本文转载自微信公众号「脑子进煎鱼了」,作者陈煎鱼。转载本文请联系脑子进煎鱼了公众号。
“微服务的战争” 是一个关于微服务设计思考的系列题材,主要是针对在微服务化后所出现的一些矛盾/冲突点,不涉及具体某一个知识点深入。如果你有任何问题或建议,欢迎随时交流。
开天辟地
在远古开天辟地时,大单体转换成微服务化后,服务的数量越来越多。每起一个新的服务,就得把项目的目录结构,基础代码重新整理一遍,并且很有可能都是从最初的 template 上 ctrl+c,ctrl+v 复制出来的产物,如下:
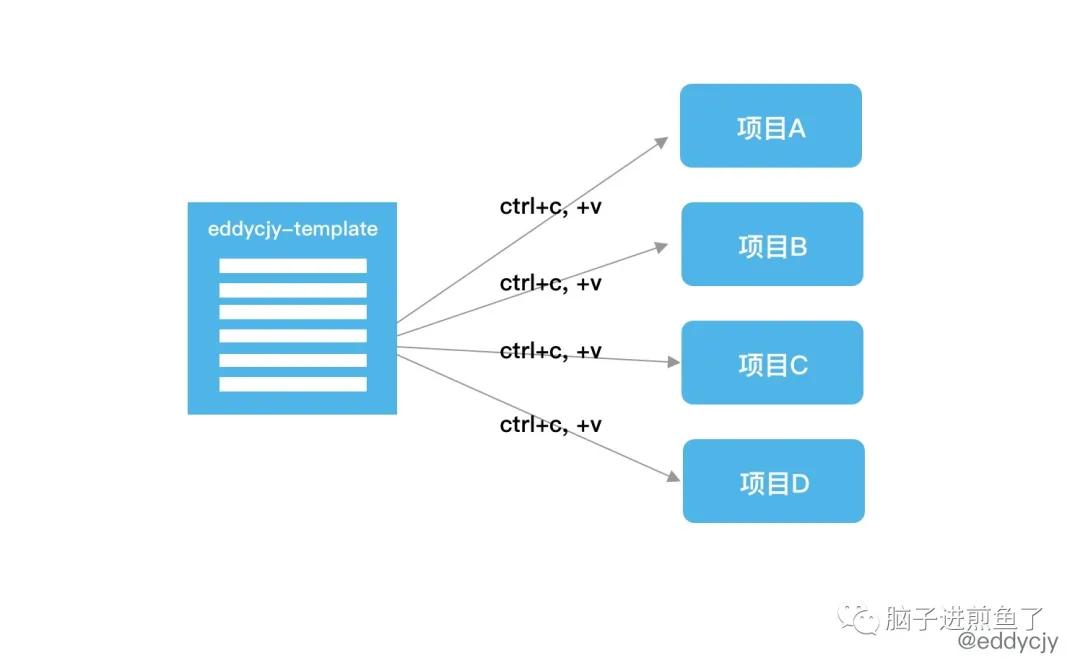
但是基于 template 的模式,很快就会遇到各种各样的新问题:
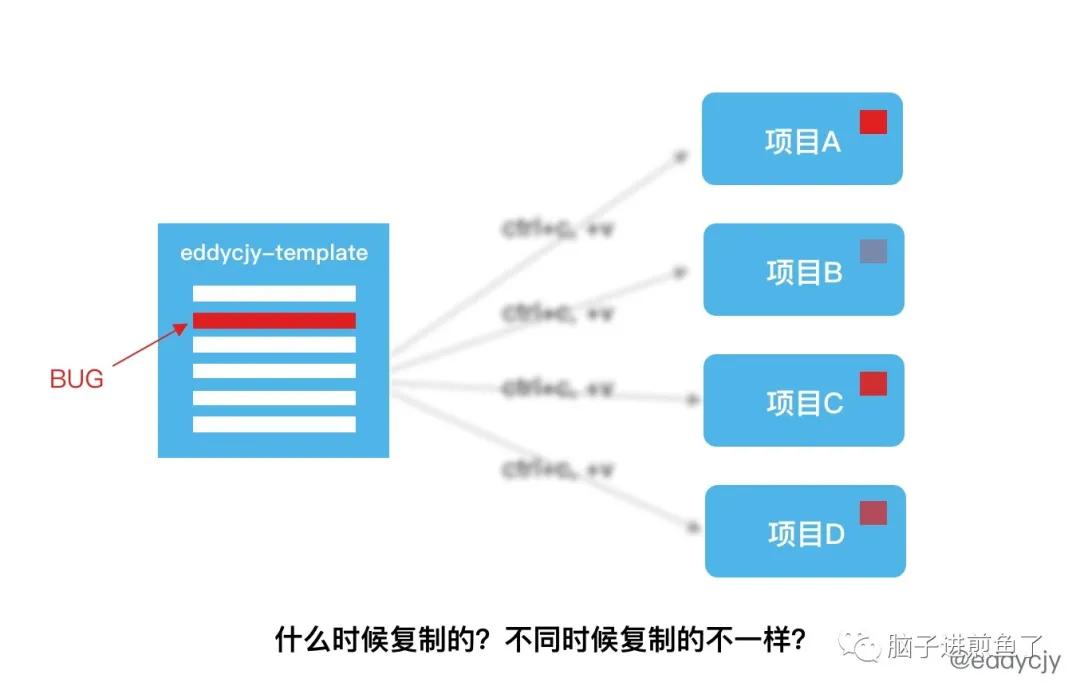
随着跨事业部/业务组的使用增多,你根本不知道框架的 template 是什么时间节点被复制粘贴出去的,也不知道所对应的 commit-id 是什么,更不知道先前的 BUG 修复了没,也不知道有没有其他开发人员私下改过被复制走的 template。
简单来讲,就是不具备可维护性,相对独立,BUG 可能一样,但却没有版本可规管。这时候,就可以选择做一个内部基础框架和对应的内部工具(已经有用户市场了),形成一个脚手架闭环:
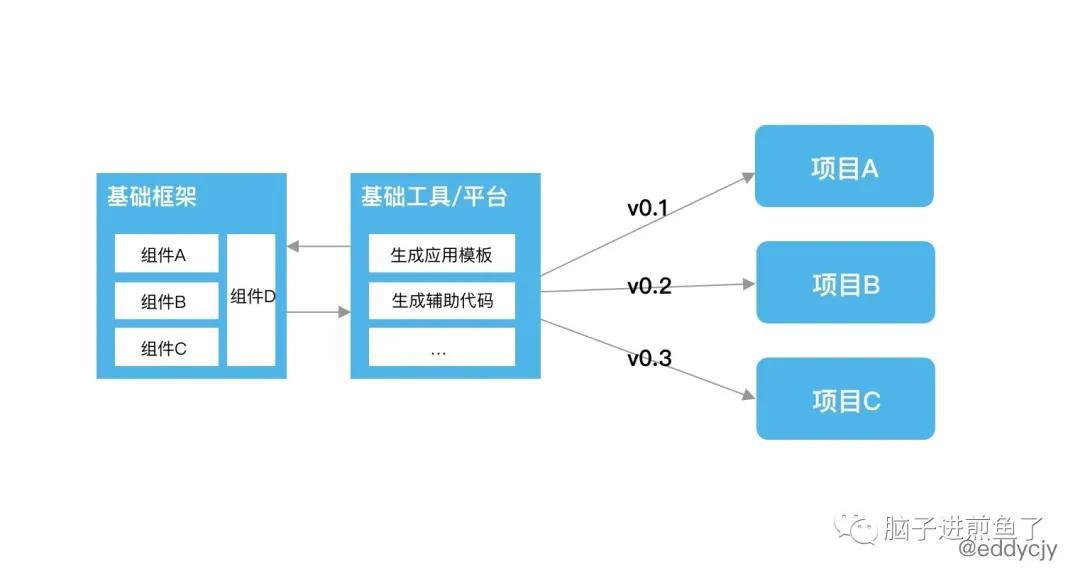
通过基础工具+基础接口的方式,就可以解决项目A、B、C...的基础框架版本管理和公共维护的问题,且在遇到框架 BUG 时,只需要直接 upgrade 就好了。
而在框架维护者层面,还能通过注册机制知道目前基础框架的使用情况(例如:版本分布),便于后续的迭代和规划。
同时若内部微服务依赖复杂,可以将脚手架直接 “升级”,再做多一层基础平台,通过 CI/CD 平台等关联创建应用,选择应用类型等基本信息,然后关联创建对应的应用模板、构建工具、网关、数据库、接口平台、初始化自动化用例等:
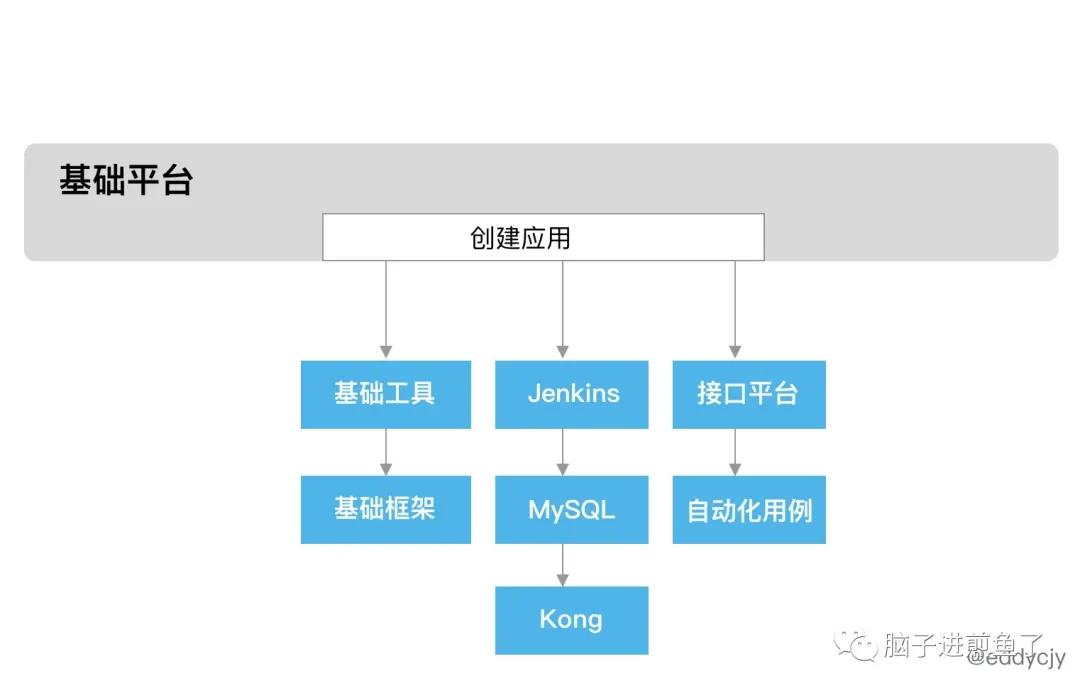
至此,就可以通过结合基础平台(例如:CI/CD)实现流程上的标准化控制,成为一个提效好帮手。
大众创新
但,一切都有 “开天辟地” 那么顺利吗。实际上并不,在很多的公司中,大多数是在不同的时间阶段在不同的团队同时进行了多个开天辟地。
更具现化来讲,就是在一家公司内,不同的团队里做出了多种基础工具和基础框架。更要命的是,他们几家的规范可能还不大一样。例如:框架在 gRPC 错误码的规范处理上的差异:
- 业务错误码放在 grpc.status.details 中。
- 业务错误码放在 grpc-status 中。
- 业务错误码放在 grpc-message 中。
又或是 HTTP 状态码的差异:
- HTTP Status Code 为金标准,不在主体定义业务错误码。
- HTTP Status Code 都为 200 OK(除宕机导致的 500,503 等),业务错误码由主体另外定义。
粗略一看,单单在应用错误码/状态码这一件事情上,就能够玩出花样。而这件事又会导致各种问题,例如在监控平台上,因为不同团队所定义的状态码规范不一样,就会导致连基本的监控可用性都会有问题。
像是有的小伙伴会把业务错误码放在 grpc-status 属性中,而在标准 gRPC 的规范中 grpc-status 是和 HTTP Status Code 一样有特定状态码映射的。这时候就会让监控告警系统十分难做,通用的告警规则到底是以哪份状态码为准?
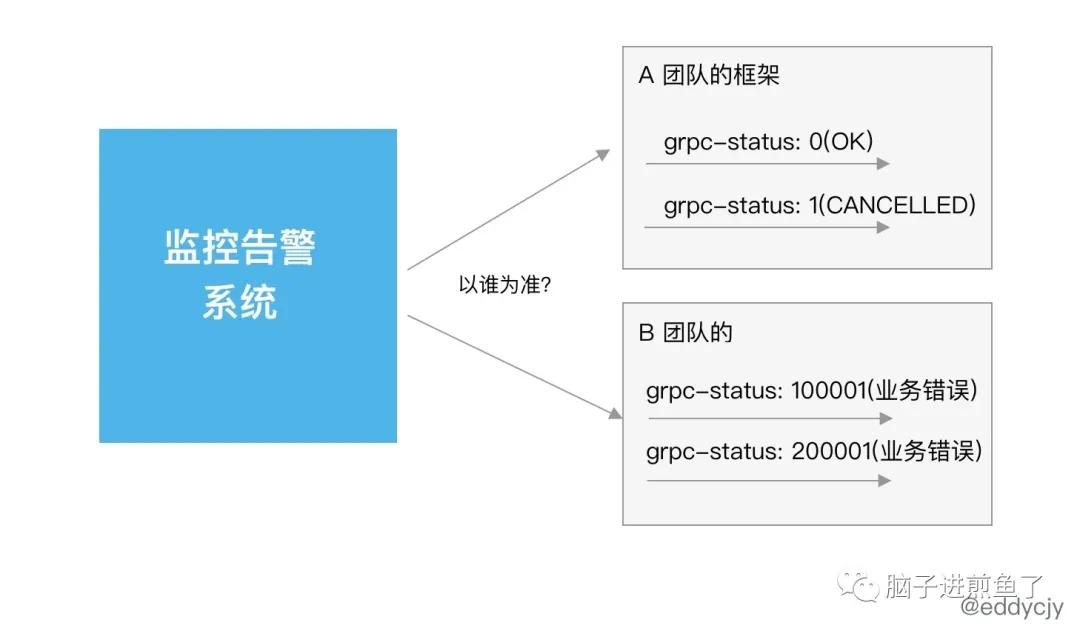
往往最终演进的路线与企业的组织结构有关,也就是康威定律,一个系统的技术边界反映组织的结构。业界常见的是两种情况:
A 吞并 B,B 与 A 一致,从例子上来讲就是基本公用一套(维度为公司/事业部/业务组级别,与企业情况有关)。
A,B 均独立发展,从例子上来讲就是均独立搭建,各管各,偶尔互相触碰边界,又或是在公开分享暗中切磋。
显然,这其中利与弊就要各自判断了,多少厂内部有多少个框架,也有血汗厂基本一统江湖的,可能做基础架构适配的小伙伴会比较有感触,不同框架的 Header 规范不一样,这样子即使是 Mesh 也避免不了一顿 if else。
更甚的是,在类似服务发现/注册、限流熔断、基础拦截器,各类 SDK 同个厂的每个内部框架都重现实现一遍。美其名曰框架支持了这些,就允许让他上,但这样子怕是在未来又造成了新的一波技术债务。
同时框架维护者,是有可能离职跳槽到别家去的,这在前端届也层出不穷,带着修炼好的真经走了,留下一个没有人维护的组内框架,这时候只能硬着头皮找 B/C 角来接受,顶上来的人指不定思想还不一样。
这单从公司层面来讲,是一个巨大的伤害,长远来看着实是灾难。
总结
在本文中,主体分为了 “开天辟地” 和 “大众创新” 两块内容,理想是丰满的,而现实怕是很骨感。微服务是一把双刃剑,带来好处的同时往往也带来了反面,架构的复杂度很难预知,因此本质上需要一个基架团队不忘初心,持续发现,持续解决问题。
但不论如何,及早的把主力语言、基本技术栈均基本统一起来,做好产品闭环,会是一个很好的方向。