深度学习的参数太多、模型太大、部署不方便、消耗的计算资源过多,种种原因加大了深度学习爱好者的「贫富差距」。然而算法优化一直在路上……
Google 团队提出的 NLP 经典之作 Transformer 由 Ashish Vaswani 等人在 2017 年发表的论文《Attention Is All You Need》 中提出。但由于模型参数量过大,该模型训练困难、部署不方便,研究人员一直在探究如何优化 Transformer。近日,来自华盛顿大学和 FAIR 的 Sachin Mehta 等人提出了一个网络结构较深但轻量级的 Transformer——DeLighT。

论文链接:https://arxiv.org/abs/2008.00623
代码链接:https://github.com/sacmehta/delight
论文简介
在这篇文章中,作者提出了一个网络较深但轻量级的 Transformer——DeLighT,与之前基于 transformer 的模型相比,它的参数更少,但性能相当甚至更好。
DeLighT 能够更高效地分配参数,主要表现在:1)每个 Transformer 块使用结构较深但参数较少的 DExTra;2)在所有块上使用逐块缩放(block-wise scaling),使靠近输入的 DeLighT 块比较浅且窄,靠近输出的 DeLighT 块比较宽且深。总的来说,DeLighT 的网络深度是标准 transformer 模型的 2.5 到 4 倍,但参数量和计算量都更少。
DeLighT 的核心是 DExTra 变换(DExTra transformation),该变换使用组线性变换和扩展 - 缩小(expand-reduce)策略来有效地改变 DeLighT 块的宽度和深度。由于这些变换本质上是局部的,因此 DExTra 利用特征 shuffling(类似于卷积网络中的通道 shuffling)在不同组之间共享信息。这种宽且深的表示有助于用单头注意力和轻量级前馈层替换 transformer 中的多头注意力和前馈层,从而减少网络参数量。重要的是,与 transformer 不同,DExTra 模块可以独立于输入大小进行缩放。通过使用靠近输入的较浅和窄的 DeLighT 块以及靠近输出的较深和宽的 DeLighT 块,在各个块之间更高效地分配参数。
DeLighT 三大特点
改进 transformer:与之前的工作不同,该论文展示了对每个 Transformer 块使用 DExTra 以及基于所有块使用逐块缩放时,能够实现参数的高效分配。结果显示,DeLighT 在参数更少的情况下,能达到相同的效果甚至更好。
模型压缩:为了进一步提高序列模型的性能,该研究引入了逐块缩放,允许每个块有不同的尺寸,以及更高效地进行参数分配。
改进序列模型:与 DeLighT 最接近的工作是 DeFINE 单元,它使用扩展 - 缩减策略学习模型表示。DeFINE 单元(图 1a)和 DExTra(图 1b)之间的关键区别是,DExTra 能更高效地在扩展 - 缩减层中分配参数。DeFINE 在组线性变换中使用较少的组来学习更宽的表示,而 DExTra 使用较多的组和较少的参数来学习更宽的表示。
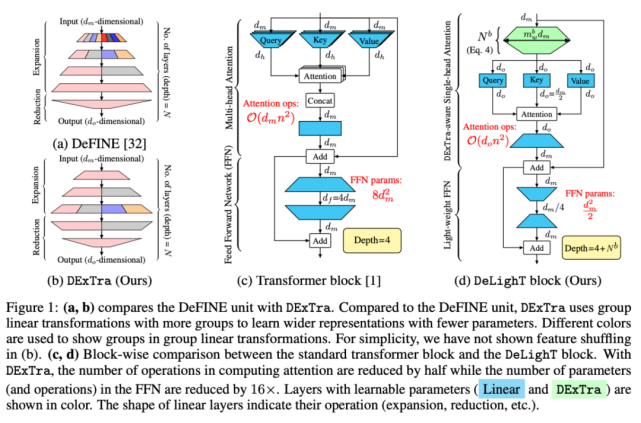
图 1:(a, b) DeFINE 单元和 DExTra 之间的对比。(c, d) 标准 transformer 模块与 DeLighT 模块中的 block-wise 对比。
DeLighT:网络很深但参数较少的 Transformer
DExTra
DExTra 变换由五个配置参数控制:1)深度 N,2)宽度乘数 m_w,3)输入维数 d_m,4)输出维数 d_o,5)组线性变换中的最大组 g_max。
在扩展阶段,DExTra 使用「N/2」层线性地将 d_m 维输入投影到高维空间,d_max = m_wd_m。在缩减阶段,DExTra 使用剩余的 N − 「N/2」层,将 d_max 维向量投影到 d_o 维空间。在数学上,每一层 l 的输出 Y 可定义为:
每一层 l 的组数则按照以下公式计算:
DeLighT 模块
Transformer 块:标准 transformer 块(图 1c)由多头注意力组成,使用查询 - 键 - 值(query-key-value)分解来建模序列 token 之间的关系,并使用前馈网络(FFN)来学习更宽的表示。
DeLighT 块:图 1d 展示了如何将 DExTra 集成到 transformer 块中以提高效率。首先将 d_m 维输入馈入 DExTra 变换,产生 d_o 维输出,其中 d_o < d_m。然后将这些 d_o 维输出馈送至单头注意力,紧接着使用轻量级 FFN 来建模它们的关系。
DExTra 单头注意力:假设输入序列有 n 个 token,每个 token 的维数为 d_m。首先将这 n 个 d_m 维输入馈送到 DExTra 变换,以生成 n 个 d_o 维输出,其中 d_o
DeLighT 块通过 DExTra 学习到较宽的输入表示,这就使得单头注意力能够代替多头注意力。标准 transformer 以及 DeLighT 块中注意力的计算成本分别为 O(d_mn^2 )、O(d_on^2 ),d_o
轻量级 FFN:与 transformer 中的 FFN 相似,该模块也由两个线性层组成。由于 DeLighT 块已经使用 DExTra 变换集成了较宽的表示,因此我们可以反转 transformer 中 FFN 层的功能。第一层将输入的维数从 d_m 减小到 d_m / r,第二层将输入维数从 d_m / r 扩展到 d_m,其中 r 是减小因子(见图 1d)。该研究提出的轻量级 FFN 将 FFN 中的参数和计算量减少到原来的 rd_f / d_m。在标准 transformer 中,FFN 维度扩大了 3 倍。而在该研究实验中,维度缩小了 3 倍。因此,轻量级 FFN 将 FFN 中的参数量减少到了原来的 1/16。
逐块缩放
改善序列模型性能的标准方法包括增加模型维度(宽度缩放)、堆叠更多块(深度缩放),或两者兼具。为了创建非常深且宽的网络,该研究将模型缩放扩展至块级别。下图 2 比较了均匀缩放与逐块缩放:
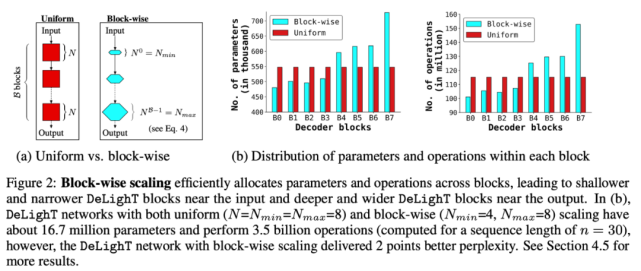
缩放 DeLighT 块:DeLighT 块使用 DExTra 学习深且宽的表示,DExTra 的深度和宽度由两个配置参数控制:组变换层数 N 和宽度乘数 m_w(图 2a)。这些配置参数能够在独立于输入 d_m 和输出 d_o 维度的情况下,增加 DeLighT 块内的可学习参数数量。此处,该论文使用逐块缩放来创建具有可变大小的 DeLighT 块网络,在输入附近分配较浅且窄的 DeLighT 块,在输出附近分配更深且宽的 DeLighT 块。
为此,该研究提出两个配置参数:DeLighT 网络中 DExTra 的最小深度 N_min 和最大深度 N_max。然后,使用线性缩放(公式 4)计算每个 DeLighT 块 b 中 DExTra 的深度 N^b 和宽度乘数 m^b_w。通过这种缩放,每个 DeLighT 块 b 都有不同的深度和宽度(图 2a)。
实验结果
该论文在两个常见的序列建模任务(机器翻译和语言建模)上进行了性能比较。
机器翻译
该研究对比了 DeLighT 和当前最优方法(标准 transformer [1]、动态卷积 [21] 和 lite transformer [22])在机器翻译语料库上的性能,如下图 3 所示。图 3c 表明,DeLighT 提供了最优的性能,在参数和计算量较少的情况下性能优于其他模型。
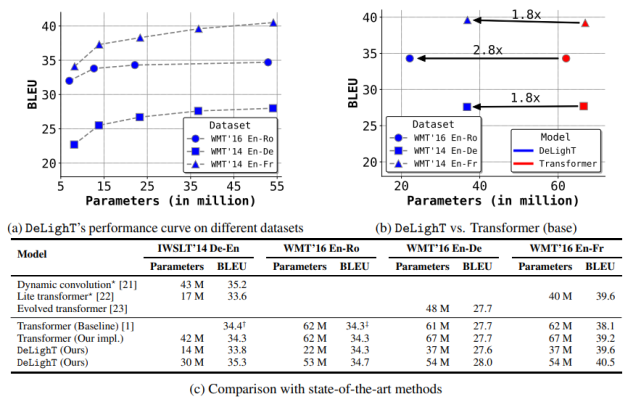
图 3:模型在机器翻译语料库上的结果。与标准 transformers 相比,DeLighT 模型用更少的参数就能达到类似的性能。图中 † 和 ‡ 分别表示来自 [21] 和 [48] 的最优 transformer 基线。
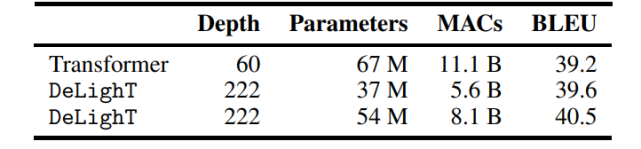
表 1:在 WMT’14 En-Fr 数据集上,机器翻译模型在网络深度、网络参数、MAC 数量和 BLEU 值方面的对比结果。DeLighT 表现最优异,在网络深度较深的情况下,参数量和运算量都更少。
语言建模
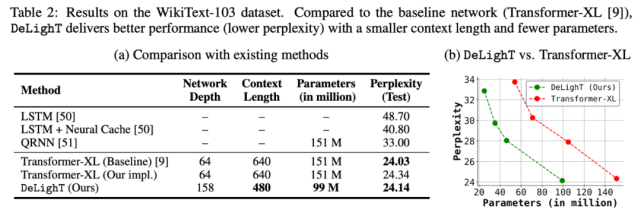
该研究在 WikiText-103 数据集上,对 DeLighT 和其他方法的性能进行了对比(如表 2a 所示)。表 2b 则绘制了 DeLighT 和 Transformer-XL [9] 的困惑度随参数量的变化情况。这两个表都表明,DeLighT 优于当前最优的方法(包括 Transformer-XL),而且它使用更小的上下文长度和更少的参数实现了这一点,这表明使用 DeLighT 学得的更深且宽的表示有助于建模强大的上下文关系。
控制变量研究
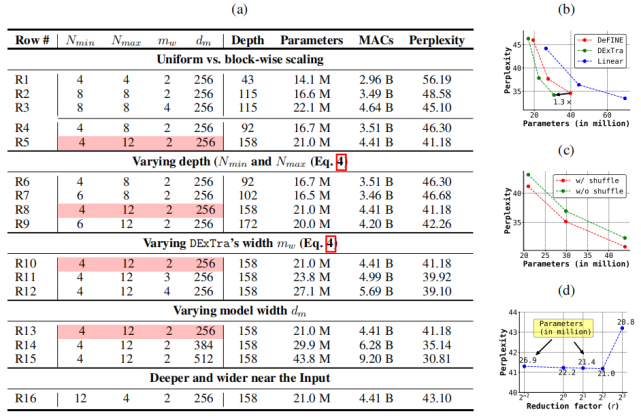
表 3a 研究了 DeLighT 块参数的影响,这些参数分别是网络最小深度 N_min、最大深度 N_max、宽度乘法 m_w 和模型维度 d_m(见图 1d)。表 3b-d 分别展示了 DExTra 变换、特征 shuffling 和轻量级 FFN 的影响。
总结
该研究提出了一种非常轻巧但深度较大的 transformer 框架——DeLighT,该框架可在 DeLighT 块内以及对所有 DeLighT 块高效分配参数。与当前最优的 Transformer 模型相比,DeLighT 模型具备以下优点:1)非常深且轻量级;2)提供相似或更好的性能。