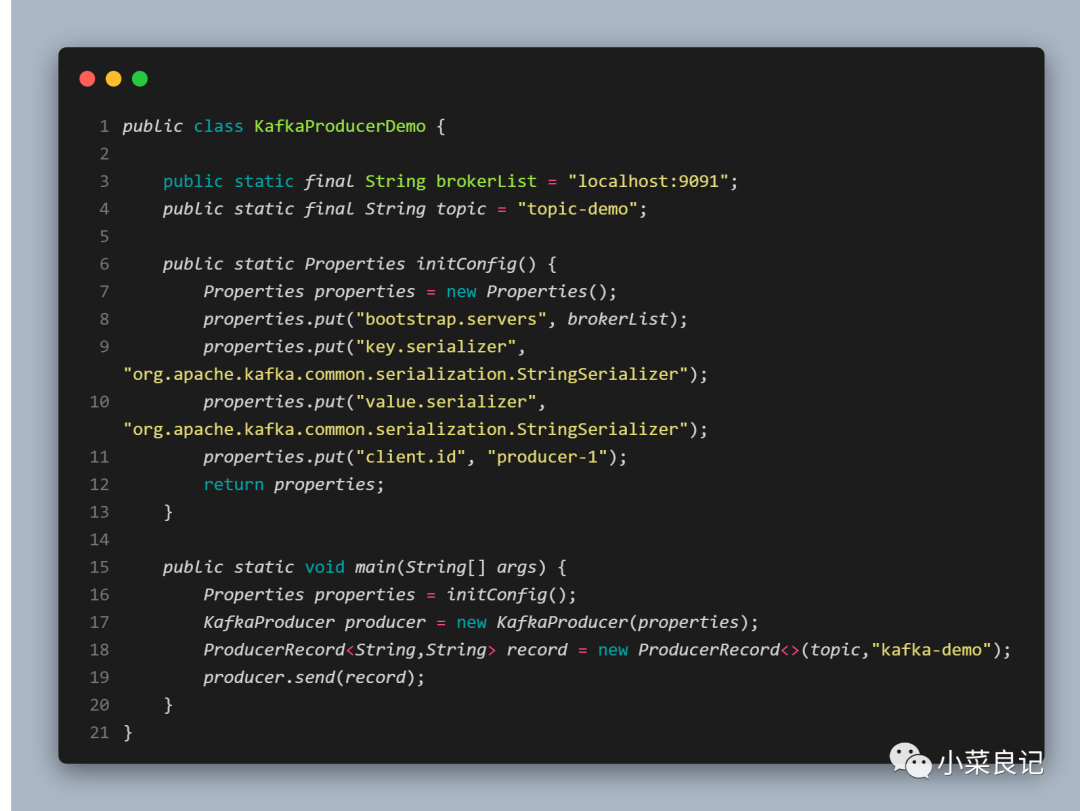
上面的代码中可以看到我们往 Properties 文件中 put 进了四个参数,分别为:
- bootstrap.servers:改参数用来指定生产者客户端连接 Kafka 集群所需的 broker 地址。格式为(host1:port1,host2:port2),可以设置一个或多个地址,中间以逗号隔开,默认值为 “ ”
- key.serializer 和 value.serializer:分别用来指定 key 和 value 序列化操作的序列化器,这两个参数无默认值,需要填写序列化器的全限定名
- client.id:用来设定 KafkaProducer 对应的客户端 id,默认值为 “ ”。如果客户端不设置,则KafkaProducer 会自动生成一个非空字符串,内容形式为 “producer-1”,“producer-2”,即字符串 “producer-” 和数字的拼接
其中ProducerRecord定义如下:
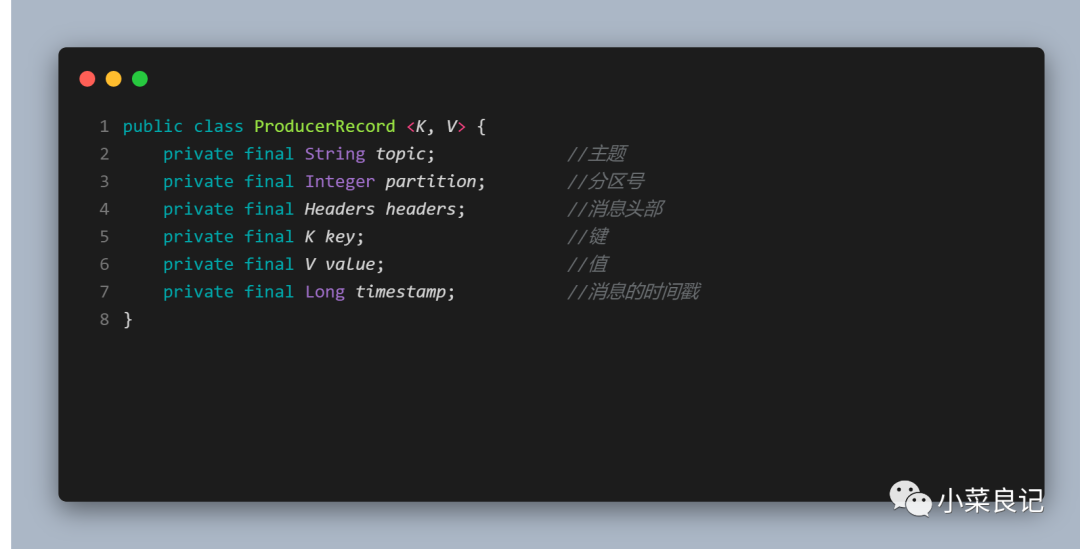
- topic和partition :分别代表消息要发往的主题和分区号;
- headers:消息的头部,不需要时可以不设置
- key:用来指定消息的键,它不经是消息的附加消息,还可以用来计算分区号进而可以让消息发往特定的分区。
- value:消息体,一般不为空,如果为空则表示特定的消息 -- 「墓碑消息」
- timestamp:消息的时间戳,它有 CreateTime 和 LogAppendTime 两种类型,前者表示消息创建的时间,后者表示消息追加到日志文件的时间
上面的操作就是创建生产者实例和构建消息,发送消息主要有三种模式:
- 发后即忘(fire-and-forget)
- 同步(sync)
- 异步(async)
而我们上面使用的发送方式就是发后即忘,它只管往 Kafka 中发送消息而并不关心消息是否正确到达,大多数情况下,这种发送方式是没有什么问题的,不过在有些时候(发生不可重试异常)会造成消息丢失。「尽管这种发送方式性能最高,但是可靠性也最差。」
- public Future<RecordMetadata> send(ProducerRecord<K,V> record) {}
从send方法来看,是返回一个Future对象
- Future res = producer.send(record);
这说明 send()方法本身就是异步的,send()方法返回的Future对象可以使调用方稍后获得发送的结果。如果我们想实现同步的效果,可以直接调用Future的get()方法实现。
- try {
- producer.send(record).get();
- } catch (Exception e) {
- e.printStackTrace();
- }
通过get()方法来阻塞等待 Kafka 的响应,直到消息发送成功,或者发生异常
生产也能异步?
在 Kafka 中 send()方法有另外一个重载方式:
- public Future<RecordMetadata> send(ProducerRecord<K,V> record, Callback callback) {}
- producer.send(record, new Callback() {
- @Override
- public void onCompletion(RecordMetadata recordMetadata, Exception e) {
- if (Objects.isNull(e)) {
- System.out.println("主题:" + recordMetadata.topic());
- } else {
- System.out.println(e.getMessage());
- }
- }
- });
使用 Callback 的方式非常简洁明了,Kafka 有响应时就会回调,要么发送成功,要么抛出异常。
onCompletion()方法中两个参数是互斥的,如果发送成功则RecordMetadata不为空,Exception为空,如果发送失败则相反。
生产也有困难?
在 KafkaProducer 中 一般会发生两种类型的异常:
- 可重试异常
NetworkException、LeaderNotAvailableException、UnknownTopicOrPartitionException、
NotEnoughReplicasException、NotCoordinatorException
- 不可重试异常
RecordTooLargeException等
对可重试异常我们可以配置 「retries」参数,如果在规定的重试次数内自行恢复,就不会抛出异常,「retries」参数的默认值为 0 ,配置方式如下:
- properties.put(ProducerConfig.RETRIES_CONFIG, 10);
上述例子中含义为,重试次数为 10 次,如果超过 10 次还没恢复则会抛出异常。
不可重试异常如RecordTooLargeException,暗示了如果发送消息太大,则不会进行重试,直接抛出异常。
序列化来助力
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给 Kafka,对应的消费者也需要用反序列化器(Deserializer)把 Kafka 中收到的字节数组转换成相应的对象。
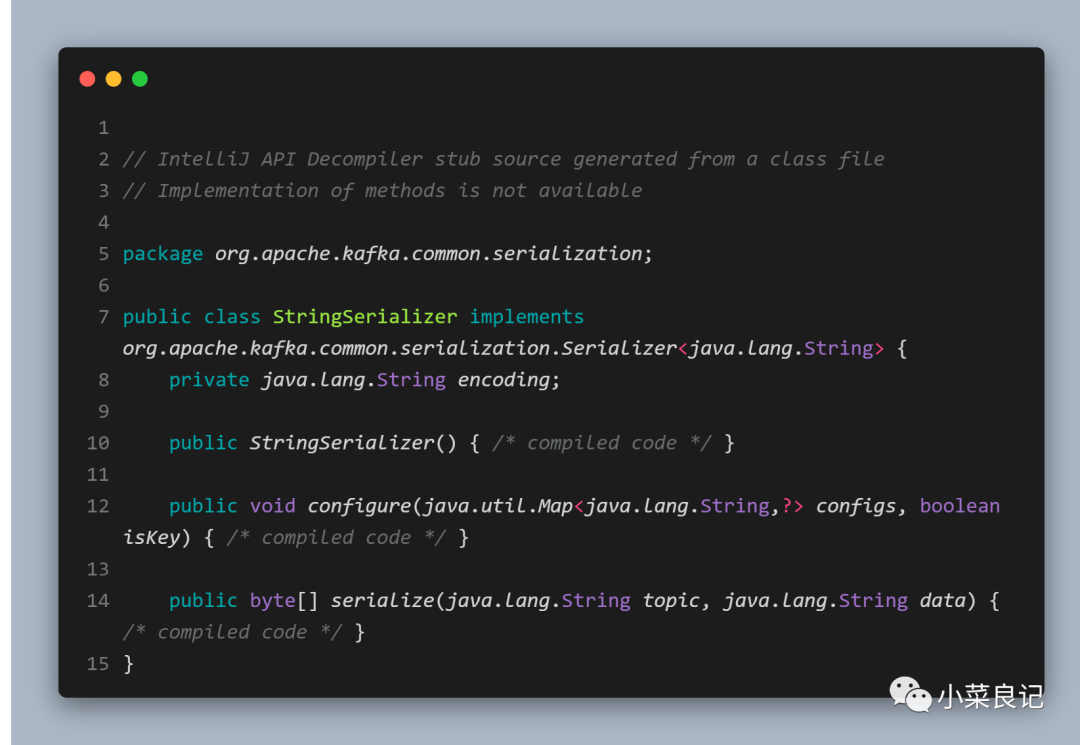
在上面代码使用到的StringSerializer实现了Serializer接口
其中 configure()方法用来配置当前类,serizlize()方法用来执行序列化操作
「生产者使用的序列化器和消费者使用的反序列化器是需要一一对应的」
当然除了可以用 Kafka 提供的序列化器,我们也可以自定义序列化器:
「Student.class」:
- @Data
- public class Student {
- private String name;
- private String remark;
- }
「MySerializer」:
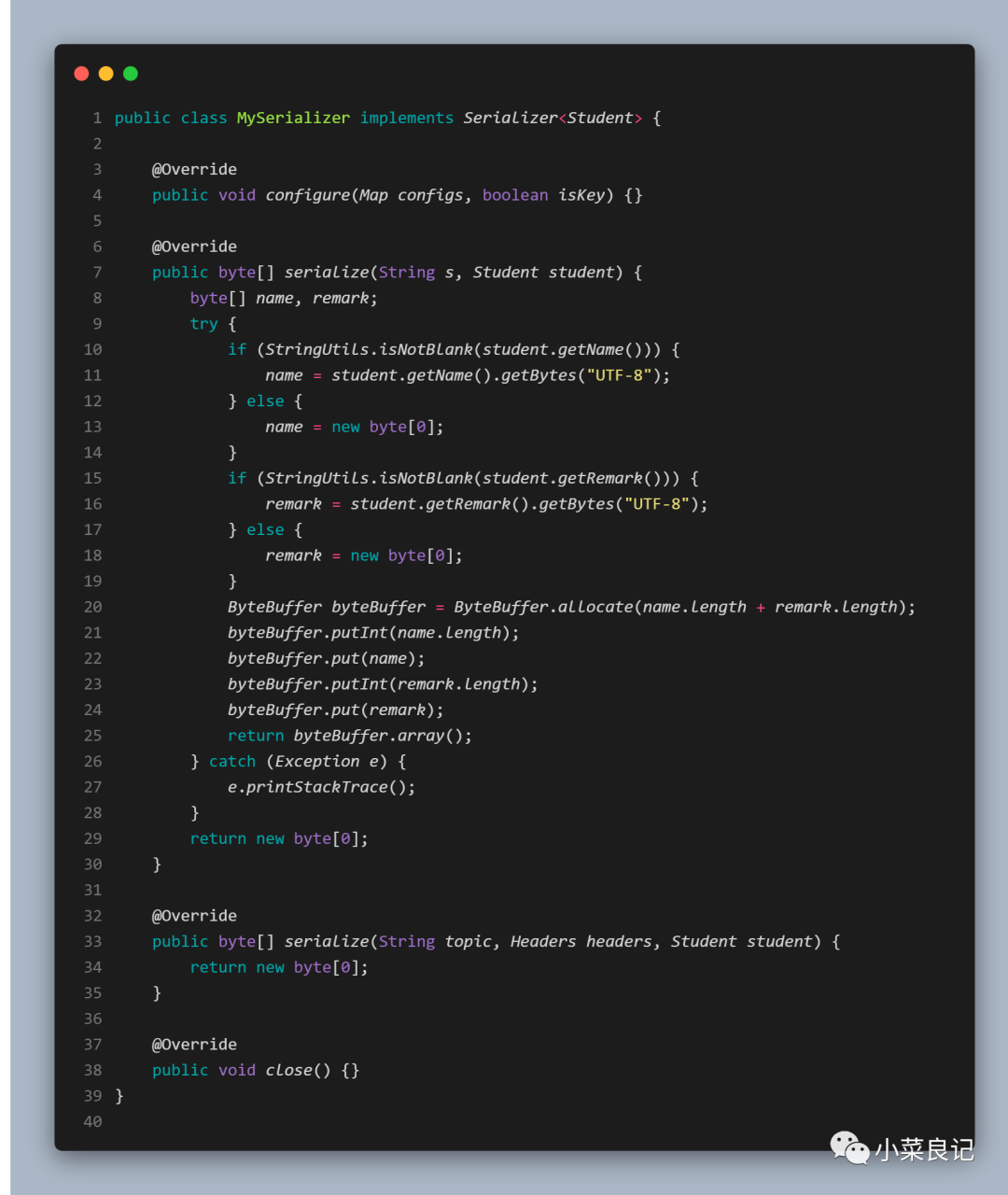
「使用」:
- properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, MySerializer.class.getName());
只需要在 Properties 中 put 进我们自己的序列化器即可,没想到也挺简单的嘛!
分区器又是啥?
消息在通过 send() 方法发送到 broker 的过程中,可能需要经过 「拦截器(Interceptor)」,「序列化器(Serializer)」 和「分区器(Partitioner)」
其中 「拦截器」 不是必需的,「序列化器」 是必须的,经过序列化器后就需要确定它发往的分区,如果消息 ProducerRecord 中指定了 partition 字段,那么就不需要「分区器」的作用,因为partition代表的就是所要发往的分区号。
- package org.apache.kafka.clients.producer;
- public interface Partitioner extends Configurable, Closeable {
- int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
- void close();
- }
上述是 kafka 中的Partitioner 接口,可以看到里面有个方法partition()是用来计算分区号,返回 int 类型的值,其中六个参数分别代表:
- topic:主题
- key:键
- keyBytes:序列化后的键
- value:值
- valueBytes:序列化后的值
- cluster:集群的元数据信息
在partition()方法中定义了主要的分区分配逻辑,如果 key 不为空时,那么默认的分区器会对 key 进行haxi(采用MurmurHash2算法),最终根据得到的哈希值来计算分区号,拥有相同 key 的消息会被写入同一个分区,如果 key 为空,那么消息将会以轮询的方式发往主题内的各个可用分区。
「如果 key 不为 null,那么计算得到的分区号会是所有分区中的任意一个,如果 key 为 空 ,那么计算得到的分区号仅为可用分区中的任意一个」
当然,分区器也是可以自定义的,操作如下:
「MyPartitioner.class」:
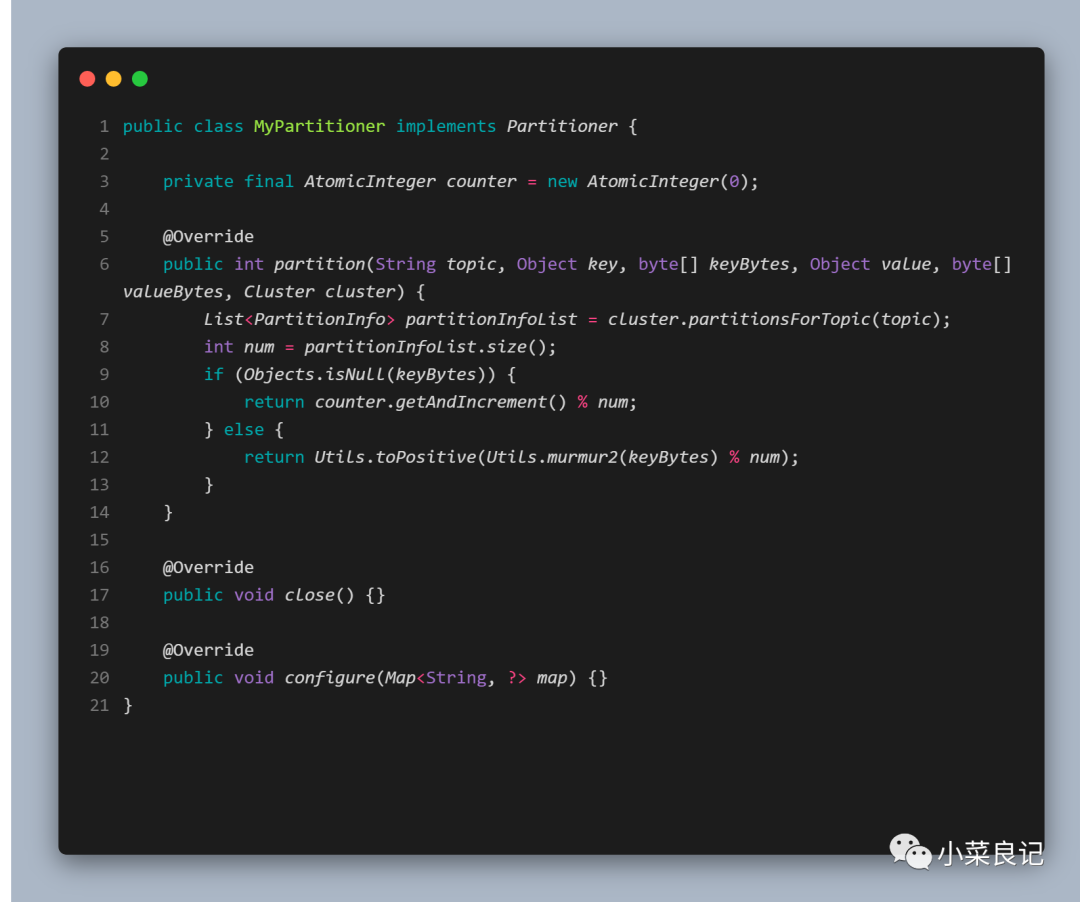
「使用」:
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, MyPartitioner.class.getName());
自定义分区器使用起来也简单,只需要实现 Partitioner 接口
拦截器来了?
做 web 开发的同学相信对拦截器一点也不陌生,在 Kafka 中也具有拦截器的功能,拦截器又分为「生产者拦截器」和「消费者拦截器」
生产者拦截器可以在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息,修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求。
那么有需要就会有自定义,在自定义拦截器的时候我们只需要实现ProducerInterceptor接口即可:
- package org.apache.kafka.clients.producer;
- public interface ProducerInterceptor <K, V> extends Configurable {
- ProducerRecord<K,V> onSend(ProducerRecord<K,V> producerRecord);
- void onAcknowledgement(RecordMetadata recordMetadata, Exception e);
- void close();
- }
其中onSend()方法可以对消息进行相应的定制化操作,onAcknowledgement()方法是在消息发送失败或者消息被应答(Acknowledgement)之前调用,优先于用户设定的 Callback。
自定义拦截器如下:MyProducerInterceptor.class:
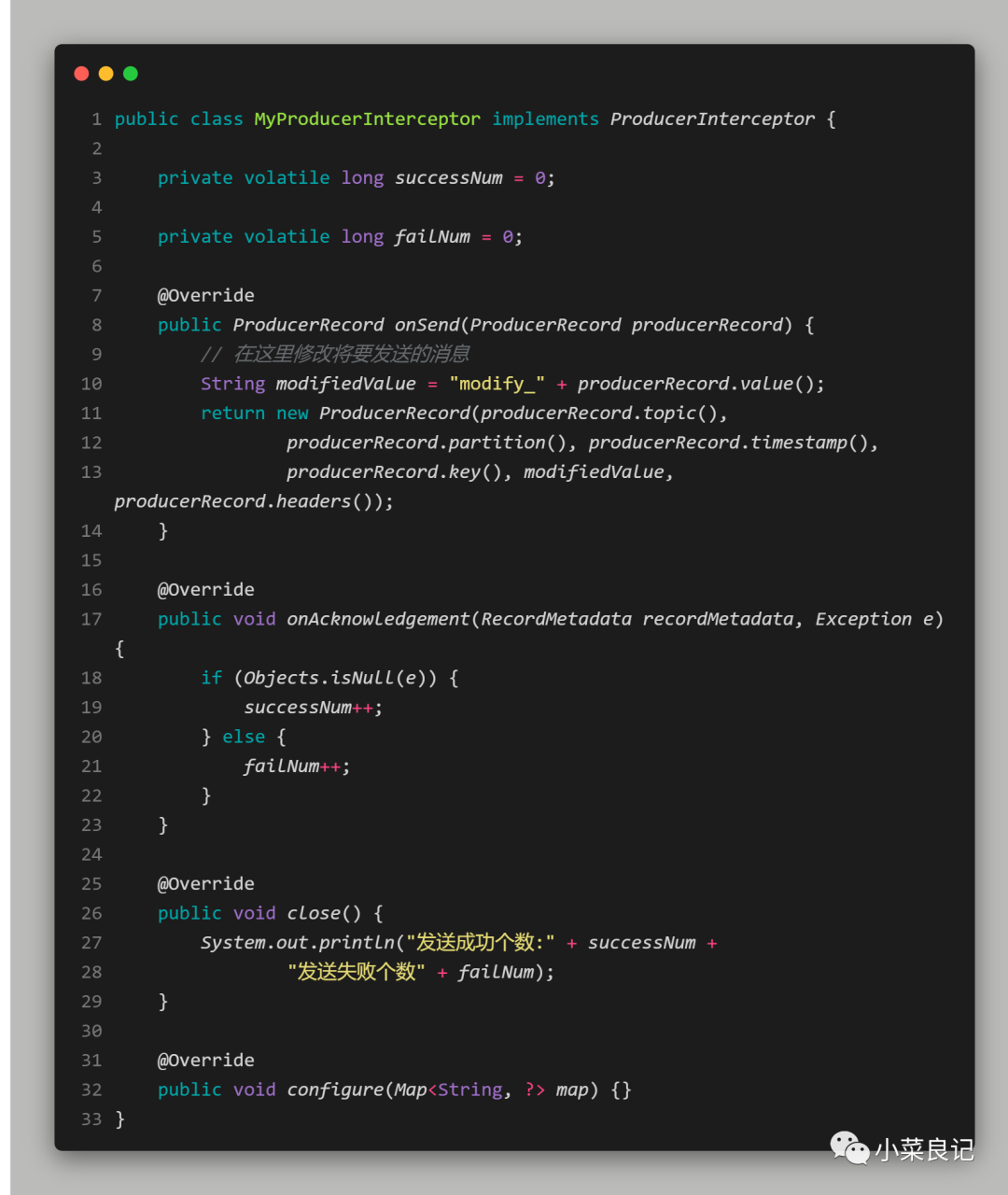
在onSend()方法中我们修改了将要发送的消息,在onAcknowledgement()方法中我们统计了发送成功数和失败数,接着在close()方法中,我们将成功数和失败数进行了输出
同样的使用方法:
- properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, MyProducerInterceptor.class.getName());
有一个拦截器自然就会形成一个拦截器链,我们可以自定义多个拦截器,然后在 Properties 文件中声明:
- properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, MyProducerInterceptor1.class.getName() + "," + MyProducerInterceptor2.class.getName());
「这样子下一个拦截器就会依赖于前一个拦截器的输出」
重要参数
除了上述已经出现的参数,还有以下一些重要的参数:
1. ack
这个参数用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条
- properties.put(ProducerConfig.ACKSCONFIG,”0”); //注意是字符串类型
消息是写入成功的。ack 中有三种类型(String)的值
- acks = 1:默认值为1,生产者发送消息之后,只要分区的leader 副本成功写入消息,那么它就会收到来自服务端的成功响应 。如果消息写入 leader 副本并返回成功响应给生产者,且在被其他 fo llower 副本拉取之前 leader 副本崩溃,那么此时消息还是会丢失。
- acks = 0:生产者发送消 息之后不需要等待任何服务端的响应。如果在消息从发送到写入 Kafka 的过程中出现某些异常,导致 Kafka 并没有收到这条消息,那么生产者也无从得知,消息也就丢失了。在其他配置环境相同的情况下,acks 设置为 0 可以达到最大的吞吐量。
- acks = -1或 acks = all:生产者在消 息发送之后,需要等待 ISR 中的所有副本都成功 写入消息之后才能够收到来自服务端的成功响应。在其他配置环境相同的情况下,acks 设置为 1或(all)可以达到最强的可靠性。
设置:
- properties.put(ProducerConfig.ACKSCONFIG,”0”); //注意是字符串类型
2. max.request.size
用来限制生产者客户端能发送的消息的最大值,默认值为1048576B ,即 1MB 。
3. retries
用来配置生产者重试的次数,默认值为 0,即在发生异常的时候不进行任何重试动作。
4. retry.backoff.ms
用来设定两次重试之间的时间间隔,避免无效的频繁重试,默认值为 100
5. connections.max.idle.ms
这个参数用来指定在多久之后关闭限制的连接,默认值是 540000( ms ),即 9 分钟。
6.buffer.memory
用来设置缓存消息的缓冲区大小
7.batch.size
用来设定可以复用内存区域的大小
Kafka 之 消费群体
有生产就有消费,你说是吧!与生产者对应的是消费者,应用程序可以通过 KafkaConsumer 来订阅主题,并从订阅的主题中拉取消息
个体和群体?
每个消费者都有一个对应的消费组。消费者( Consumer )负责订阅 Kafka 中的主题( Topic ),并且从订阅的主题上拉取消息。当消息发布到主题后,只会被投递给订阅它的每个消费组中的一个消费者 。
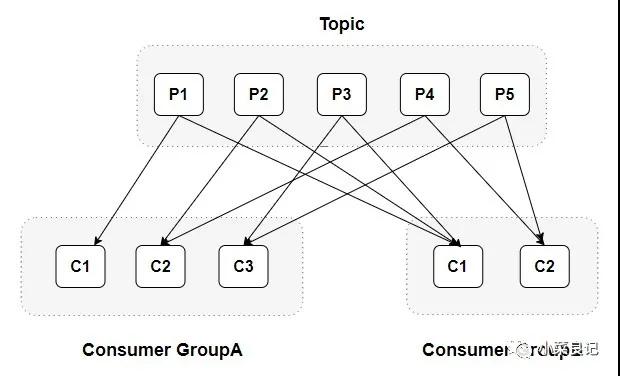
当消费组中只有一个消费者的时候,是这样的情况:
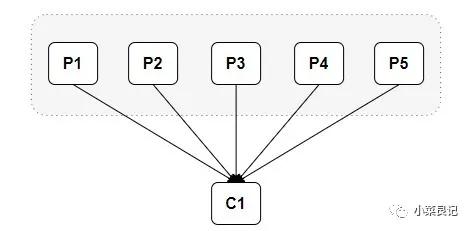
当消费组中有两个消费者的时候,是这样的情况:
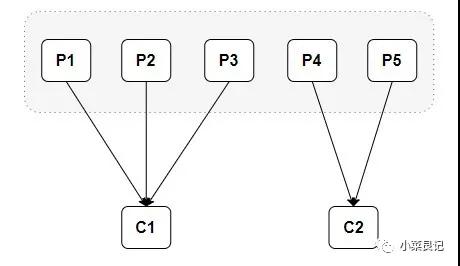
从上面的分配情况可以看出,随着消费者的增加,可以让整体的消费能力具有横向伸缩性。我们可以增加(或减少)消费者的个数来提高(或降低)整体的消费能力。当时在分区数固定的情况下,盲目地增加消费者并不会让消费能力一直得到提升,如果消费者过多,就会出现消费者个数大于分区个数的情况,就会有消费者分配不到任何分区。
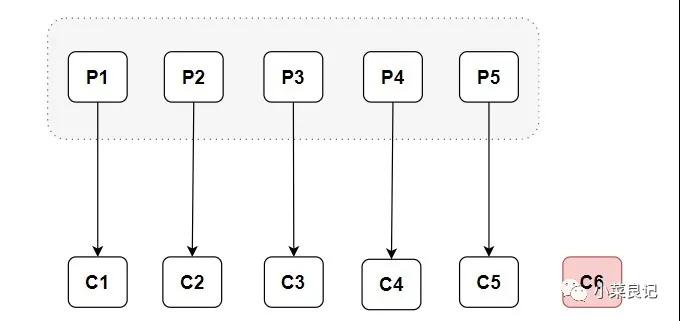
以上分配逻辑都是基于默认的分区分配策略进行分析的,可以通过消费者客户端配置partition.assignment.strategy来设置消费者与订阅主题之间的分区分配策略。
投递模式
Kafka 中有两种消息投递模式:
点对点模式(Point-to-Point)
基于队列的,消息生产者发送消息到队列,消息消费者从队列中接收消息
发布/订阅模式(Pub/Sub)
基于主题的,主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,而消息订阅者从主题中订阅消息。主题使得消息的订阅者和发布者互相保持独立,不需要进行接触即可保证消息的传递,发布/订阅模式在消息的一对多广播时采用。
客户端开发
消费过程大致得具备以下几个步骤方能消费:
- 配置消费者客户端参数以及创建相应的消费者实例
- 订阅主题
- 拉取消息并消费
- 提交消费位移
- 关闭消费者实例
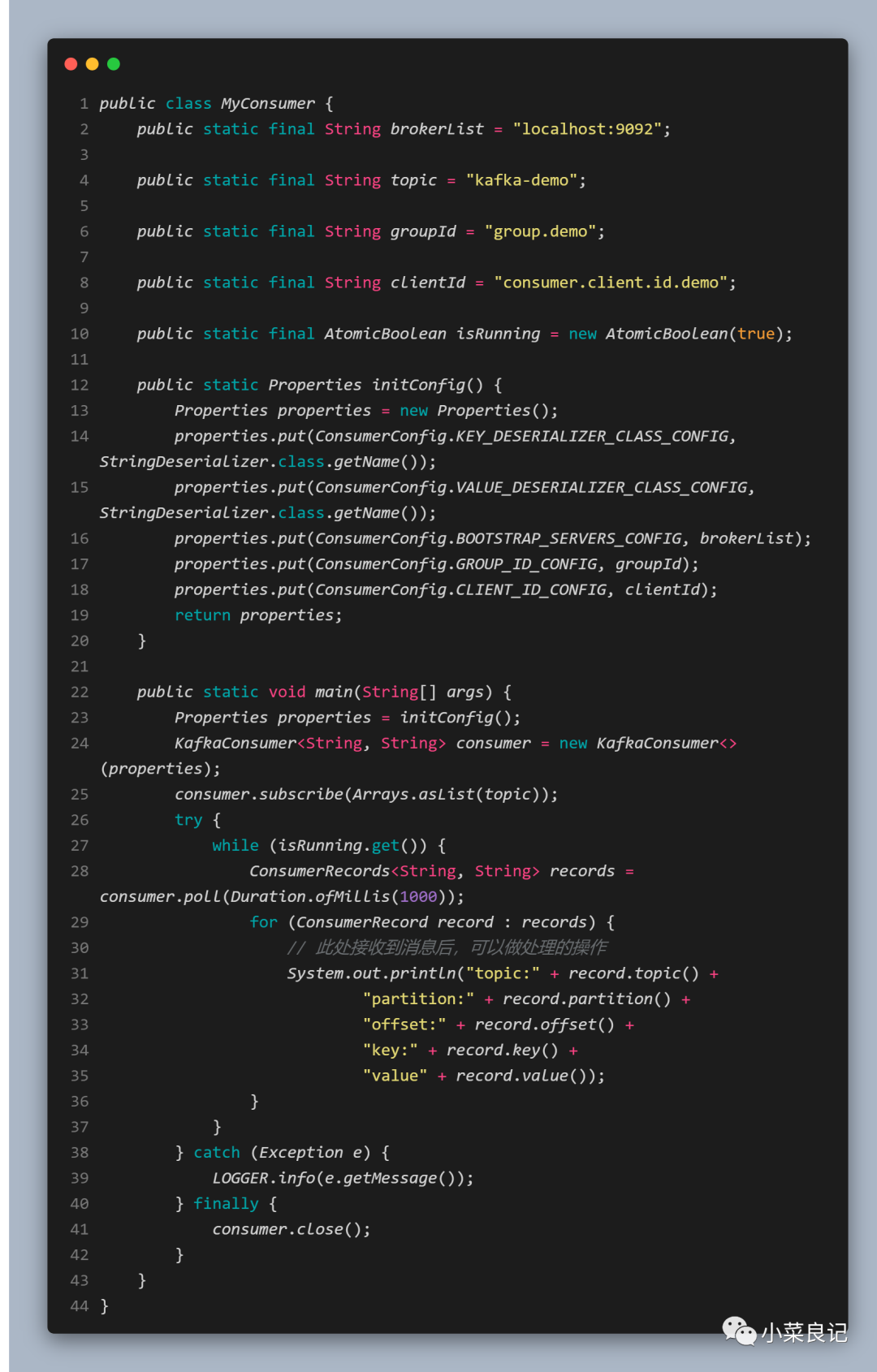
可以看出在配置消费者参数的时候,我们看到了几个熟悉的参数:
- bootstrap.servers:为了防止书写出错,可以用ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG表示,用来指定连接 Kafka 集群所需的 broker 地址清单,可以设置一个或多个地址,中间用逗号隔开,默认值为 " "
- group.id:为了防止书写出错,可以用ConsumerConfig.GROUP_ID_CONFIG表示,消费者所在消费组的名称,默认值为 " ",如果设置为空,则会抛出异常
- key.deserializer/value.deserializer:为了防止书写错误,可以用ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG和ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG表示,消费端所需要执行响应的反序列化操作,需要和生产端一致
client.id:为了防止书写错误,可以用ConsumerConfig.CLIENT_ID_CONFIG表示,用来设定 KafkaConsumer 对应的客户端 id,默认值为 " "
主题的订阅
消费者消费消息,重要的就是订阅相对应的主题。在上述的例子中我们是通过 consumer.subscribe(Arrays.asList(topic)); 来订阅主题的,可以看出一个消费者可以订阅一个或多个主题。我们来看下 subscribe() 这个方法的重载:
- public void subscribe(Collection<String> topics, ConsumerRebalanceListener listener) { /* compiled code */ }
- public void subscribe(Collection<String> topics) { /* compiled code */ }
- public void subscribe(Pattern pattern, ConsumerRebalanceListener listener) { /* compiled code */ }
- public void subscribe(Pattern pattern) { /* compiled code */ }
如果我们在订阅主题的过程中出现了以下情况:
- consumer.subscribe(Arrays.asList(topic1));
- consumer.subscribe(Arrays.asList(topic2));
那么最终情况只会订阅到 topic2,而不是topic1,更不是topic1和topic2的结合。
subscribe()这个方法重载后也支持正则表达式:
- consumer.subscribe(Pattern.compile(”topic.*”));
这样配置后,如果有人创建了新的主题,并且主题的名字与正则表达式相匹配,那么这个消费者就可以消费到新添加的主题中的消息。
subscribe()这个方法除了传入主题和正则作为参数,还有两个方法支持了 ConsumerRebalanceListener 参数的传入,这个是用来设置相应的再均衡监听器。
消费者除了可以通过subscribe()方法来订阅主题之外,还可以通过assign()方法来实现直接订阅某些主题的特定分区。
- public void assign(Collection<TopicPartition> partitions)
其中TopicPartition 对象定义如下:
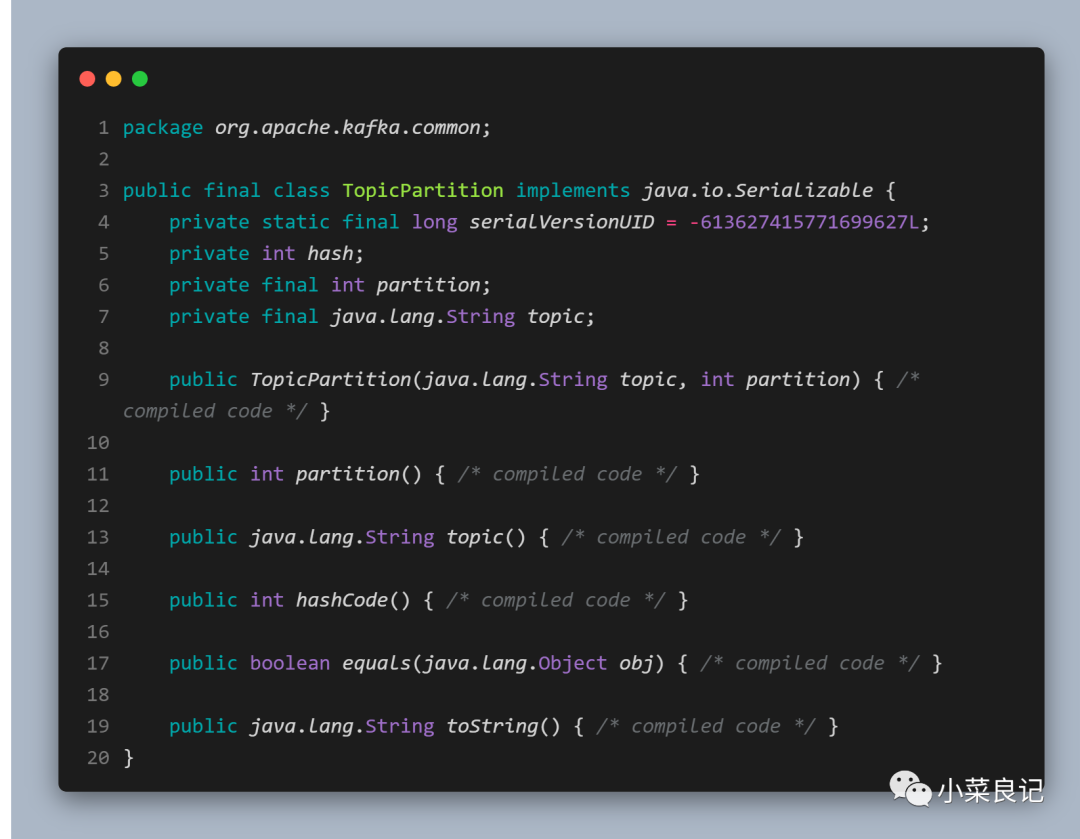
构造函数中需要传入「订阅的主题」和「分区编号」,使用如下:
- consumer.assign(Arrays.asList(new TopicPartition(”kafka-demo”, 0))) ;
这样子我们就可以订阅 kafka-demo中的 0 号分区了。
如果我们事先并不知道主题中有多少个分区怎么办?KafkaConsumer 中的 partitionsFor()方法可以用来查询指定主题的元数据信息,partitionsFor()方法定义如下:
- public List <PartitionInfo> partitionsFor(String topic);
其中 PartitionInfo对象定义如下:
- public class Partitioninfo {
- private final String topic; //主题名称
- private final int partition; //分区编号
- private final Node leader; //分区的leader副本所在的位置
- private final Node[] replicas; //分区的AR集合
- private final Node[] inSyncReplicas; //分区的ISR集合
- private final Node[] offlineReplicas; //分区的OSR集合
- }
订阅不是恶意捆绑的,能订阅就能够取消订阅,我们可以使用 KafkaConsumer 中的 unsubscribe()方法采取消主题的订阅。这个方法既可以取消通过subscribe(Collection)方式实现的订阅,也可以取消通过subscribe(Pattem)方式实现的订阅,还可以取消通过assign(Collection)方式实现的订阅 。
- consumer.unsubscribe() ;
如果将 subscribe(Collection)或 assign(Collection) 中 的集合参数设置为空集合 ,那么 作用等同于unsubscribe()方法 ,下面示例中 的三行代码的效果相同:
- consumer.unsubscribe();
- consumer.subscribe(new ArrayList<String>());
- consumer.assign(new ArrayList<TopicPartition>());
消费模式
消息的消费模式一般有两种:「推模式」和「拉模式」。而 Kafka 中的消费是基于「拉模式」
推模式:服务端主动将消息推送给消费者
拉模式:消费者主动向服务端发起拉取请求
Kafka 的消息消费是一个不断轮询的过程,消费者所要做的就是重复地调用poll()方法,如果某些分区中没有可供消费的消息,那么此分区对应的消息拉取的结果就为空;如果订阅的所有分区中都没有可供消费的消息,那么 poll()方法返回为空的消息集合。
- public ConsumerRecords<K, V> poll(final Duration timeout)
在poll()方法中可以传入一个超时时间参数 timeout,用来控制 poll()方法的阻塞时间,在消费者的缓冲区里没有可用数据时会发生阻塞。
通过poll()方法拉取到的消息是一个ConsumerRecord对象,定义如下:
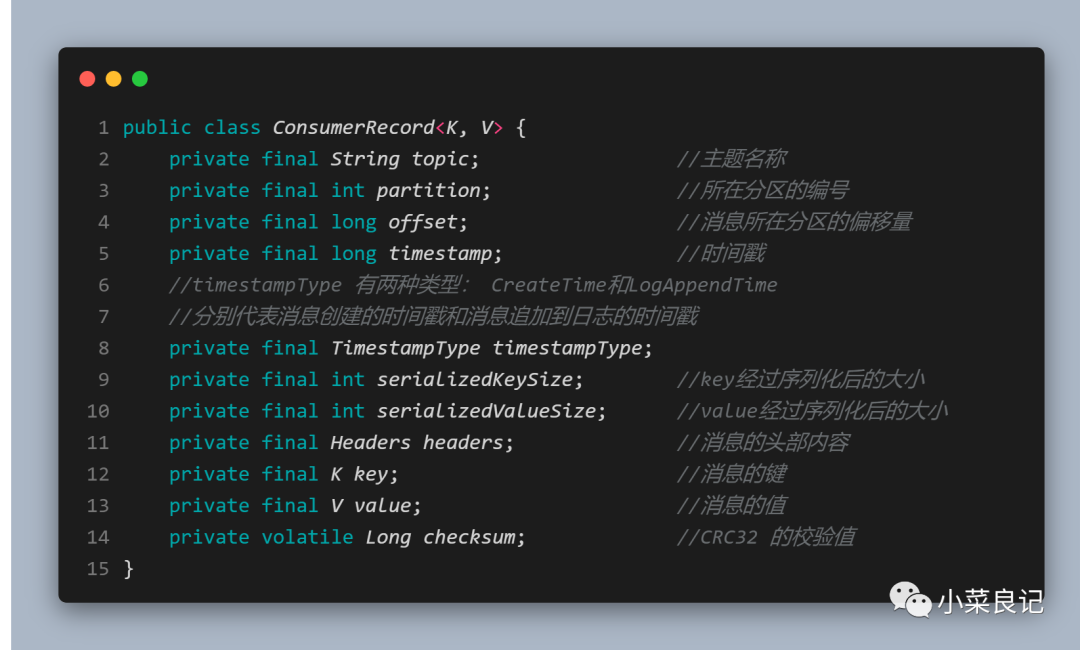
我们在消费消息的时候可以直接对 ConsumerRecord 中感兴趣的字段进行具体的业务逻辑处理。
消费者拦截器
我们上面已经讲到了生产者拦截器的使用,当然,消费者也有响应的拦截器的概念。消费者拦截器主要在消费到消息或在提交消费位移时进行一些定制化的操作。
生产者定义拦截器的方式是实现 ProducerInterceptor 接口,而消费者定义拦截器的方式则是实现ConsumerInterceptor接口,ConsumerInterceptor定义如下:
- package org.apache.kafka.clients.consumer;
- public interface ConsumerInterceptor <K, V> extends Configurable, AutoCloseable {
- ConsumerRecords<K,V> onConsume(ConsumerRecords<K,V> consumerRecords);
- void onCommit(Map<TopicPartition,OffsetAndMetadata> map);
- void close();
- }
- onConsume():KafkaConsumer 会在 poll()方法返回之前调用拦截器的 onConsume()方法来对消息进行相应的定制化操作,比如修改返回的消息内容、按照某种规则过滤消息(可能会减少poll()方法返回的消息的个数)。如果onConsume()方法中抛出异常,那么会被捕获并记录到日志中,但是异常不会再向上传递。
- onCommit():KafkaConsumer 会在提交完消费位移之后调用拦截器的 onCommit()方法,可以使用这个方法来记录跟踪所提交的位移信息,比如当消费者使用commitSync的无参方法时,我们不知道提交的消费位移的具体细节,而使用拦截器的 onCommit()方法却可以做到这一点。
我们在自定义拦截器后,也是用过相同的方式使用:
- properties.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG ,MyConsumerInterceptor.class.getName());
重要参数
除了上述已经出现的参数,还有以下一些重要的参数:
1. fetch.min.bytes
该参数用来配置 Consumer 在一次拉取请求(调用poll()方法)中能从 Kafka 中拉取的最小数据量,默认值为 1B。如果返回的数据量小于这个参数所设置的值,那么它就需要进行等待,直到数据量满足这个参数的配置大小
2. fetch.max.bytes
该参数用来配置 Consumer 在一次拉取请求中能从 Kafka 中拉取的最大数据量,默认为 52428800 B(50M)
3. fetch.max.wait.ms
该参数用来指定 Kafka 的等待时间,默认值为 500 ms
4. max.partition.fetch.bytes
该参数从来配置从每个分区里返回给 Consumer 的最大数据量,默认值为 1048576 B(1MB)
5. max.poll.records
该参数用来配置 Consumer 再一次拉取请求中拉取的最大消息数,默认值为 500 条
6. request.timeout.ms
该参数用来配置 Consumer 等待请求响应的最长时间,默认值为 30000 ms
Kafka 之 主题管理
在前面的生产者端和消费者端中我们都已经见到了「主题」的概念,「主题」是 Kafka 中的核心。
主题作为消息的归类,可以再细分为一个或多个分区,分区也可以看作对消息的二次归类。分区的划分不仅为 Kafka 提供了可伸缩性、水平扩展的功能,还通过多副本机制来为 Kafka 提供数据冗余以提高数据可靠性。
1. 创建主题
在 broker 端有个配置参数为 auto.create.topics.enable (默认值为 true),当该参数为 「true」 的时候,生产者想一个尚未创建的主题发送消息时,会自动创建一个分区数为num.partitions(默认值为1),副本因子为 default.replication.factor(默认值为1)的主题。
「使用脚本的方式创建」:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka --create --topic kafka-demo --partitions 4 --replication-factor 2
「使用 TopicCommand 创建主题」:
导出 Maven 依赖:
- <dependency>
- <groupId>org.apache.kafka</groupId>
- <artifactId>kafka_2.11</artifactId>
- <version>2.0.0</version>
- </dependency>
- public static void createTopic(String topicName) {
- String[] options = new String[]{
- "--zookeeper", "localhost:2181/kafka",
- "--create",
- "--replication-factor", "2",
- "--partitions", "4",
- "--topic", topicName
- };
- kafka.admin.TopicCommand.main(options);
- }
上述示例中,创建了一个分区数为 4,副本因子为 2 的主题
2. 查看主题
- -list:
通过list指令可以查看当前所有可用的主题:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka -list
- describe
通过describe指令可以查看单个主题信息,如果不适用 --topic 指定主题,则会展示出所有主题的详细信息。--topic还支持指定多个主题:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka --describe --topic kafka-demo1,kafka-demo2
3.修改主题
当一个主题被创建之后,我们可以对其做一定的修改,比如修改分区个数、修改配置等,借助于alter指令来实现:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter --topic kafka- demo --partitions 3
修改分区的时候我们需要注意的是:
当主题 kafka-demo 的分区数为 1 时,不管消息的 key 为何值,消息都会发往这一个分区,当分区数增加到 3 时,就会根据消息的 key 来计算分区号,原本发往分区 0 的消息现在就有可能发往分区 1 或分区 2。因此建议一开始就要设置好分区数量。
目前 Kafka 只支持增加分区数而不支持减少分区数,当我们要把主题 kafka-demo 的分区数修改为 1 时,就会报出 InvalidPartitionException 异常。
4. 删除主题
如果确定不再使用一个主题,那么最好的方式就是将其删除,这样可以释放一些资源,比如磁盘、文件句柄等。这个时候我们就可以借助 delete 指令来删除主题:
- bin/kafka-topics.sh --zookeeper localhost:2181/kafka --delete --topic kafka-demo
需要注意的是 我们必须将broker中的delete.topic.enable参数配置为 true 才能够删除主题,这个参数的默认值就是true,如果配置为 false,那么删除主题的操作将会被忽略。
如果要删除的主题是 Kafka 的内部主题,那么删除时就会报错。例如:__consumer_offsets和__transaction_state
常见参数
| 参数名称 | 释义 |
|---|---|
| alter | 用于修改主题,包括分区数以及主题的配置 |
| config<键值对> | 创建或修改主题,用于设置主题级别的参数 |
| create | 创建主题 |
| delete | 删除主题 |
| delete-config<配置名称> | 删除主题级别被覆盖的配置 |
| describe | 查看主题的详细信息 |
| disable-rack-aware | 创建主题是不考虑机架信息 |
| help | 打印帮助信息 |
| if-exists | 修改或删除主题时使用,只有当主题存在时才会执行操作 |
| if-not-exists | 创建主题时使用,只有主题不存在时才会执行动作 |
| list | 列出所有可用的主题 |
| partitions<分区数> | 创建主题或增加分区时指定分区数 |
| replica-assignment<分配方案> | 手工指定分区副本分配方案 |
| replication-factor<副本数> | 创建主题时指定副本因子 |
| topic<主题名称> | 指定主题名称 |
| topics-with-overrides | 使用describe查看主题信息时,只展示包含覆盖配置的主题 |
| 指定连接的 ZooKeeper 地址信息 |
上面大致就是 Kafka 的入门内容啦,今天的知识就介绍到这里啦,内容虽然不是很深入,但是字数也不少,能完整看完的小伙伴,小菜给你点个赞哦!