












隐私保护是机器学习领域的重要伦理问题之一,而差分隐私(DP)是行之有效的隐私保护手段。那么,如何方便地使用差分隐私来训练机器学习模型呢?近日,Facebook 开源了 Opacus 库,支持以这种方式训练 PyTorch 模型。
近日,Facebook 开源了一个新型库 Opacus,它支持使用差分隐私来训练 PyTorch 模型,扩展性优于目前的 SOTA 方法。同时,Opacus 库支持以最少代码更改来训练模型,且不会影响训练性能,并允许在线跟踪任意给定时刻的隐私预算。

Opacus 库开源地址:https://github.com/pytorch/opacus
Opacus 库的目标受众主要为以下两类人群:
机器学习从业者:可以使用该库轻松了解如何利用差分隐私训练模型,该库支持以最少代码更改来训练模型;
差分隐私科学家:Opacus 库易于实验和修复,这允许他们专注于更重要的事。
差分隐私是一个具备数学严谨性的框架,可用于量化敏感数据的匿名化。Facebook 在相关博客中表示,希望 Opacus 库能为研究人员和工程师提供一条更简单的途径,以便在 ML 中使用差分隐私,并加快该领域的 DP 研究。
Opacus 库提供了什么?
通过这个开源的高速库 Opacus,你可以得到:
速度:利用 PyTorch 中的 Autograd hook,Opacus 能够批量化计算每个样本的梯度。与依赖 microbatching 的现有 DP 库相比,Opacus 实现了一个数量级的加速。
安全性:Opacus 对其安全关键代码使用密码学安全伪随机数生成器 CSPRNG,在 GPU 上对整批参数进行高速处理。
灵活性:基于 PyTorch,工程师和研究人员可以通过将 Opacus 代码与 PyTorch 代码和纯 Python 代码进行融合和匹配,快速为其 idea 构建原型。
生产效率:Opacus 库附带教程、在训练开始前提示不兼容层的辅助函数,以及自动重构机制。
交互性:Opacus 可以追踪用户在任意给定时间所花费的隐私预算(DP 的核心数学概念),从而实现早停和实时监控。
Opacus 通过引入 PrivacyEngine abstraction 定义了一个轻量级的 API,它既可以追踪隐私预算,也能够处理模型梯度。该 API 无需直接调用,只需将其连接至标准 PyTorch 优化器。该 API 在后台运行,这使得利用 Opacus 进行模型训练变得非常简单。用户只需在训练代码开头添加以下代码即可:
训练结束,即得到一个标准的 PyTorch 模型,并且它没有部署私有模型的额外步骤或障碍:如果今天就想部署模型,你可以在使用 DP 训练模型后进行部署,且无需更改一行代码。
Opacus 库还包括预训练和微调模型、针对大型模型的教程,以及为隐私研究实验而设计的基础架构。
如何使用 Opacus 实现高速隐私训练?
Opacus 旨在保留每个训练样本的隐私,同时尽量不影响最终模型的准确率。Opacus 通过修改标准 PyTorch 优化器来实现这一点,以便在训练过程中实现(和度量)差分隐私。
具体来说,Opacus 的重点是差分隐私随机梯度下降(DP-SGD)。该算法的核心思想是:通过干预模型用来更新权重的参数梯度来保护训练集的隐私,而不是直接获取数据。通过在每次迭代中向梯度添加噪声,该库可以防止模型记住训练样本,同时还可以实现在 aggregate 中的学习。在训练过程的多个批次中,(无偏)噪声自然会被抵消。
但是,添加噪声需要一种微妙的平衡:噪声过多会破坏信号,过少则无法保证隐私。为了确定合适的规模,我们需要查看梯度范数。限制每个样本对梯度的影响非常重要,因为异常值的梯度大于大部分样本。但是异常值的隐私也需要得到保护,因为它们极有可能被模型记住。
因此,开发者计算 minibatch 中每个样本的梯度。开发者分别对每个梯度进行梯度裁剪,将其累积到一个梯度张量,然后再将噪声添加其中。
基于每个样本的计算是构建 Opacus 的最大障碍之一。PyTorch 的典型操作是利用 Autograd 计算整个批次的梯度张量,因为这对其他机器学习用例都有意义,并且可以优化性能。与之相比,基于每个样本的计算显然更具挑战性。
为了克服这一困难,开发者利用 Ian Goodfellow 2015 年提出的高效技术(参见论文《EFFICIENT PER-EXAMPLE GRADIENT COMPUTATIONS》),获取训练标准神经网络所需的全部梯度向量。
至于模型参数,则单独返回给定批次中每个样本的损失梯度,整个过程如下所示:
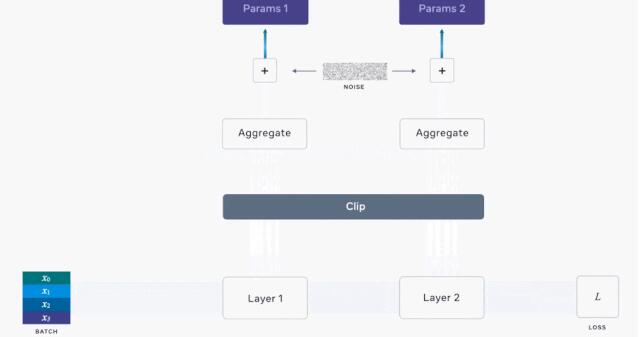
Opacus 工作流程图,其中计算了每个样本的梯度。
通过在运行各层时追踪一些中间量,Opacus 库支持使用适合内存的任何批量大小进行训练。这使得该方法比其他替代性 micro-batch 方法快了一个数量级。
此外,Opacus 库的安装和使用过程也比较简单,详情参见 GitHub 项目。


















