缓存的使用,是一个逐渐演进的过程。问一下你自己,最直接的使用缓存的原因是什么?无它,唯快而已!
追溯一下自己最开始使用缓存的场景,一些数据库里存储的不变的配置信息,服务启动时,直接加载到本地公共模块,方便其它功能模块共享使用。这便是最基本,最简单的本地缓存应用。
服务与缓存
所谓的服务,简而言之,一层应用+一层数据,应用从数据层获取数据然后加工输出。
数据层,通常我们指的是持久化介质上的持久化存储。它有多种形式的,可以是文件,或者数据库。
数据存储在持久化介质上,而应用运行与内存中。内存和持久化介质是两个有着量级速度差别的不同介质,由此,应用和数据之间便有了“矛盾”。
有了这“矛盾”的引子,便有了对缓存的迫切需求。
我们说的缓存,必然要是存放于内存中的,这样它便能距离应用更近,更快的给出应用所需要的数据,以获得更快的服务响应。
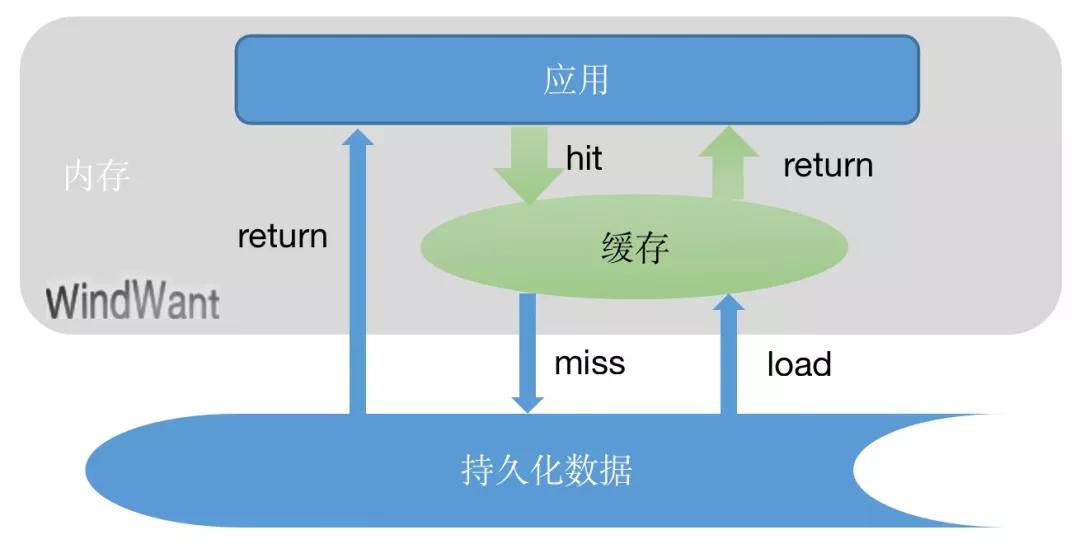
当然,并不是缓存完全隔绝持久层数据。缓存,伴随而生的一个词叫做命中率。
当我们查询的数据存在于缓存中的时候,我们称之为“命中”,此时,所需数据可以直接由缓存提供。
而对于未“命中”的数据,则需要穿过缓存层,进一步去持久化数据层获取。此种情景,我们称之为缓存穿透。
数据获取之后,在返回给应用之前,我们需要重新填充缓存,以供下一次“命中”查询。
当然,上述我们所述只是指“读”查询情景。当应用发生数据操作变更,我们则需要将变更同时更新到持久层及缓冲层。
此时,我们又会面临另外一个问题,“先”与“后”的问题。
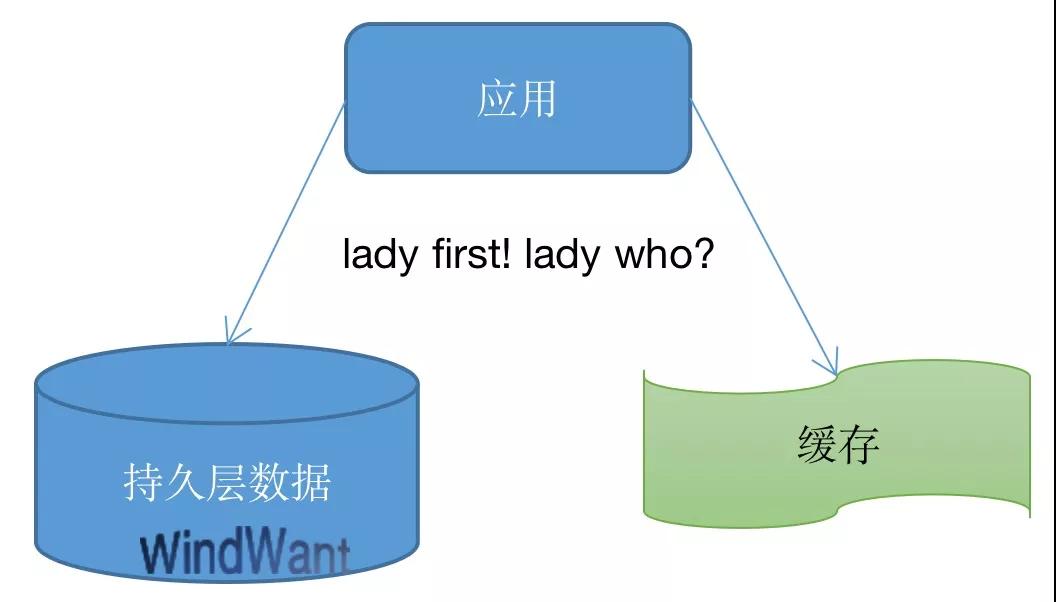
“先”与“后”的问题,我们也称之为缓存一致性问题。如果先更新缓存,则可能面临持久层更新失败,产生缓存脏数据的问题。
然则,假如先更新持久层,我们又不得不面对从持久层更新成功之后到缓存更新之前这个间期,缓存对外提供旧数据的窘境。
缓存一致性问题,尤其在高并发环境,需要根据特定场景进行更精妙的控制。比如,并发修改的一致性锁;比如,异步刷新的延迟刷新等等。
缓存与更新
上文我们提到了缓存更新一致性的问题,从实际应用情景来讲,可以细分为强一致性需求,弱一致性需求及最终一致性需求。
强一致性需求
比如,交易状态信息,已下单、支付中,已支付等应用,需要我们主动及时进行关联更新并保证事务层面的一致性。
应景而生的许多包括分布式事务等理论也为我们解决实际问题提供了很好的践行方案。
弱一致性需求
一些涉及不太重要的信息更新,能够容忍短时间(比如,几分钟)内持久层数据和缓存数据不一致的场景。
比如不外显的描述信息,统计性的计数缓存信息等。通常可以采取异步处理的方式。
一些一段短时间内(几秒,几分钟)输出固定信息的场景。比如每隔 30s 更新热点信息,票价信息等。可以通过设置缓存超时自动剔除的方式进行处理。
最终一致性需求
保障数据状态的最终一致性。
缓存的粒度
所谓粒度,也即缓存信息块层级,大小。选择何种粒度的缓存,取决于我们应用的整体架构,数据存储规划及具体的应用场景。
拿用户信息来举例,是缓存活跃信息?还是相对静态的信息?是按单属性层级来缓存?还是按整个对象信息?
不同的数据粒度,也决定着我们存储缓存的形式:整个对象的二进制序列化数据?更透明直观的 json 字符串?属性与值的一一映射?
每种形式都有各自的使用优缺点,开发者可以从应用、存储及维护成本各方面进行全面性评估选择。
缓存穿透的危害
前面我们提到过关于缓存穿透发生的原因:缓存未命中。那为什么会未命中呢?
数据暂时不存在于缓存中
所谓暂时,可以指数据初始尚未加载到缓存,lazy load 按需按时实时加载应用。
也可以是缓存数据被我们特定的缓存过期策略自动或主动过期,通常使用的过期策略包括元素数量限制,内存占用限制及生存时间限制。
其实,无论是初始未加载还是缓存过期,删除,这些都属于我们假定的正常应用场景,再次我们不予过多评论。
数据从来不存在
当一个查询不存在数据的请求到来,其必然会穿过缓存,达到持久化存储层。
持久化存储的响应能力是有限的,当这种请求达到一定的量级,服务可能就要面临着宕机的危险。
至此,我们对于缓存的作用认知,也需要进一步延伸:降低下层负载,保护后端资源。
造成这种缓存穿透的原因可以简单的分为内外两方面诱因:内部的应用逻辑问题及外部恶意攻击、爬虫干扰等。
内部问题容易解决,内观可预知,良性优化即可;反而是外部的不可预料,可能需要更谨慎的进行多面的防御性处理。
其实,不论内部还是外部,在缓存层面需要处理的就只有一件事:有效拦截穿透。
到此,通常惯性的思维第一步,就是把造成缓存穿透的数据放置到缓存中,无论其是否存在在于持久化存储中。
比如对于正常的已删除的用户数据,做缓存层面的软删除处理,以状态信息做标注(我存在,其实我不存在!😳)。就可以很好的解决此类问题造成的穿透压力。
但是,我们有也个清楚的认知就,就是真正能够造成危害的是那些非正常的入侵数据。
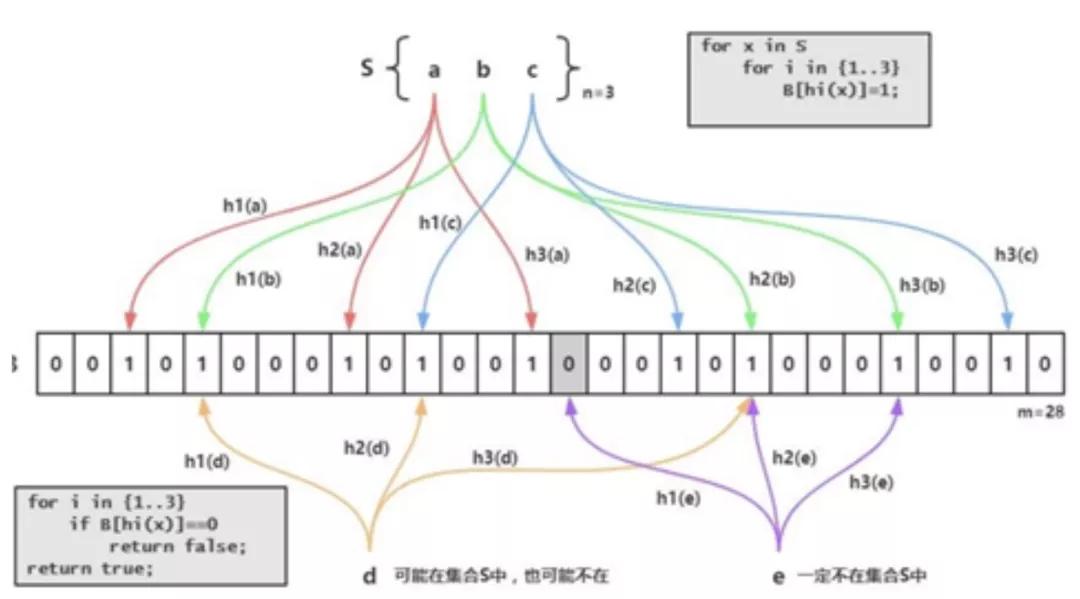
比如,穷尽遍历的差别数据,一一存入缓存,唯一的结果就是缓存资源的溢满用尽。这是一种相当恐怖的场景。
针对此种“大数据”型攻击,布隆过滤拦截或许可以成为一个不错的选择。
也谈缓存雪崩
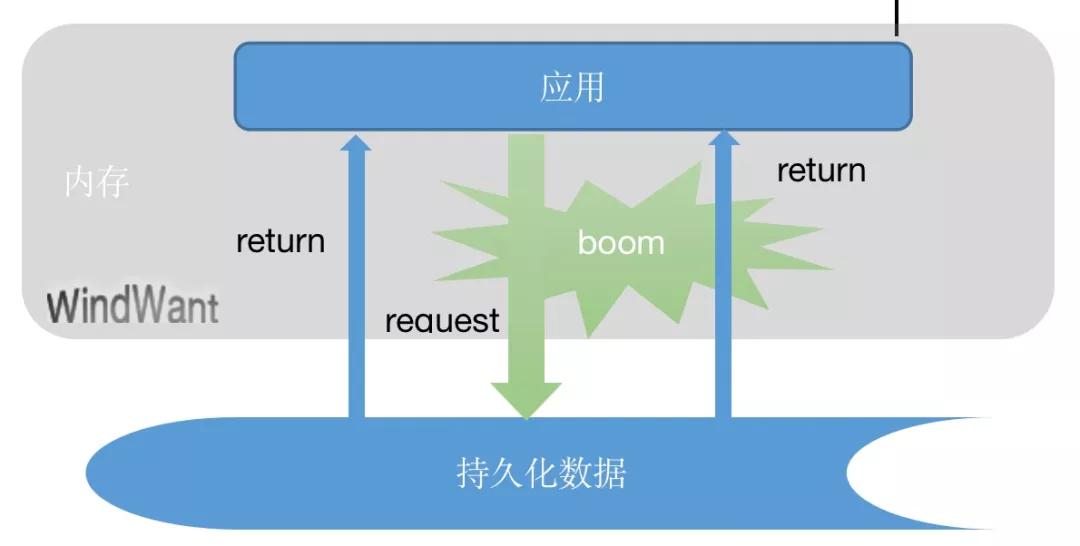
上面一节中我们谈到了缓存的承载保护功能,一面快速响应,一面背负保护持久层数据。在某些以读为主的服务中,缓存几近承载近乎 90% 以上的请求。
但是,如果缓存由于某些原因一时不能提供正常服务时,所有的请求就会穿透到持久存储层,造成存储层极端宕机情况发生。
那么,我们应该如何应对这种情况呢?
高可用
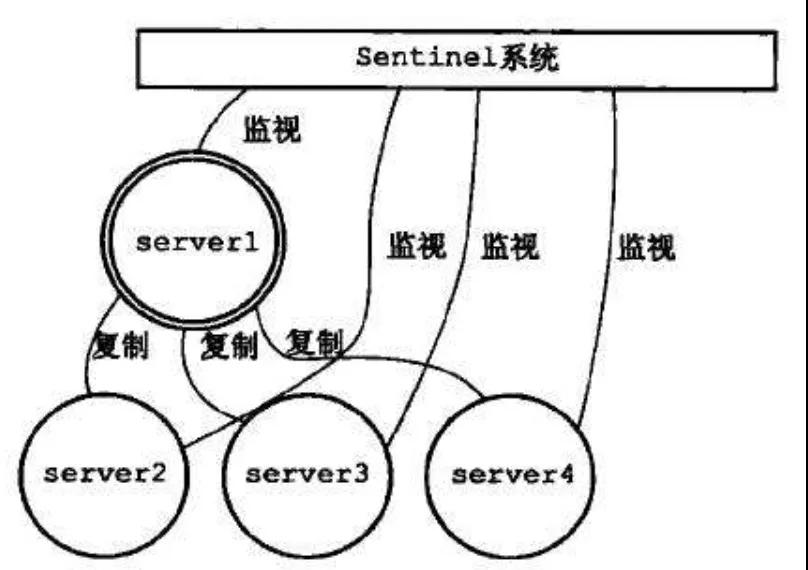
缓存的高可用是应对缓存雪崩的首要保障:主从,读写分离,动态扩容,一致性均衡,异地容灾等。
实际应用如 Redis 的哨兵模式,集群部署等:
服务治理之限流、熔断降级
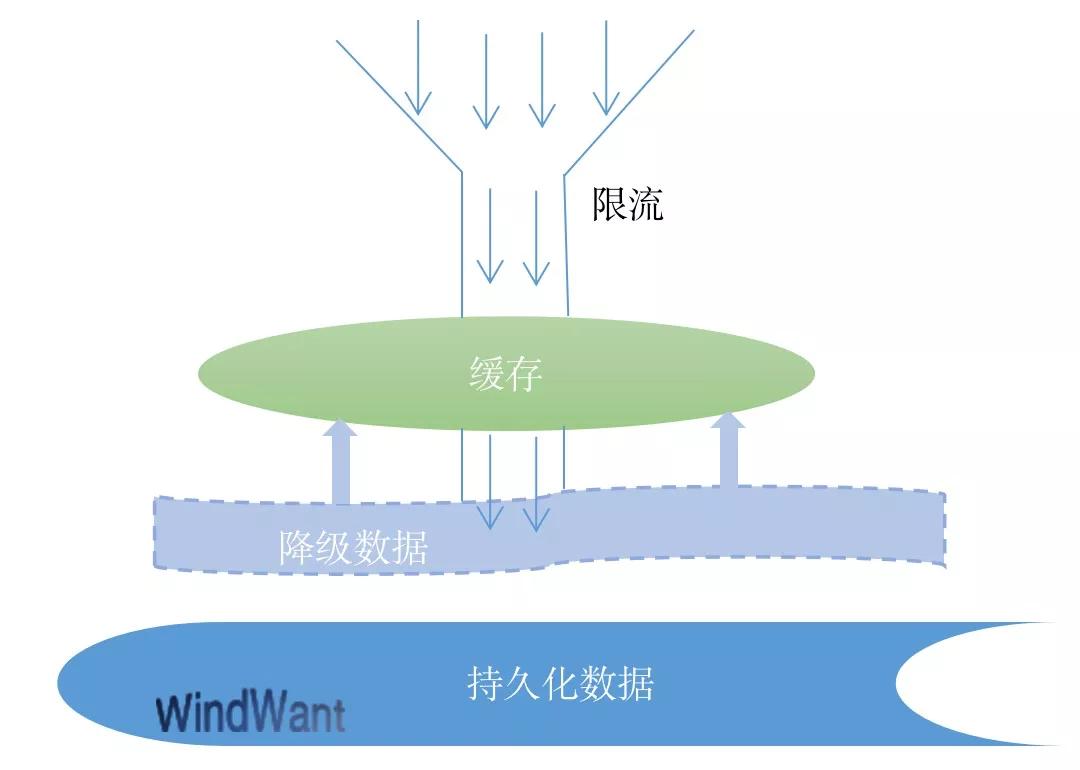
服务治理的目的是什么?服务的稳定性。限流即对异常流量的控制;熔断、降级标的核心服务资源的保护。
缓存、持久化数据存储都是资源,或者我们可以从对缓存的流控及对持久化数据存储的熔断、降级保护来着手应对缓存雪崩的情景发生。
缓存元素的集中过期导致缓存失效
对于设置了过期时间的缓存元素,如果发生元素同时过期,则会有瞬间的外部请求直接到达持久存储层。
在实际的缓存应用中,需要采取一定的措施,实现缓存元素过期时间的均匀分布。
作者:WindWant
编辑:陶家龙
出处:cnblogs.com/niejunlei/p/12914336.html