一、起因
分布式环境下,多台机器上多个进程对一个数据进行操作,必然引起数据不一致的情况,比如“商品超卖”。那么在分布式环境下,怎么访问临界资源,是互联网的一大难题。分布式锁就是一种解决方法。

二、互斥原理
原理:多个访问方对同一个资源进行操作,需要进行互斥,通常是利用一个这些访问方同时能够访问到的lock来实施互斥的。
场景一
在同一个进程内,多个线程的互斥,我们可以通过加锁来进行串行化访问。
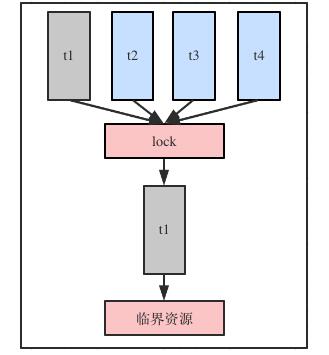
步骤:
- 多个线程同时抢锁
- 只一个线程抢到,未抢到的阻塞,或下次再来抢
- 抢到锁的线程操作临界资源
- 操作完临界资源后释放锁
画外音:锁是进程内的一个数据结构,将临界资源的冲突转变为对锁结构的冲突。
场景二
在分布式环境下,进程内的锁结构就无法作用于进程外了,所以多进程情况下怎么进行临界资源的保护呢?
结合进程内锁的机制,我们可以得出几点条件:
- 需要有一个特殊的数据结构,每个进程都能访问
- 同时只能一个进程访问成功
- 访问成功的进程可以访问临界资源
画外音:问题的关键在于找到同时只有一个进程访问成功的外部存储结构。
三、分布式锁
既然分布式锁的核心是选择合适的外部存储,那怎么选择“合适”的存储介质和存储模型就是我们思考的核心了。
那分布式锁用关系型存储还是KV存储?
从锁的角度来看,我们对它要求不多,KV存储足够。这样我们第一想到的就是Redis方案了,那是不是Redis方案就是最优方案呢?
Redis:单线程高性能的内存KV存储方案。
- 满足所有进程都能访问的数据结构
- 单线程满足只有一个进程能访问成功(setnx命令)
- 业务上保证set成功的进程进行临界资源操作
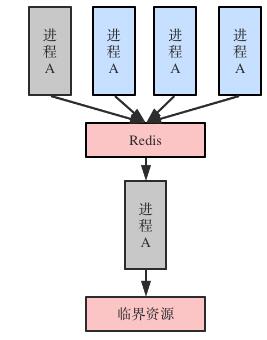
步骤:
- 多台机器上多个进程对这个锁进行争抢,例如在缓存上同时进行set key=123操作
- 只有一个进程会抢到这个锁,即只有一个进程对缓存set key=123能够成功,不成功的进程下次再来抢
- 抢到锁的进程对临界资源进行操作
- 扣减完成之后释放锁,即对缓存delete key=123
从功能上,Redis完美的实现了分布式锁,那再深入一点。
- MySQL能不能实现分布式锁?
- ZooKeeper实现分布式锁和Redis实现的本质区别是什么?
- 不同的架构选型,我们应该怎么选择?