一 序
人工智能(AI)是一个自从计算机被发明开始就存在的一个技术领域。从1956年Marvin Minsky、John McCarthy等人在达特茅斯学院的会议中第一次提出人工智能这个概念开始,AI这个领域的概念、技术和研究经历了非常长足的发展。
其中,机器学习是人工智能领域当中最核心也是最广泛应用的一个子领域,旨在通过一系列数学的方法,如统计、概率论、线性代数等方法,设计和分析让计算机可以自动学习的算法。这些算法通过从大量数据中获取规律,来对未知的的数据进行预测和决策。
机器学习的算法被广泛地用到计算机视觉、语音、自然语言处理、数据挖掘、搜索、广告、游戏、机器人、金融等各种行业。
随着深度学习的兴起,产业界对于机器学习产生了非常强烈的兴趣,也使得机器学习领域开始迅速地走向工程化和系统化。
除了机器学习算法本身的不断创新之外,数据和算力的增加也是不可忽视的:大量的数据,特别是移动互联网的兴起,使机器学习算法得以打破传统数据量的限制;由于GPGPU等高性能处理器开始提供大量的算力,又使得我们能够在可控的时间内(以天为单位甚至更短)进行exaflop级别的算法训练。
在这些的综合作用下,工业界开始浮现出大量的机器学习系统创新。以2011年Google Brain,即谷歌大脑为代表,机器学习开始迅速从实验室转向业界。
毫无疑问,深度学习(DeepLearning)是当下最热门的人工智能技术,在智能推荐、图像识别、机器翻译、计算广告、自动驾驶等领域都有突破性的进展和应用。而深度学习的成功很大部分得益于新的计算框架和异构计算硬件,譬如Tensorflow和NVIDIA GPU。
然而,对于算法工程师来说,要搭建这样一套学习和工作的环境不是一件容易的事情:需要一个特定版本的操作系统(最好是Linux),一张或多张GPU卡,安装GPU驱动,安装深度学习计算框架和其依赖的软件包等。在调试深度学习算法的过程中,如果说尝试不同的驱动版本和切换各种版本的软件库还勉强可以接受,那么切换硬件环境,特别是更换GPU卡就伤筋动骨了。
那么,有没有能够一劳永逸解决这些苦恼的方式?阿里云机器学习平台PAI出品的一款云端深度学习开发环境:DSW(Data Science Workshop)试图告诉你,这是个肯定的答案。
二 云端IDE:阿里巴巴机器学习与PAI-DSW
经过20年的快速发展,阿里巴巴已经组建了一个庞大的商业生态圈,并在支付、云计算、本地生活服务等行业保持互联网巨头地位。其中电商年交易额达到5.7万亿元、占据中国网购市场超6成份额,阿里云支撑了2019年双11 期间峰值 54.4 万笔/秒、单日数据处理量达到 970PB 的世界级的流量洪峰,成为业界第一个实现此壮举的云计算公司。
阿里云机器学习平台正是伴随着这样庞大而复杂的阿里经济体业务需求成长起来的。下面我们将带着大家掀开阿里云机器学习技术大图的一角,看看阿里云机器学习,特别是机器学习工程上的发展、沉淀和创新。
阿里机器学习技术大图
我们从用户和技术的两个角度来梳理机器学习的技术体系大图。从用户的角度来说,根据使用机器学习的深度不同,在云栖大会上,我们展示了飞天AI平台的技术分层关系:
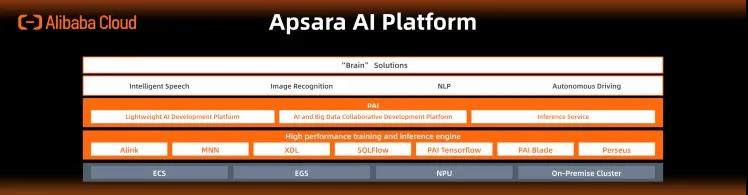
核心样例
从技术的角度说,机器学习从算法到底层的硬件,都涉及到不同的技术方向。下面是我们对于核心技术能力上的一个总体描述:
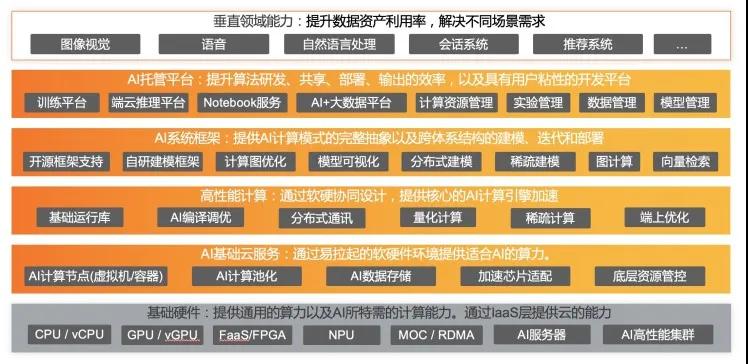
每个技术方向上都形成各自的布局和沉淀,接下来我们会重点讲述作为机器学习重要组成部分的工程能力体系建设。
机器学习工程能力体系
阿里云在机器学习工程体系建设上,也经历了各领域业务需求驱动和技术驱动分阶段螺旋式递进上升的过程。由最初的通过传统机器学习算法进行数据价值的粗加工,到今天以深度学习为主、支撑各类“行业大脑”解决方案的人工智能工程体系。
阿里云的机器学习工程能力体系建设始终围绕着更高效的融合人工智能三要素(算法、数据、算力)进行展开,即追求不断提升整个工程体系中的计算效率、数据效率以及工程效率,从而能够更好的支撑阿里经济体各方面业务快速发展的需求,并通过阿里云对外进行技术输出,推动人工智能领域的技术变革,产生更大的社会效益,实现普惠人工智能。
经过多年的发展创新,阿里云在AI托管平台技术层进行了系统性的建设,极大提升了算法研发、共享、部署、输出的效率,在此基础上沉淀出多个具有用户粘性和场景差异化的开发平台,这里我们选取阿里云机器学习PAI(Platform of Artificial Intelligence)作为代表来着重来介绍。
PAI是一款覆盖机器学习全流程的一站式机器学习平台产品,集数据预处理、特征工程、自动调参、模型训练、在线预测为一体,为用户提供低门槛、高性能的云端机器学习服务。
PAI相关技术脱胎于阿里集团内数十个BU的上千个业务体系,沉淀了大量的覆盖各个领域的优质分布式算法、框架、平台等,同时也在不断完善和扩充机器学习生态。
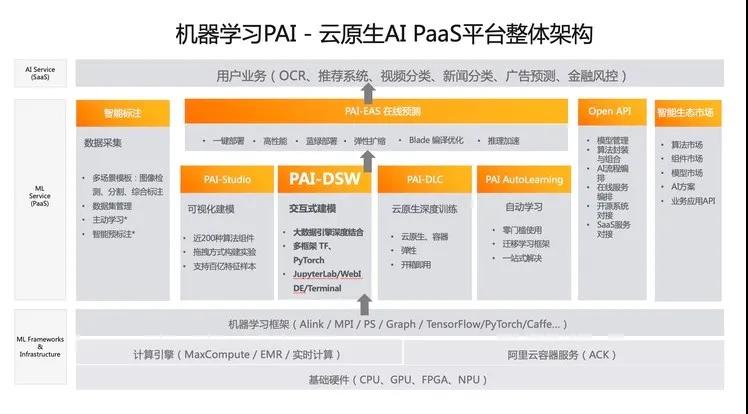
阿里云机器学习PAI-DSW
作为在AI战线上辛勤耕耘的算法工作者,你是否也常常遇到下面的情形:
- 算法需要运行在GPU上,可是长时间申请不到GPU机器,只能干着急。
- 终于GPU机器申请到了,安装GPU驱动和各种依赖,感觉是在浪费时间。
- 好不容易环境弄好了,当某天更新算法代码后变得很慢, 排查半天才发现是GPU驱动需要升级补丁,很是无奈。
- 生产环境机器网络隔离,在线上要debug代码,只能使用GDB在命令行进行,开发效率大大降低。
- 在本地采用PyCharm这样的IDE开发好代码,而数据在生产环境,不允许下载,只能把代码拷贝到线上机器运行,发现问题时,又得回到本地修改调试后再来一遍,非常不便。
- PAI Studio采用图形化拖拽式,像搭积木一样分分钟就构建一个完整的工作流,很炫酷。但想要定制发布自己的组件时,却不知从何下手。
- 在长期与算法工程师同学沟通合作的过程中,我们发现了算法工程师面临的这些问题。提升机器学习工程效率,降低人工智能使用门槛,急需一个简单、轻量、好用的工具平台,从而让算法工程师更加专注于模型设计本身。PAI DSW就是PAI团队为解决算法工程师的以上痛点,新推出的一款云端机器学习开发IDE。
- PAI-DSW集成了Jupyterlab、WebIDE等多种开源项目,在阿里巴巴集团内上百个BU和上千名工程师的打磨之下性能和功能上都进行了一定的调优。数据上打通了ODPS等多个数据源,方便用户在构建模型的时候免去重新构建数据管道的工作。
同时,在深度学习上,PAI-DSW内置了Tensorboard,可以通过简单的拖拽的方式来帮助深度学习的开发者更好的完成深度学习场景下神经网络的建模。下图展示了DSW在机器学习平台PAI产品架构中的位置:
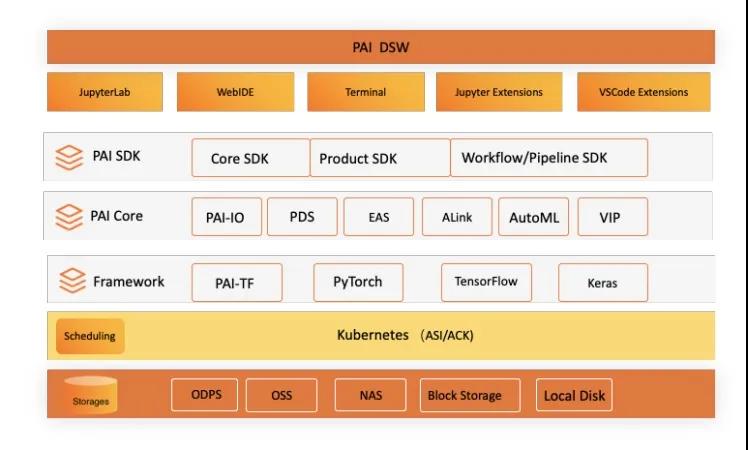
DSW在机器学习平台PAI产品架构中的位置
简单来说,PAI-DSW可以实现多实例、多环境,GPU/CPU资源、JupyterLab、WebIDE以及全屏使用Terminal无干扰工作。目前PAI-DSW已经向所有阿里云的用户免费开放了探索者版,只需要登陆阿里云然后打开 https://dsw-dev.data.aliyun.com/#/ 即可开始云上数据科学之旅。接下来将详细介绍如何使用PAI-DSW这一简单好用的工具。
三 新手上路:PAI-DSW实验室创建攻略
Step 1 : 创建并打开你的DSW实验室
前往 https://dsw-dev.data.aliyun.com/#/ 即可创建并进入你的实验室。之前需要确保已经登陆了阿里云账号和天池账号。进入之后等待几秒后我们会看到如下页面:
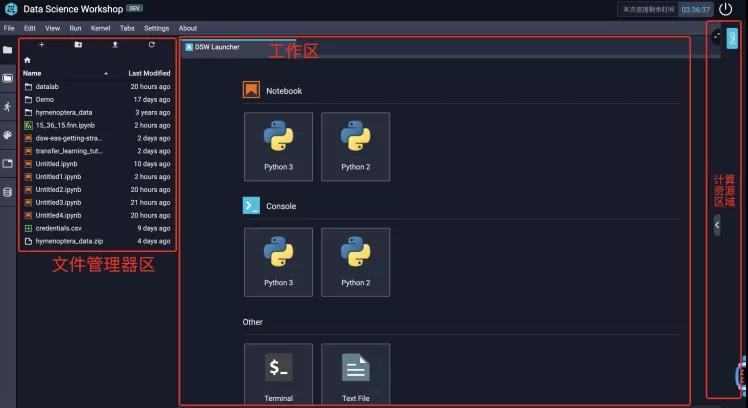
左侧是DSW实验室的文件区,双击文件夹即可进入。中间是工作区,右侧是计算资源区域,点击右边计算资源区的箭头,即可弹出资源详情,如下图所示:
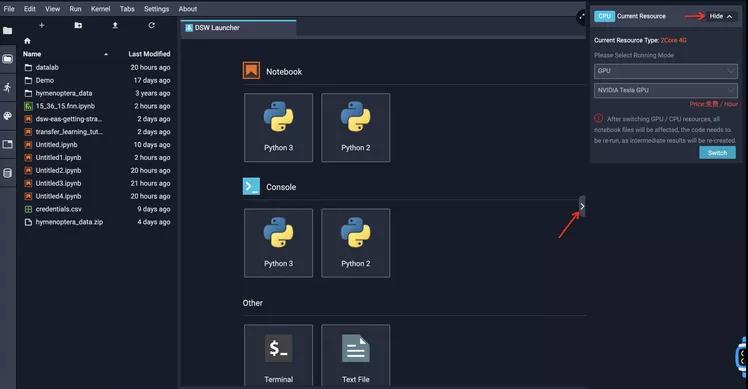
这里我们也可以点击切换按钮选择我们需要的资源进行切换。
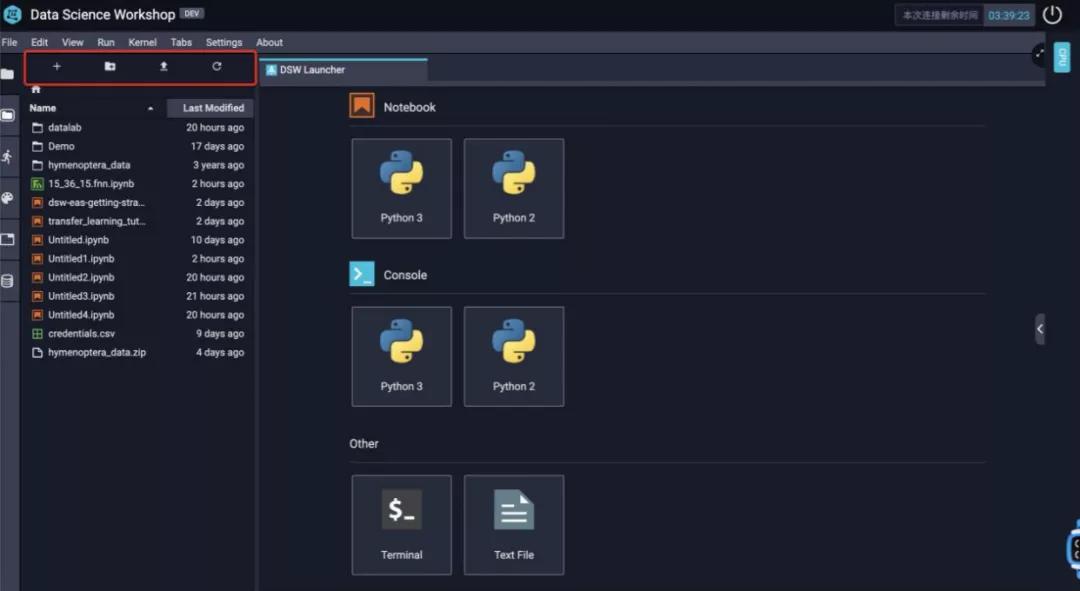
在文件资源管理区的顶部还有4个按钮,从左到右分别对应的是:打开DSW Launcher启动器,新建文件夹,上传文件以及刷新当前文件夹。
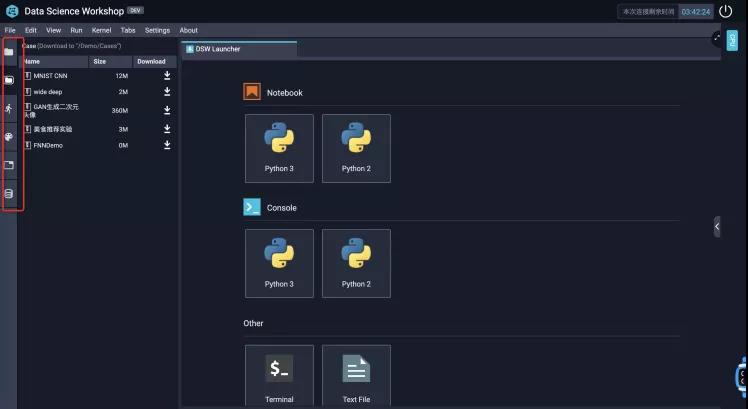
在文件夹左侧还有一栏Tab,每个图标从上到下分别代表了:文件资源管理器,案例代码,正在运行的Notebook,命令面板,在工作区打开的Tab,以及天池的数据搜索引擎。
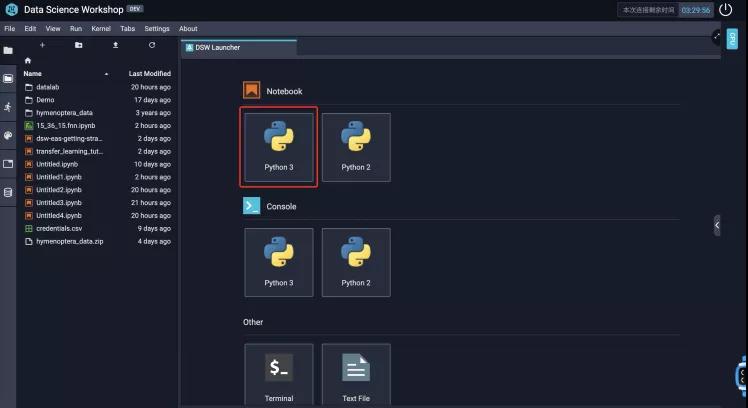
然后我们回到DSW Launcher启动器,也就是工作区默认打开的界面,然后点击Notebook区域中的Python3,如下图所示:
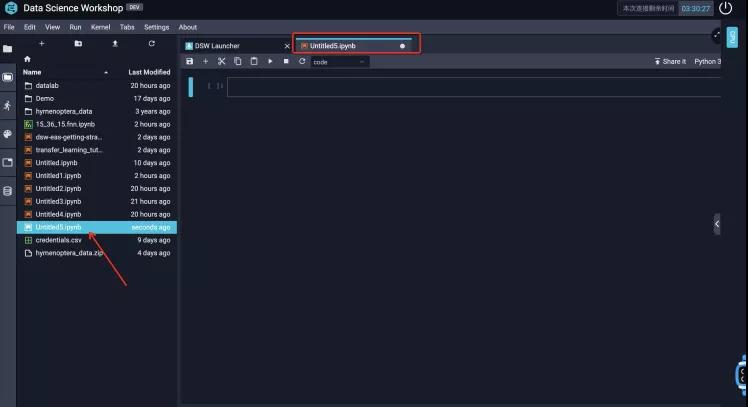
Step 2 : 创建一个Notebook
点击了Python3图标后,DSW会自动创建一个ipynb notebook文件。如下图所示:
Step 3 :写下你的第一行代码并运行
用鼠标点击第一个框框(我们下面以Cell称呼),我们就可以开始从只读模式进入编辑模式开始写代码了。
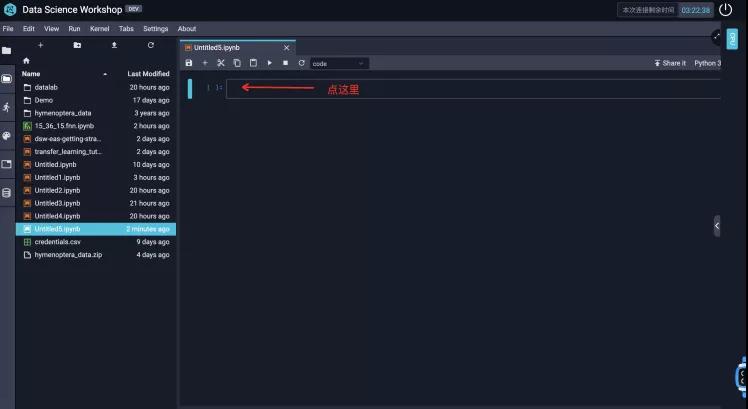
这里我们可以先输入一个简单的:
然后我们同时按下 shift+ enter回车这两个键,就可以看到我们的执行结果了,如下图所示:
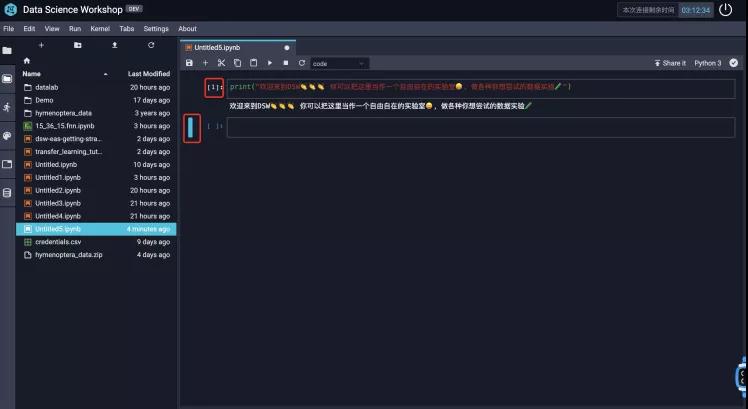
图中标红的数字1表示这个Cell是第一个被执行的,蓝色区域则表示当前聚焦(Focus)的Cell。我们可以在Focus的Cell按下 Enter回车键进入编辑模式。我们也可以按下 Esc键来退出编辑模式回到只读模式。在只读模式中,我们可以通过方向键上下来切换Focus的Cell。
Step 4 : 计算一个斐波那契数列
很好,现在你已经熟悉了DSW最基本的运行Cell的方式,接下来就让我们编写一个简单的斐波那契数列计算的函数来计算这个数列的第10项。把下方的代码拷贝到新生成的Cell中即可:
同样,输入代码后,我们按下 shift+ enter回车 这两个键,就可以看到我们的执行结果了,如下图所示:
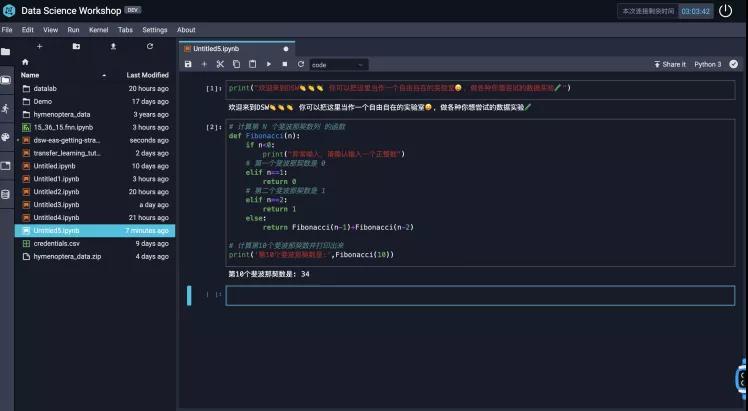
这样,你就掌握了DSW最基本的创建Notebook,便携代码和运行代码的方式。
四 快速进阶:PAI-DSW案例实战指南
本着理论与实践相结合的方针,本部分将手把手教你从实战场景参与进来,实现从入门到快速进阶。
案例:大数据算命系列之用机器学习评估你的相亲战斗力
"用姓名测试爱情,80%准确率!俗话说,名如其人,缘分就是人生的后半生,为了寻找真缘分的大有人在,因此也就有了姓名缘分测试。您现在是不是也正在心动犹豫,也想要一个属于自己的名字配对缘分测试了呢?那就请您赶紧行动吧!" 以上这段话,你一定已经在很多个微信公众号、电视节目,甚至奇奇怪怪的小网站上看到过。
你一定很好奇,这个缘分测试背后到底是不是有科学依据支撑的。
今天,虽然不能直接帮你测试你和某个特定的人直接的缘分,但是我们可以借助哥伦比亚大学多年研究相亲找对象的心血,通过几个简单的特征来评估你的相亲战斗力指数。
具体模型的测试页面在这里[1]。在正式开始实验之前,我们需要寻找一个简单好用方便上手的工具,这里推荐阿里云的DSW探索者版[2],它对于个人开发者是免费的,同时还有免费的GPU资源可以使用,同时实验的数据还会免费保存30天,不需要购买,只要登陆就可以使用。今天我们就会通过这个工具来探索人性的奥秘,走进两性关系的神秘空间嘿嘿嘿。
整个实验的数据收集于一个线下快速相亲的实验[3]。在这个实验中,参与者被要求参加多轮与异性进行的快速相亲,每轮相亲持续4分钟,在4分钟结束后,参与者双方会被询问是否愿意与他们的对象再见面。只有当双方都回答了“是”的时候,这次相亲才算是配对成功。
同时,参与者也会被要求通过以量化的方式从外观吸引力,真诚度,智商,风趣程度,事业心,兴趣爱好这六个方向来评估他们的相亲对象。
这个数据集同时也包含了很多参加快速相亲的参与者的其他相关信息,比如地理位置,喜好,对于理想对象的偏好,收入水平,职业以及教育背景等等。关于整个数据集的具体特征描述可以参考相关文件[4]。
本次我们实验的目的主要是为了找出,当一个人在参加快速相亲时,到底会有多高的几率能够遇到自己心动的人并成功牵手。
在我们建模分析探索人性的秘密之前,让我们先读入数据,来看看我们的数据集长什么样。
通过观察,我们不难发现,在这短短的两年中,这个实验的小酒馆经历了8000多场快速相亲的实验。由此我们可以非常轻易的推断出,小酒馆的老板应该赚的盆满钵满(大雾)。
然后从数据的宽度来看,我们会发现一共有接近200个特征。关于每个特征的具体描述大家可以参考这篇文档[5]。然后我们再观察数据的完整度,看看是否有缺失数据。
通过以上代码,我们不难发现,其实还有很多的特征是缺失的。这一点在我们后面做分析和建模的时候,都需要关注到。因为一旦一个特征缺失的数据较多,就会导致分析误差变大或者模型过拟合/精度下降。看完数据的完整程度,我们就可以继续往下探索了。
然后第一个问题就来了,在这8000多场的快速相亲中,到底有多少场相亲成功为参加的双方找到了合适的伴侣的?带着这个问题,我们就可以开始我们的第一个探索性数据分析。
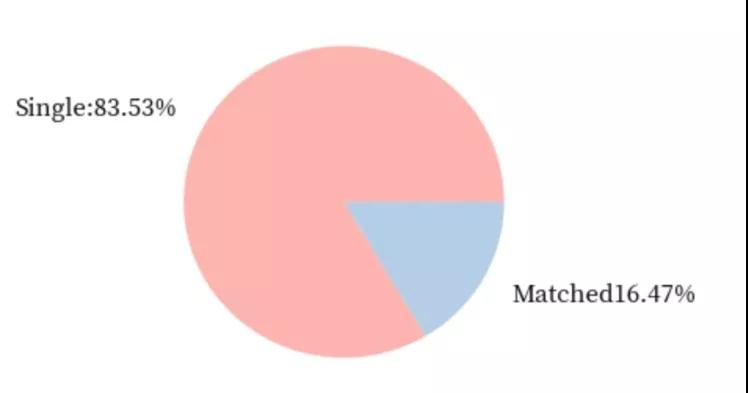
从上边的饼图我们可以发现,真正通过快速相亲找到对象的比率仅有16.47%。
然后我们就迎来了我们的第二个问题,这个比率和参加的人的性别是否有关呢?这里我们也通过Pandas自带的filter的方式:
来筛选数据集中的性别。通过阅读数据集的文档,我们知道0代表的是女生,1代表的是男生。然后同理,我们执行类似的代码:
来找出女生和男生分别在快速相亲中找到对象的几率的。
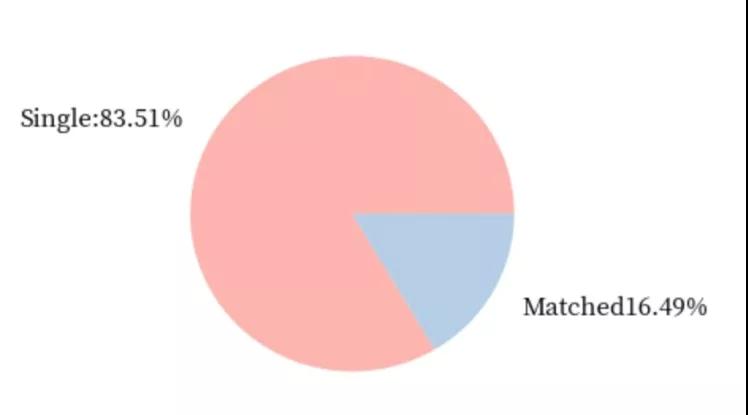
女生的几率:
男生的几率:
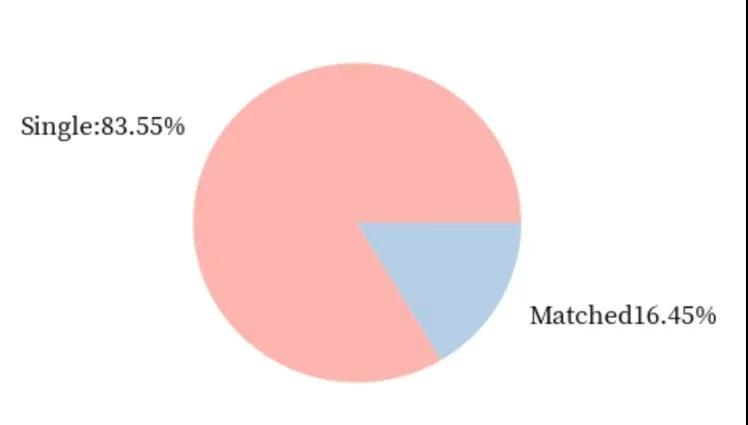
不难发现,在快速相亲中,女生相比于男生还是稍微占据一些优势的。女生成功匹配的几率比男生成功匹配的几率超出了0.04。
然后第二个问题来了:是什么样的人在参加快速相亲这样的活动呢?真的都是大龄青年(年龄大于30)嘛?这个时候我们就可以通过对参加人群的年龄分布来做一个统计分析。
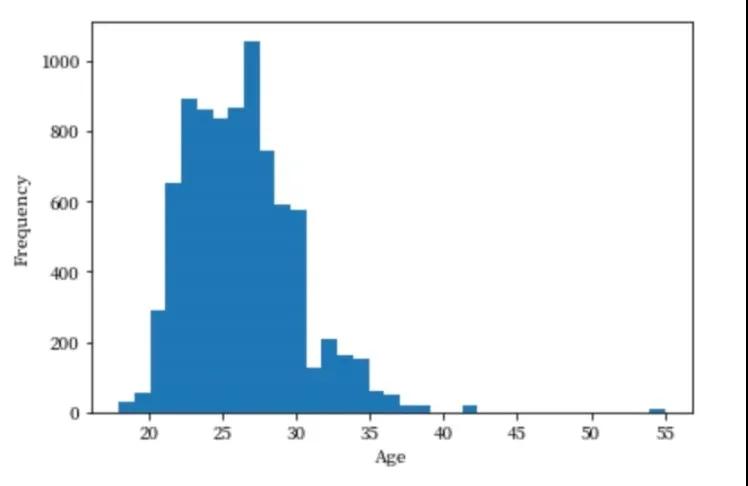
不难发现,参加快速相亲的人群主要是22~28岁的群体。这点与我们的预期有些不太符合,因为主流人群并不是大龄青年。接下来的问题就是,年龄是否会影响相亲的成功率呢?和性别相比,哪个对于成功率的影响更大?这两个问题在本文就先埋下一个伏笔,不一一探索了,希望阅读文章的你能够自己探索。
但是这里可以给出一个非常好用的探索相关性的方式叫做数据相关性分析。通过阅读数据集的描述,我已经为大家选择好了一些合适的特征去进行相关性分析。这里合适的定义是指:1)数据为数字类型,而不是字符串等无法量化的值;2)数据的缺失比率较低。
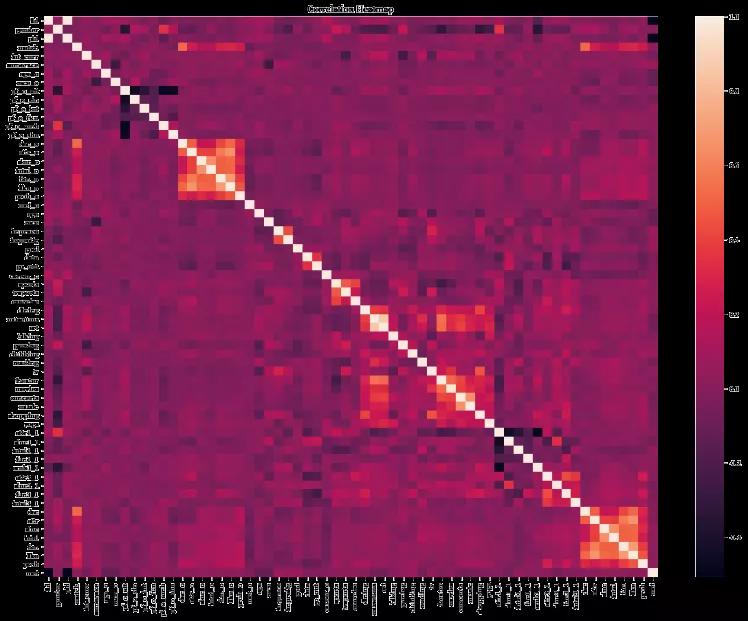
通过上面这张图这张相关性分析的热力图,我们可以先关注一些特别亮的和特别暗的点。比如我们可以发现,在pf_o_att这个表示相亲对象给出的外观吸引力这个特征上,和其他相亲对象给出的评分基本都是严重负相关的,除了pf_o_fun这一特征。由此我们可以推断出两个点:
- 大家会认为外观更加吸引人的人在智商,事业心,真诚度上表现会相对较差。换句话说,可能就是颜值越高越浪。
- 幽默风趣的人更容易让人觉得外观上有吸引力,比如下面这位幽默风趣的男士(大雾):
然后我们再看看我们最关注的特征 match,和这一个特征相关性比较高的特征是哪几个呢?不难发现,其实就是:
这几个特征,分别是相亲对方给出的关于外观,真诚度,智商,风趣程度,事业线以及兴趣爱好的打分。接下来我们就可以根据这个来进行建模了。首先我们将我们的特征和结果列都放到一个Dataframe中,然后再去除含有空值的纪录。最后我们再分为X和Y用来做训练。当然分为X,y之后,由于我们在最开始就发现只有16.47%的参与场次中成功匹配了,所以我们的数据有严重的不均衡,这里我们可以用SVMSMOTE[6]来增加一下我们的数据量避免模型出现过度拟合。
数据准备好之后,我们就可以进行模型的构建和训练了。通过以下代码,我们可以构建一个简单的逻辑回归的模型,并在测试集上来测试。
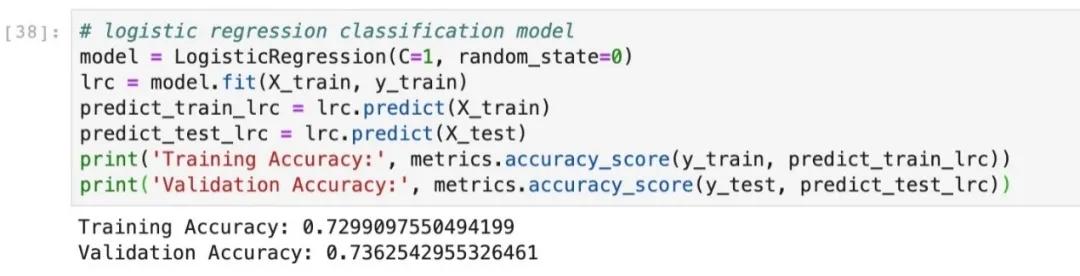
我们可以看到结果为0.83左右,这样我们就完成了一个预测在快速相亲中是否能够成功配对的机器学习模型。针对这个模型,数据科学老司机我还专门制作了一个小游戏页面[7],来测试你的相亲战斗力指数。
相关链接
[1]https://tianchi.aliyun.com/specials/promotion/dsw-hol?referFrom=alijishu
[2]https://dsw-dev.data.aliyun.com/#/
[3]https://faculty.chicagobooth.edu/emir.kamenica/documents/genderDifferences.pdf
[4]https://pai-public-data.oss-cn-beijing.aliyuncs.com/speed_dating/Speed%20Dating%20Data%20Key.doc
[5]https://pai-public-data.oss-cn-beijing.aliyuncs.com/speed_dating/Speed%20Dating%20Data%20Key.doc
[6]https://imbalanced-learn.readthedocs.io/en/stable/generated/imblearn.over_sampling.SVMSMOTE.html
[7]https://tianchi.aliyun.com/specials/promotion/dsw-hol?referFrom=alijishu
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】