我们在做SQL查询的时候,经常会用到各各种关联查询,对于不同的联接,效率还是有差别的,具体该用哪种呢?虽说数据库会做一些查询的优化,但了解原理,能有助我们直指核心。
开始join吧。
我们分析三种常见的join: Merge join,Hash join 和 NestedLoop Join。在此之前,我们先介绍一些关键词:
Inner ralation 和 outer relation。
一个 relation 可以是:
- 一张表
- 一个索引
- 一个前面操作的中间结果
当你在对两个 relation 进行 Join 的时候,join 算法对inner 和 outer relation 的方式是有区别的。outer relation 是左数据集, inner relation 是右数据集。
比如说 A JOIN B,此时 A 是 outer relation,B 是 inner relation。而且一般 A JOIN B 和 B JOIN A 用时是不一样的。
后面我们假设 outer relation 有 N 个元素, inner relation 有 M个元素。不过实际的优化器里,可以从统计信息中拿到确切的值。
Nested loop join

嵌套关联是最容易的一个。过程大概是:
遍历 outer relation 的每一行
然后去查找inner relation 的每一行是否匹配
写成伪代码是这样:
- nested_loop_join(array outer, array inner)
- for each row a in outer
- for each row b in inner
- if (match_join_condition(a,b))
- write_result_in_output(a,b)
- end if
- end for
- end for
因为两重遍历,所以复杂度是 O(N*M)。对应到磁盘的I/O,在outer relation中,N 行中的每一行,都需要从inner relation 中循环读取M行数据。
所以这个算法需要从磁盘读 N + N*M行数据。但是,如果 inner relation 足够小,可以放到内存里的话,就只需要读 M + N 次了。虽然说在时间复杂度上没什么变化,但在磁盘I/O上这个方式还不错,因此, inner relation 可以被索引替代,磁盘I/O也更有利。
Hash join
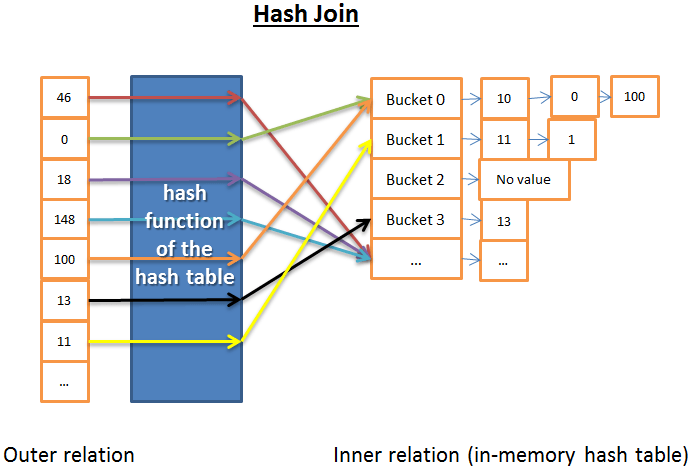
哈希连接更复杂,不过很多时候也比循环嵌套连接成本要低
哈希连接的原理是:
- 从 inner relation 中获取所有元素
- 保存哈希表到磁盘
- 在内存中建立一个哈希表
- 逐条读取outer relation 的所有元素
- (用哈希表的哈希函数)计算每个元素的哈希值,来查找inner relation 关联的哈希桶
- 查看 outer relation 的元素是否有哈希桶内的匹配。
在时间复杂度方面我们需要做点假设简化问题:
- inner relation 被划分成 X 个哈希桶
- 哈希函数接近均匀地分布每个 relation 内数据的哈希值,相当于说哈希桶大小是一致的。
- outer relation 的元素与哈希桶内的所有元素的匹配,成本是哈希桶内元素的数量。
时间复杂度是 (M/X) * N + cost_to_create_hash_table(M) + cost_of_hash_function*N。如果哈希函数创建了足够小规模的哈希桶,那么复杂度就是 O(M+N)。
还有个哈希联接的版本,对内存更友好,但是对磁盘 I/O 不够有利。情况是这样的:
- 计算outer relation 和 inner relation 双方的哈希表
- 保存哈希表到磁盘
- 然后逐个比较两个 relation 的哈希桶(一个关系读到内存里,另一个逐行读取)
Merge join
合并联接是唯一产生排序的联接算法。
注:这个简化的合并联接不区分内表或外表;两个表扮演同样的角色。但实际实现方式是不同的,比如当处理重复值时。
- (可选)排序联接运算:两个输入源都按照联接关键字排序。
- 合并联接运算:排序后的输入源合并到一起。
(1) 排序
我们已经说过合并排序,在这里合并排序是个很好的算法。
有些时候数据集已经排序了,比如:
- 如果表内部就是有序的,比如联接条件里有一个索引组织表
- 如果 relation 是联接条件里的一个索引
- 如果联接是作用在一个已经排序的查询的中间结果
(2) 合并联接
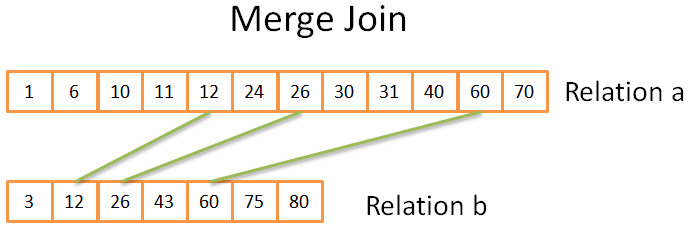
这部分与我们说过的合并排序中的合并运算非常相似。区别只在于我们不从两个关系里挑选所有元素,只选相同的元素。
大致原理如下:
- 在两个 relation 里,比较当前元素(当前的等号第一次出现)
- 相同的时候,就把两个元素都放到结果里,再比较两个关系里的下一个元素
- 不相同的话,就去带有最小元素的关系里找下一个元素
- 重复 1、2、3步骤直到其中一个关系的最后一个元素。
因为两个关系都是已排序的,你不再需要「回过头找」,所以这个方法很有效。
这个算法是个简化版本,它没有处理两组数据中相同数据出现多次的情况。
哪个连接算法最好?
如果有最好的,就没必要弄那么多种类型了。由于很多因素要考虑,所以不会有一个简单的答案,需要考虑的因素例如这些:
- 空闲内存大小:没有足够的内存的话,就和有力的哈希联接,至少是完全内存中哈希联接 说bye bye吧。
- 两个数据集的大小:如果一个大表联接一个很小的表,嵌套循环联接就比哈希联接要快,因为后者有创建哈希的成本;如果两个表都非常大,那么嵌套循环联接CPU成本就很高。
- 是否有索引:有两个 B+树索引的话,合并联接似乎是更聪明的选择。
- 结果集是否需要排序:即使你用到的是无序的数据集,你也可能想用成本较高的合并联接(带排序的),因为最终的结果是有序的,你可以把它和另一个结果集通过合并联接合起来(也可能查询用的 ORDER BY/GROUP BY/DISTINCT 等操作符隐式或显式地要求一个排序结果)。
- 关系是否已经排序:这时候合并联接是最佳的选择。
- 联接的类型:是等值联接(比如 tableA.col1 = tableB.col2 )还是内联接?外联接?笛卡尔乘积?或者自联接?有些联接在特定环境下是无法工作的。
- 数据的分布:假如联接条件的数据是倾斜的(比如根据姓氏来联接人,会有很多同姓的人),用哈希联接将是个灾难,因为是哈希函数将产生分布极不均匀的哈希桶。
- 如果你希望联接操作使用多线程或多进程。
【本文为51CTO专栏作者“侯树成”的原创稿件,转载请通过作者微信公众号『Tomcat那些事儿』获取授权】