当没有足够多的数据量时该怎么办?学者们针对这一问题已经研发看各种巧妙的解决方案,以避在深度学习模型中数据少的问题。近来,在做活体检测和打 Kaggle 比赛过程中查找了很多相关文献和资料,现整理后与大家分享。一般有以下几种方法解决的数据量少的问题:
Transfer learning: 其的工作原理是在大型数据集(如 ImageNet)上训练网络,然后将这些权重用作新的分类任务中的初始权重。通常,仅复制卷积层中的权重,而不复制包括完全连接的层的整个网络。这是非常有效的,因为许多图像数据集共享低级空间特征,而大数据可更好地学习这些特征。
Self/Semi Supervised learning: 传统上,要么选择有监督的路线,然后只对带有标签的数据进行学习;要么将选择无监督的路径并丢弃标签,以进行 Self Supervised learning,而 Semi Supervised learning 这类方法就是训练模型的时候,仅需要使用少量标签和大量未标签的数据。
Few/One-shot and Zero-shot learning: Few/One-Shot Learning 目的在于从每个类别中的少量样本/一个样本中学习有关对象的特征,而 Zero-Shot Learning 的核心目标在于用训练好的模型对训练集中没有出现过的类别进行相应的预测。近些年 Few/One-Shot Learning 和 Zero-Shot Learning 技术发展迅速,模型的性能得到了大幅度的提升。
Regularization technique: 如 dropout、batch normalization 等等正则化方法也能够缓解数据量过少带来的过拟合现象。
Data Augmentation: 数据增强是根据已有的数据生成新的数据。与上述技术相反,数据增强从问题的根源(训练数据集)着手解决问题。使用数据增强方法扩展数据集不仅有助于利用有限的数据,还可以增加训练集的多样性,减少过度拟合并提高模型的泛化能力。
在本文中,我们将重点关注 Data Augmentation,因为计算机视觉是当前研究领域中最活跃的领域之一,所以,本文更聚焦于图像增强,但是其中很多技术技术都可以应用于其他领域。我们把图像的数据增强分为以下 4 类:
-
Basic Image
-
Geometric Transformations
-
Color Space Transformations
-
RandomRrase/GridMask
-
Mixup/Cutmix
-
Mosaic
-
-
Feature space augmentation
-
MoEx
-
-
GAN-based Data Augmentation
-
NAS
-
AutoAugment
-
Fast AutoAugment
-
DADA
-
-
Other
-
UDA
-
基本图像处理的扩增
常见的就是对图像进行几何变换,图像翻转,裁剪,旋转和平移等等,还可以使用对比度,锐化,白平衡,色彩抖动,随机色彩处理和许多其他技术来更改图像的色彩空间。
此外,还可以使用遮挡类的方法,如 CutOut、RandomRrase、GridMask。Cutmix 就是将一部分区域 cut 掉但不填充 0 像素而是随机填充训练集中的其他数据的区域像素值,分类结果按一定的比例分配,CutMix 的操作使得模型能够从一幅图像上的局部视图上识别出两个目标,提高训练的效率。
而 Mosaic 数据增强方法是 YOLOV4 论文中提出来的,主要思想是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据,这样做的好处是丰富了图片的背景。
基础的图形扩增方法在很多深度学习框架中都有实现,例如:torchvision。还有一些更加全面丰富的数据扩增库,如 albumentations 等等。
特征空间扩增

论文标题: On Feature Normalization and Data Augmentation(MoEx)
论文链接: https://arxiv.org/abs/2002.11102
代码链接: https://github.com/Boyiliee/MoEx
在上面的示例中,我们在图像空间上进行变换,此外,还可以在特征空间中变换。借助神经网络,我们可以非常有效地以低维或高维的形式表示图像,这样,中间的潜在张量包含有关数据集的所有信息,并且可以提取出来做各种事情,包括数据增强。MoEx 这篇文章作者在特征空间进行增强的尝试。具体做法如下图所示:
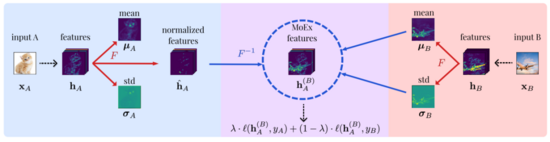
1. 对 hA 做 normalization 的到 hˆA,然后计算 hB 的 µB,σB
2. 接着对 hˆA 反归一化如下:
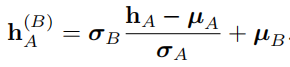
3. 使用新的损失函数计算 loss:
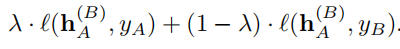
MoEx 的实验包括:ImageNet、Speech Commands、IWSLT 2014、ModelNet40 等。可以说涵盖了图像、NLP、语音三大领域,可见其优点很明显,由于是在特征空间做数据增强,所以不受输入数据类型的限制,对于图像、音频以及文本等数据具有通用性。
GAN-based Data Augmentation
生成建模是当前最火的技术之一,生成模型学习数据的分布,而不是数据之间的边界,因此,可以生成全新的图像。
GAN 由两个网络组成:生成器和鉴别器。生成器的工作是生成仅具有噪声作为输入的伪造数据。鉴别器接收真实图像和伪图像(由发生器产生)作为输入,并学会识别图像是伪图像还是真实图像。
随着两个网络相互竞争,在对抗训练的过程中,生成器在生成图像方面变得越来越好,因为其最终目标是欺骗鉴别器,而鉴别器在区分伪造品和真实图像方面变得越来越好,因为它的目标是不被欺骗,最终生成器生成了令人难以置信的真实伪数据。
需要说明的是,GAN 生成的数据是要因地制宜。据说在这篇文章右下角 double click 的同学会有奇效(哈哈)。

论文标题: Emotion classification with data augmentation using generative adversarial networks.
论文链接: https://arxiv.org/abs/1711.00648

本文在情绪识别验证了 GAN 做数据扩增的有效性。情绪识别数据集 FER2013 包含了7种不同的情绪:愤怒,厌恶,恐惧,快乐,悲伤,惊奇和中立。,这些类是不平衡的。而本文使用 CycleGAN 将其他几类的图像转换为少数类的样本,使得模型准确性提高了 5-10%。

论文标题:Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro
论文链接:https://arxiv.org/abs/1701.07717
代码链接:https://github.com/layumi/Person-reID_GAN
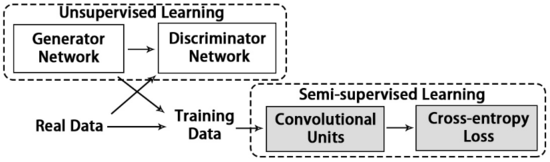
这篇文章想法在当时情况下还是比较好的。没有 ReID 的 GAN,那就用原始数据训练一个 GAN,然后生成图片,没有标签就用 ReID 网络生成 pseudo label。这样一来,就从监督学习转化为了半监督学习。
NAS-based Data Augmentation
数据增强方法在各个领域都得到了广泛应用,不过即使在一些特定的数据集已经找到了适合的数据增强方法,但这些方法通常也不能有效地转移到其他数据集上去。
例如,由于不同数据集中存在不同的对称性要求,在 CIFAR-10 数据集上训练阶段水平翻转图像是的有效数据增强方法,但对 MNIST 却不适用。因而, 让网络自主的寻找数据增强方法逐渐成为一种无论是学术或者工程上都不可或缺的需求。
Google DeepMind 率先提出了利用 NAS 的方法 AutoAugment,在数据增强的策略搜索空间中利用数据集上评定特定策略的质量,自动搜索出合适的数据增强的策略。相关的文献还有:Fast AutoAugment 以 及 DADA 等等。

论文标题:
AutoAugment: Searching for best Augmentation policies Directly on the Dataset of Interest
论文链接:
https://arxiv.org/abs/1805.09501
代码链接:
https://github.com/tensorflow/models/tree/master/research/autoaugment
AutoAugment 是 Google 提出的自动选择最优数据增强方案的研究,它的基本思路是使用强化学习从数据本身寻找最佳图像变换策略,对于不同的任务学习不同的增强方法。流程如下:
AutoAugment 的控制器决定当前哪个增强策略看起来最好,并通过在特定数据集的一个子集上运行子实验来测试该策略的泛化能力。在子实验完成后,采用策略梯度法 (Proximal policy Optimization algorithm, PPO),以验证集的准确度作为更新信号对控制器进行更新。
总的来说,控制器拥有 30 个 softmax 来分别预测 5 个子策略的决策,每个子策略又具有 2 个操作,而每个操作又需要操作类型,幅度和概率。
而数据增强操作的搜索空间一共有 16 个:ShearX/Y,TranslateX/Y,Rotate,AutoContrast,Invert,Equalize,Solarize,Posterize,Contrast,Color,Brightness,Sharpness,Cutout,Sample Pairing。
在实验中发现 AutoAugment 学习到的已有数据增强的组合策略,对于门牌数字识别等任务,研究表明剪切和平移等几何变换能够获得最佳效果。而对于 ImageNet 中的图像分类任务,AutoAugment 学习到了不使用剪切,也不完全反转颜色,因为这些变换会导致图像失真。AutoAugment 学习到的是侧重于微调颜色和色相分布。
AutoAugment 的方法在很多数据集上达到 state-of-the-art 的水平。在 CIFAR-10 上,实现了仅 1.48% 的错误率,比之前 state-of-the-art 的方法又提升了 0.65%;
在 SVHN 上,将 state-of-the-art 的错误率从 1.30% 提高到 1.02%;在一些 reduced 数据集上,在不使用任何未标记数据的情况下实现了与半监督方法相当的性能;在 ImageNet 上,实现了前所未有的 83.54% 的精度。
Other
在上面我们介绍了一些对有监督的数据进行数据增强的方法,但是对有监督的数据进行数据增强大多被认为是“蛋糕上的樱桃”,因为虽然它提供了稳定但是有限的性能提升,下面,将介绍一种半监督技术中的数据增强方法。

论文标题:Unsupervised Data Augmentation for Consistency Training(UDA)
论文链接:https://arxiv.org/abs/1904.12848
代码链接:https://github.com/google-research/uda
UDA 训练过程如下图所示:
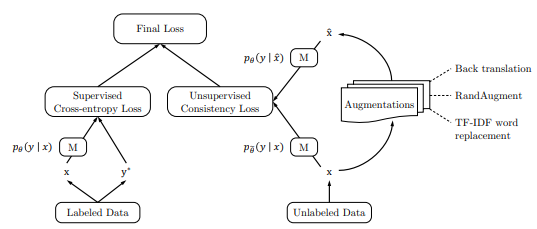
1. 最小化未标记数据和增强未标记数据上预测分布之间的 KL 差异:
其中,x 是原始未标记数据的输入,x^ 是对未标签数据进行增强(如:图像上进行裁剪、旋转,文本进行反翻译)后的数据。
2. 为了同时使用有标记的数据和未标记的数据,添加了标记数据的 Supervised Cross-entropy Loss 和(1)中定义的一致性/平滑性目标 Unsupervised Consistency Loss,权重因子 λ 为我们的训练目标,最终目标的一致性损失函数定义如下:
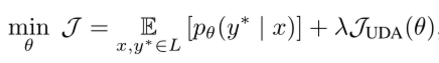
此外,UDA 为了解决未标记的数据和标记数据不平衡导致数据过拟合的问题,提出了新的训练技巧 Training Signal Annealing 简称 TSA,TSA 的思路是随着模型被训练到越来越多的未标记数据上,逐渐减少标记数据的训练信号,而不会过度拟合它们。实验结果方面,UDA 在很大程度上优于现有的半监督学习方法。
总结
众所周知,深度学习的模型训练依赖大量的数据。如果没有训练数据,那么即使是优秀的算法也基本上很难发挥作用。本文总结了几种方法常见的解决的数据量少的问题的方法,并对 Data augment 进行了详细的总结,希望对您有所帮助。