Redis是非常流行的缓存。在Redis升级到3.0版本后,升级到集群版本,被称之为Redis Cluster。在集群版本中,会将数据分成多份,被保存到多个server中,从而保证集群的水平扩展能力,加之每份数据保存多个副本,从而保证可用性,并且集群版本保证一定程度的Write Safety。本文详细介绍Redis Cluster的实现细节,从而分析Redis Cluster的Write Safety的保证程度。

一、接口和架构
1、接口
Redis Cluster的接口基本向前兼容,仍然是key-value类型。
2、架构
Redis Cluster包含server和client两个组件。一个Redis Cluster可以包含多个server,可以包含多个客户端。每个客户端可以连接任意的server,读取写入数据。保存在Redis Cluster中的数据会被分成多份,分散地保存在多个server中,并且每一份数据也会保存多个副本。
二、实现
1、节点
在Redis Cluster中,数据会被保存到多个Redis server中,每个Redis server都是一个独立的进程,具有独立的IP和Port,也被称之为一个实例,或者叫做节点(Node)。Client通过这个IP和Port连接到这个Node。
每个节点都有个node id,node id是一个全局唯一的标识,它是在集群创建时随机生成的。一个节点的id始终都不会变化的,但是node的IP和port是可以变化的。
2、Node table
一个Redis Cluster包含哪些节点,也就是这个集群包含哪些节点的id,也就是集群成员关系,这个信息被保存在一个表结构中,被称之为node table。node table类似于:

node table会在每个节点上都保存一份,Redis Cluster通过gossip协议把node table复制到所有的节点。后面会继续讲述node table的复制。
3、集群成员关系变更
当添加一个节点或者删除一个节点时,只需要将命令发给集群中的任意一个节点,这个节点会修改本地的node table,并且这个修改会最终复制到所有的节点上去。添加节点的命令是CLUSTER MEET,删除节点的命令是CLUSTER FORGET。
举例来说明:
- 打算搭建一个3个master节点的集群,当集群创建以前,所有3个节点的node table都只包含自己。给其中的一个节点A发送命令,CLUSTER MEET NodeB,节点A修改自己的node table,将NodeB添加到自己的node table中,并且连接节点B,把自己的node table发送给节点B,节点B收到节点A发送过来的node table,会更新自己的node table,这时节点B就知道集群中还有节点A存在。
这时,给节点A再发送CLUSTER MEET NodeC,节点A会把节点C添加到自己的node table,并且把自己的node table复制给节点B,节点B把接收到的node table更新自己的本地的node table,从而知道节点C的加入。同样节点A会把自己的node table发给节点C,节点C会更新自己本地的node table,从而知道要加入的集群中已经存在节点A和节点B。
4、槽
前面说过Redis Cluster会把数据分成多份,也就是把数据进行分片。Redis Cluster中的每一份数据被称为槽(Slot)。Redis Cluster将数据拆分成16384份,也就是说有16384个槽。
Redis Cluster采用哈希(Hash)机制来拆分数据。首先,数据的key通过CRC16算法计算出一个哈希值。这个哈希值再对16384取余,这个余数就是槽位,被称为hash slot。具体的CRC16算法可以参看Redis官方文档。所有余数相同的key都在一个slot中,也就是说,一个slot其实就是一批hash余数相同的key。
每个hash slot都会保存在Redis Cluster一个节点中。具体哪个hash slot被保存在哪个实例中,就形成了类似于一个map的数据结构,被称之为hash slot map。hash slot map类似于:
- 0 -> NodeA
- 1 -> NodeA
- 2 -> NodeB
- ...
- 16383 -> NodeN
与node table相同,hash slot map也会在每个节点上都会保存一份,Redis Cluster通过gossip协议把hash slot map复制到所有节点。同样,后面还会讲述hash slot map的复制。
《Redis官方文档》Redis Cluster Specification, https://redis.io/topics/cluster-spec.
5、数据分片变更
要修改数据分片关系,可以连接任意一个节点,给这个节点发送CLUSTER ADDSLOTS, CLUSTER SETSLOT, CLUSTER DELSLOT命令,修改这个节点上的hash slot map,该节点会把这个修改复制到所有其他节点,其他节点会用接收到的hash slot map更新自己的hash slot map。
CLUSTER ADDSLOTS、CLUSTER DELSLOTS、CLUSTER SETSLOT命令的使用如下:
- CLUSTER ADDSLOTS slot1 [slot2] ... [slotN]
- CLUSTER DELSLOTS slot1 [slot2] ... [slotN]
- CLUSTER SETSLOT slot NODE node
CLUSTER ADDSLOTS用来把多个slot分配給当前连接的节点。例如,连接到节点A执行:
- CLUSTER ADDSLOTS 1 2 3
这个命令会把slot1、slot2、slot3分配给节点A。
CLUSTER DELSLOTS用来把多个slot从当前连接的节点删除。例如,连接到节点A执行:
- CLUSTER DELSLOTS 1 2 3
这个命令会把slot1、slot2、slot3从节点A上删除。
CLUSTER SETSLOT用来把一个slot分配给指定的节点,可以不是当前连接的节点,另外这个命令还可以设定MIGRATING和IMPORTING两个状态,我们后面再讲。例如,连接到节点A执行:
- CLUSTER SETSLOT 1 nodeB
这个命令会把slot1分配给节点B。
6、Slave
一个slot会被保存多个副本,既一个slot会保存在多个节点上,也就是slot会复制到多个节点上。Redis Cluster的复制是以节点为单位的,一个节点上的所有slot会采用相同的复制。
具体来说就是,其中一个节点会负责处理这个节点上所有slot的写操作,这个节点被称为master,而其余的节点被称为slave节点。一个master可以有多个slave。在同一个节点上的所有slot的所有的写操作都会被从master节点异步复制到所有的slave节点。所以slave会具有与master相同的slot。
通过SLAVEOF命令来设置slave节点。SLAVEOF命令用来改变一个slave节点的复制设置。SLAVEOF命令有两种格式:
- SLAVEOF NO ONE
- SLAVEOF host port
具体来讲,SLAVEOF NO ONE命令会停止一个slave节点的复制,并且把这个slave节点变成master节点。SLAVEOF host port命令会停止一个slave节点的复制,丢弃数据集,开始从host和port指定的新master节点复制。
master和slave的关系会被记录在hash slot table中,相当于一个slot会映射到多个节点上,其中一个节点是master,其他记录的节点是slave。
加入了master/slave信息后的hash slot map类似于:
- 0 -> NodeA,NadeA1(slave)
- 1 -> NodeA,NadeA1(slave)
- 2 -> NodeB,NadeB1(slave)
- ...
- 16383 -> NodeN,NadeN1(slave)
作为hash slot map的一部分,master/slave信息也会通过gossip协议复制到集群中的每个节点。
7、Configuration
node table和hash slot map这两个信息,被称之为Configuration,在其他的分布式系统中,也被称之为元数据。
前面我们讲过,hash slot map和node table在每个节点都会保存一份,并且对这两个信息的任何改动,都会通过gossip协议传播(propogate)到所有的节点。本文我们就不继续展开gossip协议了,对Redis Cluster的gossip协议的实现感兴趣的同学可以参看redis的文档。
在某些分布式系统中,元数据被存储在一个单独的架构组件中的。Redis Cluster并没有这样一个元数据存储的组件,而是把元数据分散的存储在所有的节点上。
hash slot map和node table在集群创建时会被创建出来,并且会随着后续的集群变更(比如failover和扩容、缩容等运维操作,后面会讲述)而跟随着变更。变动会在一个Node上发起,通过gossip协议传播到所有其他的节点。这两个信息在所有节点都会保存,并且会最终达到一致。
8、集群创建
创建Redis Cluster时,首先要以cluster模式运行多个redis server,redis server运行起来后,这些server的node id就已经生成了。但是这些redis server并没有形成集群,也就是server彼此之间并不知道相互的存在。接下来运行CLUSTER MEET命令,让这些节点形成一个集群。但是这时集群仍然没有处于运行状态,需要分配slot,通过CLUSTER SLOTADD命令把slot分配给具体的节点之后,集群就可以处理client的命令了。
9、客户端的读写操作
客户端要读取、写入数据时,虽然client可以连接任意server,但是实际中,client需要根据实际需求连接到server读取、写入数据。client需要先根据key计算出hash slot,连接到负责这个hash slot的节点进行读写操作。这样的话,client就要需要知道hash slot -> node的映射关系,也就是需要知道hash slot map。
前面讲过hash slot map被保存在server端的每个节点上。client可以从任意节点获取hash slot map,并且把它缓存到client本地,下次操作时根据本地缓存直接进行操作,但是需要处理缓存信息过期的问题,如果client发现hash slot map发生变化(即client读取写入数据时server回错误,接下来会详细讲述),会重新从server端获取新的hash slot map。通过hash slot map可以判断某个key应该存在在哪个节点上,client再连接这个节点进行读写操作。
10、MOVED Redirection
hash slot map会发生变更,这些变更会复制到所有的节点,但是gossip保证的是最终复制到所有的节点,再加上client会缓存hash slot map,client可能会把某个key的请求发给错误的节点来处理。
错误的节点收到请求后,发现这个key不应该自己来处理,会给客户端返回MOVED的错误,在错误消息中,会告诉客户端,哪个节点应该负责这个slot。Client收到MOVED消息后,会向消息中指定的节点再次发送请求。
client可以将slot的节点信息更新到本地缓存的hash slot map中,但是更好的方法是,重新获取完整的hash slot map,替换本地的缓存。因为在大多数情况下,hash slot map中的变更不仅仅只修改一个slot。
虽然client按照MOVED消息中的节点信息重新发送请求,但是client仍然可能再次从新节点收到MOVED错误消息,因为上一个节点的hash slot map可能也不是最新的。但是因为hash slot map最终会在所有的节点上一致,所以client在几次收到MOVED错误后,最终会获取到最新的hash slot map。
11、Failover、currentEpoch、lastVoteEpoch
当master发生故障宕机后,Redis Cluster会选出一个slave来接替这个master。
如果有多个slave存在,那么每个slave都可能都会发现master发生了宕机,并且试图把自己变成为master,如果有多个slave成为master,那么这些新master都会更新本地hash slot map,把旧master负责的slot更新成自己,并且把自己对hash slot map的更新传播给其他的节点。这会导致hash slot map在节点间出现差异。
从而导致,因为所连接的节点不同,client拿到不同的hash slot map,对于同一个slot,不同的client会连接不同的节点,最终导致节点上的数据出现差异。所以failover要保证,只有一个slave被选成新master。
Redis Cluster采用了类似Raft算法的技术来防止多个slave被选成master。每个节点都会有叫做currentEpoch、lastVoteEpoch的两个值。在集群刚创建时,每个节点的currentEpoch都是0。
当slave发现master宕机时,这个slave会增加currentEpoch(即currentEpoch++)。并且向所有的master发送FAILOVER_AUTH_REQUEST请求,请求中会携带自己currentEpoch,master收到FAILOVER_AUTH_REQUEST,如果请求中的currentEpoch比自己的currentEpoch和lastVoteEpoch都大,则记录请求中的currentEpoch值到自己的currentEpoch、lastVoteEpoch中,并且回复FAILOVER_AUTH_ACK给slave,回复中携带master的currentEpoch。
所以可以看出,FAILOVER_AUTH_ACK中的Epoch一定与slave的currentEpoch相同。Slave从大多数的master收到FAILOVER_AUTH_ACK后,则成为master。
上面的过程保证只有一个slave被选出,我们来举例说明。五个master的集群,master节点分别是A、B、C、D、E,A节点有两个slave,分别是A1和A2。A节点发生宕机,A1增加自己的currentEpoch=5(4+1),A1给所有的master发送FAILOVER_AUTH_REQUEST,节点B、C、D收到FAILOVER_AUTH_REQUEST,把自己的currentEpoch和lastVoteEpoch更新成5,并且给A1回复FAILOVER_AUTH_ACK,A1赢得选举,成为新的master。但是与此同时,A2也发现A宕机,也试图选举成master。A2增加自己的currentEpoch=5(4+1),A2给所有的master发送FAILOVER_AUTH_REQUEST,但这时的B、C、D的lastVoteEpoch已经是5,所以B、C、D不会给A2回复,E还没有收到A1的请求,所以只有E会给A2回复,但是不能形成大多数,所以A2不能称为master。
上面讲述的过程已经可以保证只有一个master被选出,但是除此之外,Redis Cluster还做了一个优化,那就是master回复了一个请求后不会在给这个master的其他的slave发送回复。
12、Configuration epoch
failover完成后,新master会修改hash slot map,把相应的slot记录的节点改成自己,并且把这次对hash slot map的改动传播给其他节点。
虽然currentEpoch和lastVoteEpoch能保证每次failover只能有一个节点被选成新的master,但是先后两次failover,可能选出的两个不同的master,但是他们对hash slot map的修改的传播却是异步,也就是后面一次failover的改动可能先于第一次failover的改动到达某个节点,从而导致节点间对hash slot map这个信息产生不一致。
Redis Cluster通过configEpoch来解决这个问题。每个节点会保存一个configEpoch的值。相当于在node table中还会有一列数据叫configEpoch,类似于下面的表:
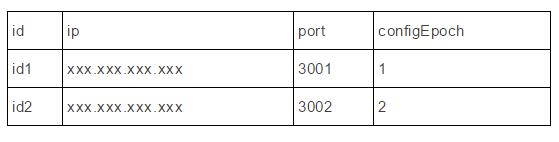
每次failover完成后,新选出的master会用currentEpoch覆盖configEpoch。Failover的机制保证两次failover的新master一定是具有不同的currentEpoch,并且后一次的failover的currentEpoch一定比前一次大。这样就可以保证,即便采用了gossip这样传播协议,仍然能够保证最后一次failover的hash slot map的变更会生效,也就是configEpoch更大的变更会生效,并且最终所有的节点上的hash slot map是一致的。
Slave节点的configEpoch就是其master的configEpoch。
由于gossip保证的hash slot map最终保持一致的,所以可能存在slave的hash slot map旧于master,failover不能基于旧的hash slot map基础上做变更,所以前面failover的过程中还需要补充一个规则要遵守:
- 在FAILOVER_AUTH_REQUEST中会携带slave节点的configEpoch,如果这个slave的configEpoch比这个slave负责的所有slot的master的configEpoch中任意一个要小,则master不会给slave回复FAILOVER_AUTH_ACK。
13、Resharding
在集群创建之后,我们还会有对Redis cluster做扩容、缩容、balancing这样的运维需求,这些需求本质上都可以用 Resharding 操作解决,resharding操作就是把slot在节点间重新的分布,把slot从一个节点转移到另外一个节点上。在Redis Cluster中,扩容需求实质上就是加入一个新的节点,再把一些slot分配到这个新节点上。
缩容需求实质上就是先把这个节点上的所有slot分配到其他节点上,再把这个节点从集群中移出。当节点间的流量不均衡时,我们有balancing这样的需求,balancing就是把流量比较大的节点上的一些slot分配都流量比较少的节点上。
Resharding操作可以是对整个hash slot map的调整,也就是可以包括对多个slot的迁移(migration),迁移就是把一个slot从一个节点迁移到另外一个节点。一个slot migration操作包括前面讲的hash slot map变更,另外还包括key的迁移操作。要把一个slot迁移到另外的节点上,首先把这个slot上的所有的key迁移到这个节点,当把所有key都迁移完后,再进行hash slot map变更,当hash slot map变更完成,这次slot migration结束。
Redis Cluster使用CLUSTER SETSLOT来设置迁移。举例说明,将slot1从节点A迁移到节点B。分别对节点A和节点B执行下面的命令:
- 节点A上:CLUSTER SETSLOT 1 MIGRATING NODEB
- 节点B上:CLUSTER SETSLOT 1 IMPORTING NODEA
其中,MIGRATING表示数据要从这个节点迁出,而IMPORTING表示数据要往这个节点迁入。
执行完这两个命令后,节点A中的slot1不在创建新的key。一个叫做redis-trib的特殊的程序负责把所有的key从节点A迁移到节点B。redis-trib会执行下面的命令:
- CLUSTER GETKEYSINSLOT slot count
这个命令会返回count个key,对于每个返回的key,redis-trib执行下面的命令:
- MIGRATE target_host target_port key target_database id timeout
这个命令会原子地把一个key从节点A迁移到节点B。具体来说,MIGRATE命令会连接目标节点,并发向目标节点发送这个key,一旦目标节点收到这个key,则从自己的数据库中删除这个key,在这个过程中,节点A和节点B都会加锁。
在把所有的key迁移完后,再分别在两个节点上执行下面的命令:
- CLUSTER SETSLOT slot NODE nodeA
把所有的key迁移完一般需要一些时间,也就是说在开始迁移后和完成迁移前,在这个窗口期内,key的实际的分布,与hash slot map里记录的是不一致的,client按照hash slot map访问key,会出现错误。
Redis Cluster通过ASK redirection来解决这个问题。按照client端的hash slot map,slot1的key一定会发给节点A,节点A收到这个请求后,如果发现这个key已经迁移到节点B了,那么就会给client回复ASK redirection,client收到ASK redirection后,会向节点b先发送一个ASKING命令,之后在发送对这个key的请求。
14、Configuration的实际存储
Hash slot map和node table都是逻辑上的结构,他们在Redis Cluster中的实际存储结构稍有不同(详情看结尾参考资料1、2、3、4)。
在节点的内存中,用两个变量来存储这两个信息:
- myself变量:myself代表本节点,是一个ClusterNode类型的变量,这个变量中,包含本节点的configEpoch,还包括slaveof,如果是slave节点则在slaveof中记录着它的master节点,还包括一个bitmap,代表这个节点负责的所有的slot的槽位值。这个bitmap有2048个byte组成,一总是16384(2048*8)个bit,每个bit代表一个slot,bit置1,代表这个节点负责这个slot;
- cluster变量:代表了所在集群的状态,它包含currentEpoch、lastVoteEpoch和slots数组,slots数组的index代表了slot,数组的每个成员都指向一个节点,是一个ClusterNode类型的变量,与myself变量的类型一样。
所有Configuration的更改都会被保存到磁盘中,具体来讲是保存到一个名字叫node.conf的文件中,这个文件是Redis Cluster负责写入的,不需要人工配置。
node.conf按照节点维度进行保存。每一行对应一个节点,每行分别包含这些信息:id,ip:port,flag,slaveof,ping timestamp, pong timespamp,configEpoch,link status,slots。
所有的节点结束后,会在文件的最后保存curruntEpoch和lastVoteEpoch两个变量。其中flag字段是枚举类型,会指明这个节点是不是自己,节点类型是master还是slave。
如果是slave节点,则会在slaveof字段记录其master节点的id。如果是master节点,则在最后多一个slots字段,记录着这个节点负责着哪些slot。Flags字段还记录着其他非常重
要的状态,本文就不继续展开了。
同样,ping timestamp、pong timestmap、link staus三个字段本文也不继续展开了。
具体的node.conf文件类似下面的例子:
- [root@10.112.178.141 data]# cat nodes-6384.conf
- fb763117270d14205c41174605b15741co03a945 10.112.178.174:6383 slave 5e35bda1a44c8d781eb54e08be88a3bab42070f3 0 1596683852819 2 connected
- 3dc5890fb1591e3b20196f81eb5f2f99754253e8 10.112.178.141:6383 master - 0 1596683851915 1 connected 0-5461
- f1967b687c9b2c27108cce08517e98e7a80d5e7e 10.112.178.171:6383 slave 3dc5890fb1591e3b20196f81eb5f2f99754253e8 0 1596683850813 1 connected
- 2bbab7353e973e991566df3bb52afb4857a7bf25 10.112.178.171:6384 slave 1f0a8cf1bfd0c915ef404482f3dc6bf5c7cf41f5 0 1596683848812 3 connected
- 5e35bda1a44c8d781eb54e08be88a3bab42070f3 10.112.178.142:6383 master - 0 1596683849813 2 connected 5462-10923
- 1f0a8cf1bfd0c915ef404482f3dc6bf5c7cf41f5 10.112.178.141:6384 myself,master - 0 0 3 connected 10924-16383
节点启动时会读取node.conf文件,把里面的信息加载到myself和cluster两个变量中。Slot信息会被转换成bitmap保存在myself变量中。并且slot信息还会逆向的转换成slot到节点的映射保存在cluster变量中。
hash slot map变更或者node table变更,就是修改内存中的myself变量和cluater变量,并且每次变更都会把这两个变量序列化转化后保存到node.conf中。
15、查看configuration
Redis Cluster提供了两个命令来查看configuration:
第一个是CLUSTER SLOT命令,用来展示hash slot维度的信息,CLUSTER SLOT命令的展示如下:
- 127.0.0.1:7000> cluster slots
- 1) 1) (integer) 5461
- 2) (integer) 10922
- 3) 1) "127.0.0.1"
- 2) (integer) 7001
- 4) 1) "127.0.0.1"
- 2) (integer) 7004
- 2) 1) (integer) 0
- 2) (integer) 5460
- 3) 1) "127.0.0.1"
- 2) (integer) 7000
- 4) 1) "127.0.0.1"
- 2) (integer) 7003
- 3) 1) (integer) 10923
- 2) (integer) 16383
- 3) 1) "127.0.0.1"
- 2) (integer) 7002
- 4) 1) "127.0.0.1"
- 2) (integer) 7005
第二个是CLUSTER NODE命令,用来展示node table维度的信息,CLUSTER NODE命令的展示如下:
- $ redis-cli cluster nodes
- d1861060fe6a534d42d8a19aeb36600e18785e04 127.0.0.1:6379 myself - 0 1318428930 1 connected 0-1364
- 3886e65cc906bfd9b1f7e7bde468726a052d1dae 127.0.0.1:6380 master - 1318428930 1318428931 2 connected 1365-2729
- d289c575dcbc4bdd2931585fd4339089e461a27d 127.0.0.1:6381 master - 1318428931 1318428931 3 connected 2730-4095
CLUSTER NODE、CLUSTER SLOT两个命令可以连接到任意节点上执行,这两个命令都是读取的这个节点的本地信息,根据gossip的特性,存在这两个命令展示的不是最新的configuration的可能性。
16、Conflict
虽然前面讲的failover过程通过大多数master投票的方式保证只有一个slave选中,并且产生唯一的configEpoch。但是Resharding的过程却没有经过大多数的master的投票。
执行slot迁移时,仅仅是在集群中所有configEpoch中最大的那个configEpoch的基础上,再加一而得到的。并且由于Resharding一般包括多个slot的迁移,Redis cluster目前的做法是,在一次resharding过程中,所有的slot迁移使用的configEpoch都是第一个slot迁移时产生的那个configEpoch。
而failover和resharding都会修改hash slot map,如果在resharding的过程中发生了failover,这就有可能导致对hash slot map的修改产生冲突。另外,手动failover也是不经过master投票的,也就是执行CLUSTER FAILOVER命令(带TAKEOVER参数)。
产生冲突就是指针对同一个slot,slot被修改成映射到不同的节点上,并且这些修改具有相同的configEpoch。
为了解决这个问题,Redis cluster需要存在一个冲突解决的机制。如果一个master发现相同的configEpoch,则比较一下两个节点的id,id小的节点,把自己currentEpoch加一,作为自己的configEpoch。
三、Write Safety
由于有冲突的存在,可能导致不同的节点上的hash slot map不一致,取决于连接的节点不同,一部分client可能会把某个slot的key写入到一个节点中,而另外一部分client会把同样slot的key写入到另外一个节点中。当冲突被解决后,其中一个节点上接受的写入会丢失。
另外,由于master和slave之间的数据复制是异步的,在failover时如果slave还没有收到最新的数据,就发生了failover,那么这部分写入就会丢失。Redis cluster在这方面做了一个优化,当一个slave发现master发生了宕机,它不会立即开始选举的过程,它会等待一个时间,这个时间计算公式如下:
- DELAY = 500 milliseconds + random delay between 0 and 500 milliseconds + SLAVE_RANK * 1000 milliseconds
这个计算公式中,
- 第一部分是一个固定500毫秒的时间,这是为了给master充分的时间,也发现节点宕机这个事实;
- 第二个是随机等待一段时间,这是为了尽量避免多个slave同时发现master宕机,然后同时开始选举,导致master被瓜分,从而导致所有的选举都不成功;
- 第三部分是slave的rank,rank主要取决于slave的复制进度,复制的数据越多,则rank越小,也就是越短的等待时间,越先开始选举,有更大的可能性被选成新的master。但这仅仅是个优化,不能完全防止丢数据的可能。
作者介绍
陈东明,现任国美在线基础架构总监。曾任饿了么北京技术中心任架构组负责人,负责产品线架构设计及基础架构研发工作;曾任百度架构师,负责即时通讯产品的架构设计。具有丰富的大规模系统构建和基础架构研发经验,善于复杂业务需求下的大并发、分布式系统设计和持续优化。个人公众号:dongming_cdm。