本文转载自微信公众号「无敌码农」,作者无敌码农 。转载本文请联系无敌码农公众号。
原文链接:https://mp.weixin.qq.com/s/MFSvDWtue4YruFV3jyLQVw
在本篇文章中我将以在Mac笔记本中安装两台Ubantu系统的方式,演示如何部署一套具备一个控制节点(Master)和一个计算节点(Worker)的Kubernetes学习集群。
1、系统环境准备
要安装部署Kubernetes集群,首先需要准备机器,最直接的办法可以到公有云(如阿里云等)申请几台虚拟机。而如果条件允许,拿几台本地物理服务器来组建集群自然是最好不过了。但是这些机器需要满足以下几个条件:
- 要求64位Linux操作系统,且内核版本要求3.10及以上,能满足安装Docker项目所需的要求;
- 机器之间要保持网络互通,这是未来容器之间网络互通的前提条件;
- 要有外网访问权限,因为部署的过程中需要拉取相应的镜像,要求能够访问到gcr.io、quay.io这两个dockerregistry,因为有小部分镜像需要从这里拉取;
- 单机可用资源建议2核CPU、8G内存或以上,如果小一点也可以但是能调度的Pod数量就比较有限了;
- 磁盘空间要求在30GB以上,主要用于存储Docker镜像及相关日志文件;
在本次实验中由于条件有限,我是在Mac笔记本上通过虚拟软件准备了两台虚拟机,其具体配置如下:
- 2核CPU、2GB内存,30GB的磁盘空间;
- Unbantu 20.04 LTS的Sever版本,其Linux内核为5.4.0;
- 内网互通,外网访问权限不受控制;
2、Kubeadm一键部署工具简介
作为典型的分布式系统,Kubernetes的部署一直是困扰初学者进入Kubernetes世界的一大障碍。在发布早期Kubernetes的部署主要依赖于社区维护的各种脚本,但这其中会涉及二进制编译、配置文件以及kube-apiserver授权配置文件等诸多运维工作。目前各大云服务厂商常用的Kubernetes部署方式是使用SaltStack、Ansible等运维工具自动化地执行这些繁琐的步骤,但即使这样,这个部署的过程对于初学者来说依然是非常繁琐的。
正是基于这样的痛点,在志愿者的推动下Kubernetes社区终于发起了kubeadm这一独立的一键部署工具,使用kubeadm我们可以通过几条简单的指令来快速地部署一个kubernetes集群。后面的内容,就将具体演示如何使用kubeadm来部署一个Kubernetes集群。
3、安装Kubeadm及Docker环境
在准备的两台虚拟机中,分别安装Kubeadm部署工具及Docker环境。步骤如下:
1)、编辑操作系统安装源配置文件,添加kubernetes镜像源,命令如下:
- #添加Kubernetes官方镜像源apt-key
- root@kubenetesnode01:~#curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
- #添加Kubernetes官方镜像源地址
- root@kubernetesnode01:~# vim /etc/apt/sources.list
- #add kubernetes source
- deb http://apt.kubernetes.io/ kubernetes-xenial main
上述操作添加的是kubernetes的官方镜像源,如果apt.kubernetes.io因为网络原因访问不到,也可以换成国内Ubantu镜像源,如阿里云镜像源地址:
- #添加阿里云Kubernetes镜像源apt-key
- root@kubenetesnode01:~# curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
- #添加阿里云Kubernetes镜像源地址
- root@kubernetesnode01:~# vim /etc/apt/sources.list
- deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
2)、镜像源添加后更新apt资源列表,命令如下:
- root@kubernetesnode01:~# apt-get update
- Hit:1 http://cn.archive.ubuntu.com/ubuntu focal InRelease
- Hit:2 http://cn.archive.ubuntu.com/ubuntu focal-updates InRelease
- Hit:3 http://cn.archive.ubuntu.com/ubuntu focal-backports InRelease
- Hit:4 http://cn.archive.ubuntu.com/ubuntu focal-security InRelease
- Get:5 https://packages.cloud.google.com/apt kubernetes-xenial InRelease [8,993 B]
- Get:6 https://packages.cloud.google.com/apt kubernetes-xenial/main amd64 Packages [37.7 kB]
- Fetched 46.7 kB in 7s (6,586 B/s)
- Reading package lists... Done
3)、完成上述2步后就可以通过apt-get命令安装kubeadm了,如下:
- root@kubernetesnode01:~# apt-get install -y docker.io kubeadm
- Reading package lists... Done
- Building dependency tree
- Reading state information... Done
- The following additional packages will be installed:
- bridge-utils cgroupfs-mount conntrack containerd cri-tools dns-root-data dnsmasq-base ebtables kubectl kubelet kubernetes-cni libidn11 pigz runc socat ubuntu-fan
- ....
这里直接使用Ubantu的docker.io安装源。在上述安装kubeadm的过程中,kubeadm和kubelet、kubectl、kubernetes-cni这几个kubernetes核心组件的二进制文件都会被自动安装好。
4)、Docker服务启动及限制修改
完成上述步骤侧操作后,系统中会自动安装Docker引擎,但是在具体运行kubernetes部署之前需要对Docker的配置信息进行一些调整。
首先,编辑系统/etc/default/grub文件,在配置项GRUB_CMDLINE_LINUX中添加如下参数:
- GRUB_CMDLINE_LINUX=" cgroup_enable=memory swapaccount=1"
完成编辑后保存执行如下命令,并重启服务器,命令如下:
- root@kubernetesnode01:/opt/kubernetes-config# update-grub
- root@kubernetesnode01:/opt/kubernetes-config# reboot
上述修改主要解决的是可能出现的“docker警告WARNING: No swap limit support”问题。
其次,编辑创建/etc/docker/daemon.json文件,添加如下内容:
- {
- "exec-opts": ["native.cgroupdriver=systemd"]
- }
完成保存后执行重启Docker命令,如下:
- root@kubernetesnode01:/opt/kubernetes-config# systemctl restart docker
此时可以查看Docker的Cgroup信息,如下:
- root@kubernetesnode01:/opt/kubernetes-config# docker info | grep Cgroup
- Cgroup Driver: systemd
上述修改主要解决的是“Dockercgroup driver. The recommended driver is "systemd"”的问题。需要强调的是以上修改只是作者在具体安装操作是遇到的具体问题的解决整理,如在实践过程中遇到其他问题还需要自行查阅相关资料!
最后,需要注意由于kubernetes禁用虚拟内存,所以要先关闭掉swap否则就会在kubeadm初始化kubernetes的时候报错,具体如下:
- root@kubernetesnode01:/opt/kubernetes-config# swapoff -a
该命令只是临时禁用swap,如要保证系统重启后仍然生效则需要“edit /etc/fstab”文件,并注释掉swap那一行。
完成以上操作后启动系统Docker服务,命令如下:
- root@kubenetesnode02:~# systemctl enable docker.service
4、部署Kubernetes的Master节点
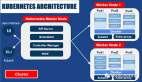
在Kubernetes中Master节点是集群的控制节点,它是由三个紧密协作的独立组件组合而成,分别是负责API服务的kube-apiserver、负责调度的kube-scheduler以及负责容器编排的kube-controller-manager,其中整个集群的持久化数据由kube-apiserver处理后保存在Etcd中。
要部署Master节点可以直接通过kubeadm进行一键部署,但这里我们希望能够部署一个相对完整的Kubernetes集群,可以通过配置文件来开启一些实验性的功能。具体在系统中新建/opt/kubernetes-config/目录,并创建一个给kubeadm用的YAML文件(kubeadm.yaml),具体内容如下:
- apiVersion: kubeadm.k8s.io/v1beta2
- kind: ClusterConfiguration
- controllerManager:
- extraArgs:
- horizontal-pod-autoscaler-use-rest-clients: "true"
- horizontal-pod-autoscaler-sync-period: "10s"
- node-monitor-grace-period: "10s"
- apiServer:
- extraArgs:
- runtime-config: "api/all=true"
- kubernetesVersion: "v1.18.1"
在上述yaml配置文件中“horizontal-pod-autoscaler-use-rest-clients: "true"”这个配置,表示将来部署的kuber-controller-manager能够使用自定义资源(CustomMetrics)进行自动水平扩展,感兴趣的读者可以自行查阅相关资料!而“v1.18.1”就是要kubeadm帮我们部署的Kubernetes版本号。
需要注意的是,如果执行过程中由于国内网络限制问题导致无法下载相应的Docker镜像,可以根据报错信息在国内网站(如阿里云)上找到相关镜像,然后再将这些镜像重新tag之后再进行安装。具体如下:
- #从阿里云Docker仓库拉取Kubernetes组件镜像
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:v1.18.1
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:v1.18.1
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:v1.18.1
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.18.1
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd-amd64:3.4.3-0
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2
- docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.7
下载完成后再将这些Docker镜像重新tag下,具体命令如下:
- #重新tag镜像
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.2 k8s.gcr.io/pause:3.2
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:1.6.7 k8s.gcr.io/coredns:1.6.7
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd-amd64:3.4.3-0 k8s.gcr.io/etcd:3.4.3-0
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64:v1.18.1 k8s.gcr.io/kube-scheduler:v1.18.1
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64:v1.18.1 k8s.gcr.io/kube-controller-manager:v1.18.1
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64:v1.18.1 k8s.gcr.io/kube-apiserver:v1.18.1
- docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.18.1 k8s.gcr.io/kube-proxy:v1.18.1
此时通过Docker命令就可以查看到这些Docker镜像信息了,命令如下:
- root@kubernetesnode01:/opt/kubernetes-config# docker images
- REPOSITORY TAG IMAGE ID CREATED SIZE
- k8s.gcr.io/kube-proxy v1.18.1 4e68534e24f6 2 months ago 117MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64 v1.18.1 4e68534e24f6 2 months ago 117MB
- k8s.gcr.io/kube-controller-manager v1.18.1 d1ccdd18e6ed 2 months ago 162MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager-amd64 v1.18.1 d1ccdd18e6ed 2 months ago 162MB
- k8s.gcr.io/kube-apiserver v1.18.1 a595af0107f9 2 months ago 173MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver-amd64 v1.18.1 a595af0107f9 2 months ago 173MB
- k8s.gcr.io/kube-scheduler v1.18.1 6c9320041a7b 2 months ago 95.3MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler-amd64 v1.18.1 6c9320041a7b 2 months ago 95.3MB
- k8s.gcr.io/pause 3.2 80d28bedfe5d 4 months ago 683kB
- registry.cn-hangzhou.aliyuncs.com/google_containers/pause 3.2 80d28bedfe5d 4 months ago 683kB
- k8s.gcr.io/coredns 1.6.7 67da37a9a360 4 months ago 43.8MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/coredns 1.6.7 67da37a9a360 4 months ago 43.8MB
- k8s.gcr.io/etcd 3.4.3-0 303ce5db0e90 8 months ago 288MB
- registry.cn-hangzhou.aliyuncs.com/google_containers/etcd-amd64
解决镜像拉取问题后再次执行kubeadm部署命令就可以完成Kubernetes Master控制节点的部署了,具体命令及执行结果如下:
- root@kubernetesnode01:/opt/kubernetes-config# kubeadm init --config kubeadm.yaml --v=5
- ...
- Your Kubernetes control-plane has initialized successfully!
- To start using your cluster, you need to run the following as a regular user:
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
- You should now deploy a pod network to the cluster.
- Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
- https://kubernetes.io/docs/concepts/cluster-administration/addons/
- Then you can join any number of worker nodes by running the following on each as root:
- kubeadm join 10.211.55.6:6443 --token jfulwi.so2rj5lukgsej2o6 \
- --discovery-token-ca-cert-hash sha256:d895d512f0df6cb7f010204193a9b240e8a394606090608daee11b988fc7fea6
从上面部署执行结果中可以看到,部署成功后kubeadm会生成如下指令:
- kubeadm join 10.211.55.6:6443 --token d35pz0.f50zacvbdarqn2vi \
- --discovery-token-ca-cert-hash sha256:58958a3bf4ccf4a4c19b0d1e934e77bf5b5561988c2274364aaadc9b1747141d
这个kubeadm join命令就是用来给该Master节点添加更多Worker(工作节点)的命令,后面具体部署Worker节点的时候将会使用到它。此外,kubeadm还会提示我们第一次使用Kubernetes集群所需要配置的命令:
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
而需要这些配置命令的原因在于Kubernetes集群默认是需要加密方式访问的,所以这几条命令就是将刚才部署生成的Kubernetes集群的安全配置文件保存到当前用户的.kube目录,之后kubectl会默认使用该目录下的授权信息访问Kubernetes集群。如果不这么做的化,那么每次通过集群就都需要设置“export KUBE CONFIG 环境变量”来告诉kubectl这个安全文件的位置。
执行完上述命令后,现在我们就可以使用kubectlget命令来查看当前Kubernetes集群节点的状态了,执行效果如下:
- root@kubernetesnode01:/opt/kubernetes-config# kubectl get nodes
- NAME STATUS ROLES AGE VERSION
- kubernetesnode01 NotReady master 35m v1.18.4
在以上命令输出的结果中可以看到Master节点的状态为“NotReady”,为了查找具体原因可以通过“kuberctl describe”命令来查看下该节点(Node)对象的详细信息,命令如下:
- root@kubernetesnode01:/opt/kubernetes-config# kubectl describe node kubernetesnode01
该命令可以非常详细地获取节点对象的状态、事件等详情,这种方式也是调试Kubernetes集群时最重要的排查手段。根据显示的如下信息:
- ...
- Conditions
- ...
- Ready False... KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
- ...
可以看到节点处于“NodeNotReady”的原因在于尚未部署任何网络插件,为了进一步验证着一点还可以通过kubectl检查这个节点上各个Kubernetes系统Pod的状态,命令及执行效果如下:
- root@kubernetesnode01:/opt/kubernetes-config# kubectl get pods -n kube-system
- NAME READY STATUS RESTARTS AGE
- coredns-66bff467f8-l4wt6 0/1 Pending 0 64m
- coredns-66bff467f8-rcqx6 0/1 Pending 0 64m
- etcd-kubernetesnode01 1/1 Running 0 64m
- kube-apiserver-kubernetesnode01 1/1 Running 0 64m
- kube-controller-manager-kubernetesnode01 1/1 Running 0 64m
- kube-proxy-wjct7 1/1 Running 0 64m
- kube-scheduler-kubernetesnode01 1/1 Running 0 64m
命令中“kube-system”表示的是Kubernetes项目预留的系统Pod空间(Namespace),需要注意它并不是Linux Namespace,而是Kuebernetes划分的不同工作空间单位。回到命令输出结果,可以看到coredns等依赖于网络的Pod都处于Pending(调度失败)的状态,这样说明了该Master节点的网络尚未部署就绪。
5、部署Kubernetes网络插件
前面部署Master节点中由于没有部署网络插件,所以节点状态显示“NodeNotReady”状态。接下来的内容我们就来具体部署下网络插件。在Kubernetes“一切皆容器”的设计理念指导下,网络插件也会以独立Pod的方式运行在系统中,所以部署起来也很简单只需要执行“kubectl apply”指令即可,例如以Weave网络插件为例:
- root@kubernetesnode01:/opt/kubernetes-config# kubectl apply -f https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')
- serviceaccount/weave-net created
- clusterrole.rbac.authorization.k8s.io/weave-net created
- clusterrolebinding.rbac.authorization.k8s.io/weave-net created
- role.rbac.authorization.k8s.io/weave-net created
- rolebinding.rbac.authorization.k8s.io/weave-net created
- daemonset.apps/weave-net created
部署完成后通过“kubectl get”命令重新检查Pod的状态:
- root@kubernetesnode01:/opt/kubernetes-config# kubectl get pods -n kube-system
- NAME READY STATUS RESTARTS AGE
- coredns-66bff467f8-l4wt6 1/1 Running 0 116m
- coredns-66bff467f8-rcqx6 1/1 Running 0 116m
- etcd-kubernetesnode01 1/1 Running 0 116m
- kube-apiserver-kubernetesnode01 1/1 Running 0 116m
- kube-controller-manager-kubernetesnode01 1/1 Running 0 116m
- kube-proxy-wjct7 1/1 Running 0 116m
- kube-scheduler-kubernetesnode01 1/1 Running 0 116m
- weave-net-746qj
可以看到,此时所有的系统Pod都成功启动了,而刚才部署的Weave网络插件则在kube-system下面新建了一个名叫“weave-net-746qj”的Pod,而这个Pod就是容器网络插件在每个节点上的控制组件。
到这里,Kubernetes的Master节点就部署完成了,如果你只需要一个单节点的Kubernetes,那么现在就可以使用了。但是在默认情况下,Kubernetes的Master节点是不能运行用户Pod的,需要通过额外的操作进行调整,感兴趣的朋友可以自己查阅下其他资料。
6、部署Kubernetes的Worker节点
为了构建一个完整的Kubernetes集群,这里还需要继续介绍如何部署Worker节点。实际上Kubernetes的Worker节点和Master节点几乎是相同的,它们都运行着一个kubelet组件,主要的区别在于“kubeadm init”的过程中,kubelet启动后,Master节点还会自动启动kube-apiserver、kube-scheduler及kube-controller-manager这三个系统Pod。
在具体部署之前与Master节点一样,也需要在所有Worker节点上执行前面“安装kubeadm及Decker环境”小节中的所有步骤。之后在Worker节点执行部署Master节点时生成的“kubeadm join”指令即可,具体如下:
- root@kubenetesnode02:~# kubeadm join 10.211.55.6:6443 --token jfulwi.so2rj5lukgsej2o6 --discovery-token-ca-cert-hash sha256:d895d512f0df6cb7f010204193a9b240e8a394606090608daee11b988fc7fea6 --v=5
- ...
- This node has joined the cluster:
- * Certificate signing request was sent to apiserver and a response was received.
- * The Kubelet was informed of the new secure connection details.
- Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
完成集群加入后为了便于在Worker节点执行kubectl相关命令,需要进行如下配置:
- #创建配置目录
- root@kubenetesnode02:~# mkdir -p $HOME/.kube
- #将Master节点中$/HOME/.kube/目录中的config文件拷贝至Worker节点对应目录
- root@kubenetesnode02:~# scp root@10.211.55.6:$HOME/.kube/config $HOME/.kube/
- #权限配置
- root@kubenetesnode02:~# sudo chown $(id -u):$(id -g) $HOME/.kube/config
之后可以在Worker或Master节点执行节点状态查看命令“kubectl get nodes”,具体如下:
- root@kubernetesnode02:~# kubectl get nodes
- NAME STATUS ROLES AGE VERSION
- kubenetesnode02 NotReady <none> 33m v1.18.4
- kubernetesnode01 Ready master 29h v1.18.4
通过节点状态显示此时Work节点还处于NotReady状态,具体查看节点描述信息如下:
- root@kubernetesnode02:~# kubectl describe node kubenetesnode02
- ...
- Conditions:
- ...
- Ready False ... KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
- ...
根据描述信息,发现Worker节点NotReady的原因也在于网络插件没有部署,继续执行“部署Kubernetes网络插件”小节中的步骤即可。但是要注意部署网络插件时会同时部署kube-proxy,其中会涉及从k8s.gcr.io仓库获取镜像的动作,如果无法访问外网可能会导致网络部署异常,这里可以参考前面安装Master节点时的做法,通过国内镜像仓库下载后通过tag的方式进行标记,具体如下:
- root@kubenetesnode02:~# docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.18.1
- root@kubenetesnode02:~# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy-amd64:v1.18.1 k8s.gcr.io/kube-proxy:v1.18.1
如若一切正常,则继续查看节点状态,命令如下:
- root@kubenetesnode02:~# kubectl get node
- NAME STATUS ROLES AGE VERSION
- kubenetesnode02 Ready <none> 7h52m v1.18.4
- kubernetesnode01 Ready master 37h v1.18.4
可以看到此时Worker节点的状态已经变成“Ready”,不过细心的读者可能会发现Worker节点的ROLES并不像Master节点那样显示“master”而是显示了
- root@kubenetesnode02:~# kubectl label node kubenetesnode02 node-role.kubernetes.io/worker=worker
再次运行节点状态命令就能看到正常的显示了,命令效果如下:
- root@kubenetesnode02:~# kubectl get node
- NAME STATUS ROLES AGE VERSION
- kubenetesnode02 Ready worker 8h v1.18.4
- kubernetesnode01 Ready master 37h v1.18.4
到这里就部署完成了具有一个Master节点和一个Worker节点的Kubernetes集群了,作为实验环境它已经具备了基本的Kubernetes集群功能!
7、部署Dashboard可视化插件
在Kubernetes社区中,有一个很受欢迎的Dashboard项目,它可以给用户一个可视化的Web界面来查看当前集群中的各种信息。该插件也是以容器化方式进行部署,操作也非常简单,具体可在Master、Worker节点或其他能够安全访问Kubernetes集群的Node上进行部署,命令如下:
- root@kubenetesnode02:~# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.3/aio/deploy/recommended.yaml
部署完成后就可以查看Dashboard对应的Pod运行状态,执行效果如下:
- root@kubenetesnode02:~# kubectl get pods -n kubernetes-dashboard
- NAME READY STATUS RESTARTS AGE
- dashboard-metrics-scraper-6b4884c9d5-xfb8b 1/1 Running 0 12h
- kubernetes-dashboard-7f99b75bf4-9lxk8 1/1 Running 0 12h
除此之外还可以查看Dashboard的服务(Service)信息,命令如下:
- root@kubenetesnode02:~# kubectl get svc -n kubernetes-dashboard
- NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
- dashboard-metrics-scraper ClusterIP 10.97.69.158 <none> 8000/TCP 13h
- kubernetes-dashboard ClusterIP 10.111.30.214 <none> 443/TCP 13h
需要注意的是,由于Dashboard是一个Web服务,从安全角度出发Dashboard默认只能通过Proxy的方式在本地访问。具体方式为在本地机器安装kubectl管理工具,并将Master节点$HOME/.kube/目录中的config文件拷贝至本地主机相同目录,之后运行“kubectl proxy”命令,如下:
- qiaodeMacBook-Pro-2:.kube qiaojiang$ kubectl proxy
- Starting to serve on 127.0.0.1:8001
本地proxy代理启动后,访问Kubernetes Dashboard地址,具体如下:
- http://localhost:8001/api/v1/namespaces/kubernetes-dashboard/services/https:kubernetes-dashboard:/proxy/
如果访问正常,就会看到相应的界面!以上就是Kubernetes基本集群的搭建方式,希望能对你学习Kubernetes容器编排技术有所帮助!