详解输入网址点击回车,后台到底发生了什么。透析 HTTP 协议与 TCP 连接之间的千丝万缕的关系。掌握为何是三次握手四次挥手? time_wait 存在的意义是什么?全面图解重点问题,再也不用担心面试问这个问题。
大致流程
- URL 解析。
- DNS 查询。
- TCP 连接。
- 服务器处理请求。
- 客户端接收 HTTP 报文响应。
- 渲染页面
重点来了:
- 如何理解 TCP 的三次握手与四次挥手?每次握手客户端与服务端是怎样的状态?
- 为何挥手会出现 2MSL,遇到大量 Socket 处在 TIME_WAIT 或者 CLOSE_WAIT 状态是什么问题?
- 三次握手与四次挥手的过程是怎样的?
- HTTP 的报文格式又是怎样的?
继续阅读本文,且听码哥字节答疑解惑,微信搜索 “码哥字节”,关注公众号更多硬核。
URL 解析
地址解析:首先判断你输入的是一个合法的 URL 还是一个待搜索的关键词,并且根据你输入的内容进行自动完成、字符编码等操作。
HSTS 由于安全隐患,会使用 HSTS 强制客户端使用 HTTPS 访问页面。详见:你所不知道的 HSTS[1]。
其他操作 浏览器还会进行一些额外的操作,比如安全检查、访问限制(之前国产浏览器限制 996.icu)。
检查缓存
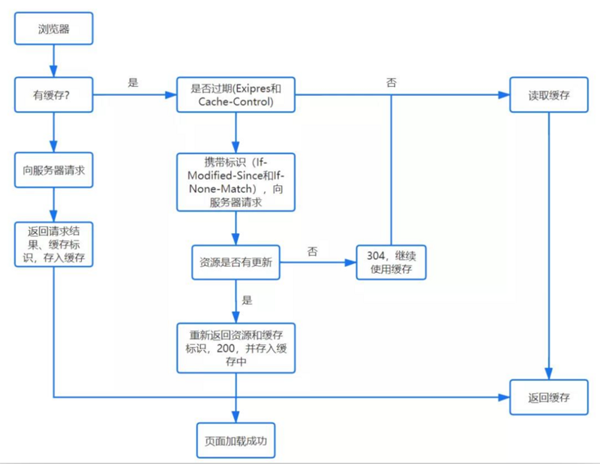
DNS 查询

- 浏览器缓存:先检查是否在缓存中,没有则调用系统库函数进行查询。
- 操作系统缓存:操作系统也有自己的 DNS 缓存,但在这之前,会向检查域名是否存在本地的 Hosts 文件里,没有则向 DNS 服务器发送查询请求。
- 路由器缓存。
- ISP DNS 缓存:ISP DNS 就是在客户端电脑上设置的首选 DNS 服务器,它们在大多数情况下都会有缓存。
根域名服务器查询
在前面所有步骤没有缓存的情况下,本地 DNS 服务器会将请求转发到互联网上的根域,下面这个图很好的诠释了整个流程:
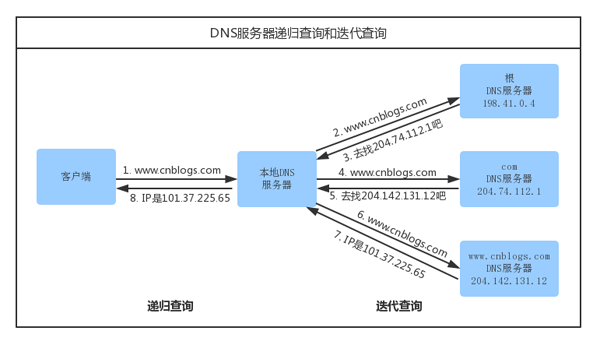
需要注意的的是:
- 递归方式:一路查下去中间不返回,得到最终结果才返回信息(浏览器到本地 DNS 服务器的过程)
- 迭代方式,就是本地 DNS 服务器到根域名服务器查询的方式。
- 什么是 DNS 劫持
- 前端 dns-prefetch 优化
TCP 连接建立与断开
TCP/IP 分为四层,在发送数据时,每层都要对数据进行封装:

应用层:发送 HTTP 请求
浏览器从地址栏得到服务器 IP,接着构造一个 HTTP 报文,其中包括:
- 请求报头(Request Header):请求方法、目标地址、遵循的协议等
- 请求主体,请求参数,比如 body 里面的参数
传输层:TCP 传输报文
传输层会发起一条到达服务器的 TCP 连接,为了方便传输,会对数据进行分割(以报文段为单位),并标记编号,方便服务器接受时能够准确地还原报文信息。在建立连接前,会先进行 TCP 三次握手。
网络层:IP 协议查询 MAC 地址
将数据段打包,并加入源及目标的 IP 地址,并且负责寻找传输路线。判断目标地址是否与当前地址处于同一网络中,是的话直接根据 Mac 地址发送,否则使用路由表查找下一跳地址,以及使用 ARP 协议查询它的 Mac 地址。
链路层:以太网协议
根据以太网协议将数据分为以“帧”为单位的数据包,每一帧分为两个部分:
- 标头:数据包的发送者、接受者、数据类型
- 数据:数据包具体内容
Mac 地址
以太网规定了连入网络的所有设备都必须具备“网卡”接口,数据包都是从一块网卡传递到另一块网卡,网卡的地址就是 Mac 地址。每一个 Mac 地址都是独一无二的,具备了一对一的能力。
主要的请求过程:
- 浏览器从地址栏中获取服务器的 IP 和端口号;
- 浏览器有服务器之间通过 TCP 三次握手建立连接;
- 浏览器向服务器发送报文;
- 服务器接收报文处理,同时将响应报文发给浏览器;
- 浏览器解析报文,渲染输出到页面;
三次握手
在传输层传输数据之前需要建立连接,也就是三次握手创建可靠连接。
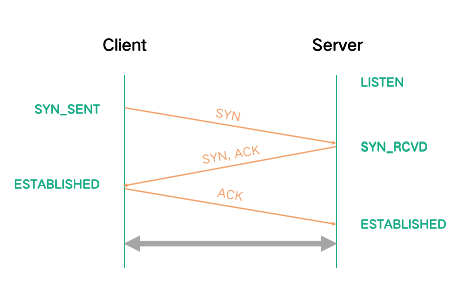
首先建立链接前需要 Server 端先监听端口,因此 Server 端建立链接前的初始状态就是 LISTEN 状态,这时 Client 端准备建立链接,先发送一个 SYN 同步包,发送完同步包后,Client 端的链接状态变成了 SYN_SENT 状态。Server 端收到 SYN 后,同意建立链接,会向 Client 端回复一个 ACK。
由于 TCP 是双工传输,Server 端也会同时向 Client 端发送一个 SYN,申请 Server 向 Client 方向建立链接。发送完 ACK 和 SYN 后,Server 端的链接状态就变成了 SYN_RCVD。
Client 收到 Server 的 ACK 后,Client 端的链接状态就变成了 ESTABLISHED 状态,同时,Client 向 Server 端发送 ACK,回复 Server 端的 SYN 请求。
Server 端收到 Client 端的 ACK 后,Server 端的链接状态也就变成了的 ESTABLISHED 状态,此时建连完成,双方随时可以进行数据传输。
在面试时需要明白三次握手是为了建立双向的链接,需要记住 Client 端和 Server 端的链接状态变化。另外回答建连的问题时,可以提到 SYN 洪水攻击发生的原因,就是 Server 端收到 Client 端的 SYN 请求后,发送了 ACK 和 SYN,但是 Client 端不进行回复,导致 Server 端大量的链接处在 SYN_RCVD 状态,进而影响其他正常请求的建连。可以设置 tcp_synack_retries = 0 加快半链接的回收速度,或者调大 tcp_max_syn_backlog 来应对少量的 SYN 洪水攻击
四次挥手
我们只要关注 80 端口与 13743 端口建立的连接断开过程,浏览器通过 13747 端口发送 [FIN, ACK] 这里是不是跟很多网上看到的不一样?
- 其实是客户端在发送 [FIN] 报文的时候顺带发了一个 [ACK] 确认上次传输确认。
- 接着服务端通过 80 端口响应了 [ACK] ,然后立马响应 [FIN, ACK] 表示数据传输完了,可以关闭连接。
- 最后浏览器通过 13743 端口 发送 [ACK] 包给服务端,客服端与服务端连接就关闭了。
具体流程如下图抓包所示:

三次握手与四次挥手
客户端:
- SYN_SENT - 客户端发起第 1 次握手后,连接状态为 SYN_SENT ,等待服务端内核进行应答,如果服务端来不及处理(例如服务端的 backlog 队列已满)就可以看到这种状态的连接。
- ESTABLISHED - 表示连接处于正常状态,可以进行数据传送。客户端收到服务器回复的 SYN+ACK 后,对服务端的 SYN 单独回复(第 3 次握手),连接建立完成,进入 ESTABLISHED 状态。服务端程序收到第 3 次握手包后,也进入 ESTABLISHED 状态。
- FIN_WAIT_1 - 客户端发送了关闭连接的 FIN 报文后,等待服务端回复 ACK 确认。
- FIN_WAIT_2 - 表示我方已关闭连接,正在等待服务端关闭。客户端发了关闭连接的 FIN 报文后,服务器发回 ACK 应答,但是没进行关闭,就会处于这种状态。
- TIME_WAIT - 双方都正常关闭连接后,客户端会维持 TIME_WAIT 一段时间,以确保最后一个 ACK 能成功发送到服务器端。停留时长为 2 倍的 MSL (报文最大生存时间),Linux 下大约是 60 秒。所以在一个频繁建立短连接的服务器上通常可以看到成千上万的 TIME_WAIT 连接。
服务端:
- LISTEN - 表示当前程序正在监听某个端口时。
- SYN_RCVD - 服务端收到第 1 次握手后,进入 SYN_RCVD 状态,并回复一个 SYN+ACK(第 2 次握手),再等待对方确认。
- ESTABLISHED - 表示连接处于正常状态,可以进行数据传送。完成 TCP3 次握手后,连接建立完成,进入 ESTABLISHED 状态。
- CLOSE_WAIT - 表示客户端已经关闭连接,但是本地还没关闭,正在等待本地关闭。有时客户端程序已经退出了,但服务端程序由于异常或 BUG 没有调用 close()函数对连接进行关闭,那在服务器这个连接就会一直处于 CLOSE_WAIT 状态,而在客户机已经不存在这个连接了。
- LAST_ACK - 表示正在等待客户端对服务端的关闭请求进行最终确认。
TIME_WAIT 状态存在的理由:
划重点了
- 可靠地实现 TCP 全双工连接的终止 在进行关闭连接四路握手协议时,最后的 ACK 是由主动关闭端发出的,如果这个最终的 ACK 丢失,服务器将重发最终的 FIN,因此客户端必须维护状态信息允 许它重发最终的 ACK。如 果不维持这个状态信息,那么客户端将响应 RST 分节,服务器将此分节解释成一个错误( 在 java 中会抛出 connection reset 的 SocketException)。因而,要实现 TCP 全双工连接的正常终 止,必须处理终止序列四个分节中任何一个分节的丢失情况,主动关闭 的客户端必须维持状 态信息进入 TIME_WAIT 状态。
- 允许老的重复分节在网络中消逝 TCP 分节可能由于路由器异常而“迷途”,在迷途期间,TCP 发送端可能因确认超时而重发这个 分节,迷途的分节在路由器修复后也会被送到最终目的地,这个 原来的迷途分节就称为 lost duplicate。在关闭一个 TCP 连接后,马上又重新建立起一个相同的 IP 地址和端口之间的 TCP 连接,后一个连接被称为前一个连接的化身 ( incarnation),那么有可能出现这种情况,前一 个连接的迷途重复分组在前一个连接终止后出现,从而被误解成从属于新的化身。为了避免 这个情 况,TCP 不允许处于 TIME_WAIT 状态的连接启动一个新的化身,因为 TIME_WAIT 状 态持续 2MSL,就可以保证当成功建立一个 TCP 连接的时 候,来自连接先前化身的重复分组已 经在网络中消逝。
另外回答断链的问题时,可以提到实际应用中有可能遇到大量 Socket 处在 TIME_WAIT 或者 CLOSE_WAIT 状态的问题。一般开启 tcp_tw_reuse 和 tcp_tw_recycle 能够加快 TIME-WAIT 的 Sockets 回收;而大量 CLOSE_WAIT 可能是被动关闭的一方存在代码 bug,没有正确关闭链接导致的。
简单地说就是
- 保证 TCP 协议的全双工连接能够可靠关闭;
- 保证这次连接的重复数据段从网络中消失,防止端口被重用时可能产生数据混淆;
服务器处理请求并响应 HTTP 报文
深入分析下 HTTP 报文到底是什么玩意。数据传输都是通过 TCP/IP 协议负责底层的传输工作, HTTP 协议基本不用操心,所谓的 “超文本传输协议” 似乎不怎么例会 “传输” 这个事情,那 HTTP 的核心又是什么呢?
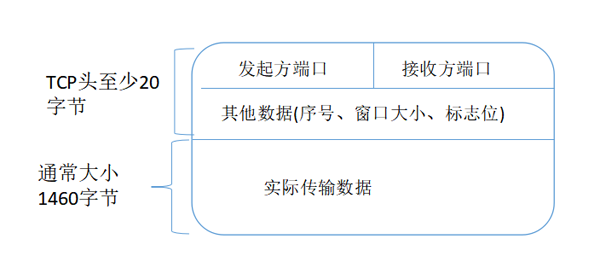
比图 TCP 报文,它在实际要传输的数据之前附加了一个 20 字节的头部数据,存储 TCP 协议必须的额外信息,例如发送方的端口号、接收方的端口号、包序号、标志位等等。
有了这个附加的 TCP 头,数据包才能够正确传输,到了目的地后把头部去掉,就可以拿到真正的数据。这个很容易理解,设置起点与终点,不同协议贴上不同的头部,到了对应目的地就拆下这个头部,提取真正的数据。
与 TCP/UDP 类似需要在传输数据前设置一些请求头,不同的是 HTTP 是一个 “纯文本” 的协议,所有的头都是 ASCII 码的文本,很容易看出来是什么。
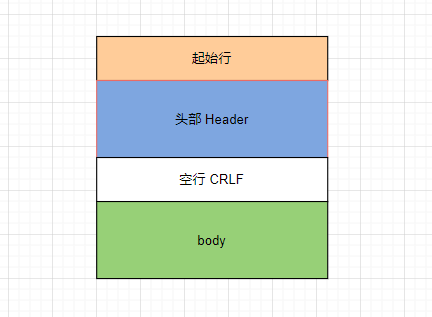
再者就是他的请求报文与响应报文的结构基本一样,主要三大部分组成:
- 起始行(Start Line):描述请求或者响应的基本信息。
- Header:使用 key-value 的形式详细说明报文信息。
- 空行。
- 消息正文(Entity):传输的数据,图片、视频、文本等都可以。
这其中前两部分起始行和头部字段经常又合称为“请求头”或“响应头”,消息正文又称为“实体”,但与“header”对应,很多时候就直接称为“body”。
敲黑板了
HTTP 协议规定报文必须包含 Header,而且之后必须有一个 “空行”,也就是“CRLF”,十六进制的“0D0A”,可以没有 “body”。
报文结构如下图所示:
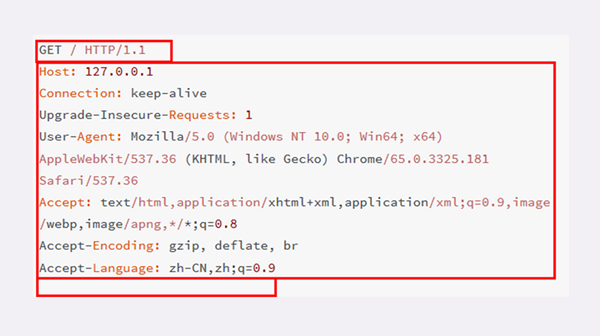
截取一段报文:
请求头-起始行
请求行由请求方法字段、URL 字段和 HTTP 协议版本字段 3 个字段组成,它们用空格分隔。例如,GET / HTTP/1.1。
HTTP 协议的请求方法有 GET、POST、HEAD、PUT、DELETE、OPTIONS、TRACE、CONNECT。
GET 是请求方法, “/” 是请求的目标资源,“HTTP/1.1” 请求协议版本号。
GET / HTTP/1.1 翻译成文字大概就是:“hello,服务器,我要请求根目录下的默认文件使用的是 HTTP 1.1 协议版本”。
头部 Header
第二部分就是 Header,组成形式是 key:value,使用自定义头需要注意事项:
- header 字段不区分大小写,通常是首字母大写;
- 字段名不允许有空格,可以使用 “-”,不能使用 “_”;
- 字段名必须紧接着 “:”,不能有空格,但是 “:” 后面可以有空格。
- 字段名顺序没有意义;
浏览器接收响应并渲染数据
浏览器接收到来自服务器的响应资源后,会对资源进行分析。首先查看 Response header,根据不同状态码做不同的事(比如上面提到的重定向)。如果响应资源进行了压缩(比如 gzip),还需要进行解压。然后,对响应资源做缓存。接下来,根据响应资源里的 MIME[3] 类型去解析响应内容(比如 HTML、Image 各有不同的解析方式)。
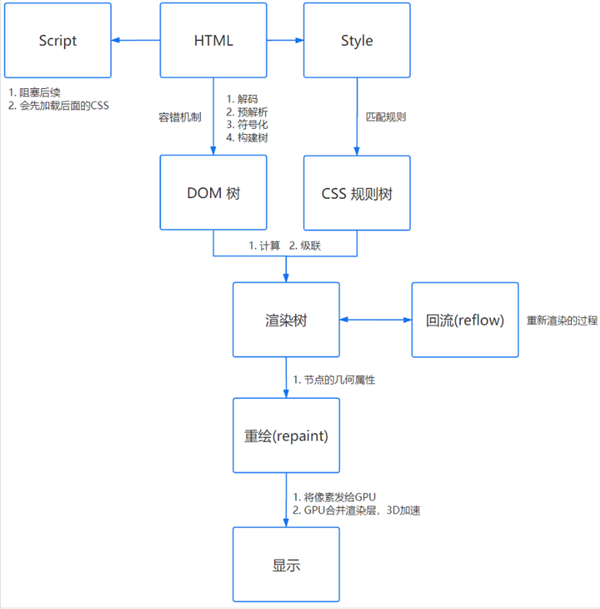
接下来将接收到的数据渲染出来,不同的浏览器也不是完全相同,但是大致流程是一样的:
如果觉得阅读后对你有帮助,希望多多分享、点赞与在看素质三连不做白嫖者。关注 【码哥字节】解锁更多硬核。