












阿里妹导读:对于大型的软件系统如互联网分布式应用或企业级软件,为何我们常常会陷入复杂度陷阱?如何识别复杂度增长的因素?在代码开发以及演进的过程中需要遵循哪些原则?本文将分享阿里研究员谷朴关于软件复杂度的思考:什么是复杂度、复杂度是如何产生的以及解决的思路。较长,同学们可收藏后再看。
文末福利:免费下载《2020年微服务领域开源数字化报告》。
写在前面
软件设计和实现的本质是工程师相互通过“写作”来交流一些包含丰富细节的抽象概念并且不断迭代过程。
另外,如果你的代码生存期一般不超过6个月,本文用处不大。
一 软件架构的核心挑战是快速增长的复杂性
越是大型系统,越需要简单性。
大型系统的本质问题是复杂性问题。互联网软件,是典型的大型系统,如下图所示,数百个甚至更多的微服务相互调用/依赖,组成一个组件数量大、行为复杂、时刻在变动(发布、配置变更)当中的动态的、复杂的系统。而且,软件工程师们常常自嘲,“when things work, nobody knows why”。

图源:https://divante.com/blog/10-companies-that-implemented-the-microservice-architecture-and-paved-the-way-for-others/
如果我们只是写一段独立代码,不和其他系统交互,往往设计上要求不会很高,代码是否易于使用、易于理解、易于测试和维护,根本不是问题。而一旦遇到大型的软件系统如互联网分布式应用或者企业级软件,我们常常陷入复杂度陷阱,下图the life of a software engineer是我很喜欢的一个软件cartoon,非常形象的展示了复杂度陷阱。

图源:http://themetapicture.com/the-life-of-a-software-engineer/
做为一个有追求的软件工程师,大家肯定都思考过,我手上的项目,如何避免这种似乎难以避免的复杂度困境?
然而对于这个问题给出答案,却出乎意料的困难:很多的文章都给出了软件架构的设计建议,然后正如软件领域的经典论著《No silver bullet》所说,这个问题没有神奇的解决方案。并不是说那么多的架构文章都没用(其实这么方法多半都有用),只不过,人们很难真正去follow这些建议并贯彻下去。为什么?我们还是需要彻底理解这些架构背后的思考和逻辑。所以我觉得有必要从头开始整理这个逻辑:什么是复杂度,复杂度是如何产生的,以及解决的思路。
二 软件的复杂度为什么会快速增长?
要理解软件复杂度会快速增长的本质原因,需要理解软件是怎么来的。我们首先要回答一个问题,一个大型的软件是建造出来的,还是生长出来的?BUILT vs GROWN,that is the problem.
1 软件是长出来的,不是建造出来的
软件不是建造出来的,甚至不是设计出来的。软件是长出来的。
这个说法初看上去和我们平时的认识似乎不同,我们常常谈软件架构,架构这个词似乎蕴含了一种建造和设计的意味。然而,对于软件系统来说,我们必须认识到,架构师设计的不是软件的架构,而是软件的基因,而这些基因如何影响软件未来的形态则是难以预测,无法完全控制。
为什么这么说?所谓建造和“生长”差异在哪里?其实,我们看今天一个复杂的软件系统,确实很像一个复杂的建筑物。但是把软件比作一栋摩天大楼却不是一个好的比喻。原因在于,一个摩天大楼无论多么复杂,都是事先可以根据设计出完整详尽的图纸,按图准确施工,保证质量就能建造出来的。然而现实中的大型软件系统,却不是这么建造出来的。

例如淘宝由一个单体PHP应用,经过4、5代架构不断演进,才到今天服务十亿人规模的电商交易平台。支付宝,Google搜索,Netflix微服务,都是类似的历程。
是不是一定要经过几代演进才能构建出来大型软件,就不能一次到位吗?如果一个团队离开淘宝,要拉开架势根据淘宝交易的架构重新复制一套,在现实中是不可能实现的:没有哪个创业团队能有那么多资源同时投入这么多组件的开发,也不可能有一开始就朝着超级复杂架构开发而能够成功的实现。
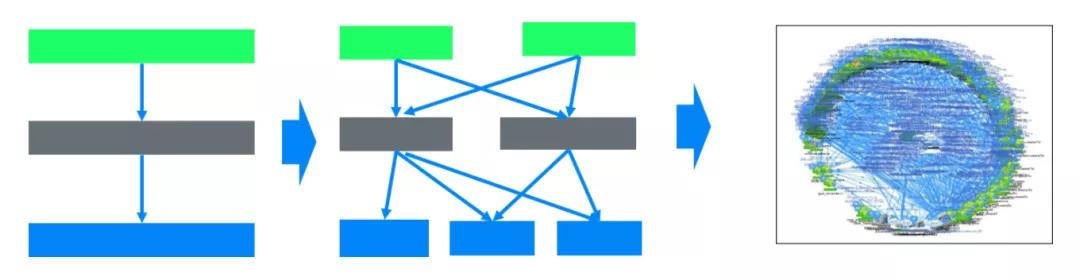
也就是说,软件的动态“生长”,更像是上图所画的那样,是从一个简单的“结构”生长到复杂的“结构”的过程。伴随着项目本身的发展、研发团队的壮大,系统是个逐渐生长的过程。
2 大型软件的核心挑战是软件“生长”过程中的理解和维护成本
复杂软件系统最核心的特征是有成百上千的工程师开发和维护的系统(软件的本质是工程师之间用编程语言来沟通抽象和复杂的概念,注意软件的本质不是人和机器沟通)。如果认同这个定义,设想一下复杂软件是如何产生的:无论最终多么复杂的软件,都要从第一行开始开发。都要从几个核心开始开发,这时架构只能是一个简单的、少量程序员可以维护的系统组成架构。随着项目的成功,再去逐渐细化功能,增加可扩展性,分布式微服务化,增加功能,业务需求也在这个过程中不断产生,系统满足这些业务需求,带来业务的增长。业务增长对于软件系统迭代带来了更多的需求,架构随着适应而演进,投入开发的人员随着业务的成功增加,这样不断迭代,才会演进出几十,几百,甚至几千人同时维护的复杂系统来。
大型软件设计核心要素是控制复杂度。这一点非常有挑战,根本原因在于软件不是机械活动的组合,不能在事先通过精心的“架构设计”规避复杂度失控的风险:相同的架构图/蓝图,可以长出完完全全不同的软件来。大型软件设计和实现的本质是大量的工程师相互通过“写作”来交流一些包含丰富细节的抽象概念并且相互不断迭代的过程[2]。稍有差错,系统复杂度就会失控。
所以说了这么多是要停留在形而上吗?并不是。我们的结论是,软件架构师最重要的工作不是设计软件的结构,而是通过API,团队设计准则和对细节的关注,控制软件复杂度的增长。
- 架构师的职责不是试图画出复杂软件的大图。大图好画,靠谱的系统难做。复杂的系统是从一个个简单应用 一点点长出来的。
- 当我们发现自己的系统问题多多,别怪“当初”设计的人,坑不是一天挖出来的。每一个设计决定都在贡献复杂度。
三 理解软件复杂度的维度
1 软件复杂度的两个表现维度:认知负荷与协同成本
我们分析理解了软件复杂度快速增长的原因,下面我们自然希望能解决复杂度快速增长这一看似永恒的难题。但是在此之前,我们还是需要先分析清楚一件事情,复杂度本身是什么?又如何衡量?
代码复杂度是用行数来衡量么?是用类的个数/文件的个数么?深入思考就会意识到,这些表面上的指标并非软件复杂度的核心度量。正如前面所分析的,软件复杂度从根本上说可以说是一个主观指标(先别跳,耐心读下去),说其主观是因为软件复杂度只有在程序员需要更新、维护、排查问题的时候才有意义。一个不需要演进和维护的系统其架构、代码如何关系也就不大了(虽然现实中这种情况很少)。
既然 “软件设计和实现的本质是工程师相互通过写作来交流一些包含丰富细节的抽象概念并且不断迭代过程” (第三次强调了),那么,复杂度指的是软件中那些让人理解和修改维护的困难程度。相应的,简单性,就是让理解和维护代码更容易的要素。
“The goal of software architecture is to minimize the manpower required to build and maintain the required system.” Robert Martin, Clean Architecture [3].
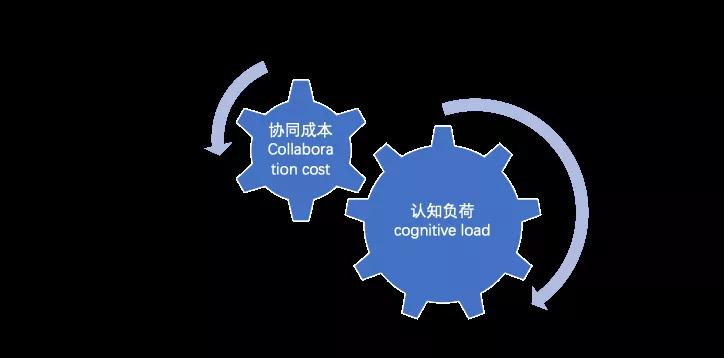
因此我们将软件的复杂度分解为两个维度,都和人理解与维护软件的成本相关:
- 第一,认知负荷 cognitive load :理解软件的接口、设计或者实现所需要的心智负担。
- 第二,协同成本Collaboration cost:团队维护软件时需要在协同上额外付出的成本。
我们看到,这两个维度有所区别,但是又相互关联。协同成本高,让软件系统演进速度变慢,效率变差,工作其中的工程师压力增大,而长期难以取得进展,工程师倾向于离开项目,最终造成质量进一步下滑的恶性循环。而认知负荷高的软件模块让程序员难以理解,从而产生两个后果:(1) 维护过程中易于出错,bug 率故障率高;(2) 更大机率 团队人员变化时被抛弃,新成员选择另起炉灶,原有投入被浪费,甚至更高糟糕的是,代码被抛弃但是又无法下线,成为定时炸弹。
2 影响到认知负荷的因素
认知负荷又可以分解为:
- 定义新的概念带来认知负荷,而这种认知负荷与 概念和物理世界的关联程度相关。
- 逻辑符合思维习惯程度:正反逻辑差异,逻辑嵌套和独立原子化组合。继承和组装差异。
(1)不恰当的逻辑带来的认知成本
看以下案例[7]:
A. Code with too much nesting
response = server.Call(request)
if response.GetStatus() == RPC.OK:
if response.GetAuthorizedUser():
if response.GetEnc() == 'utf-8':
if response.GetRows():
vals = [ParseRow(r) for r in
response.GetRows()]
avg = sum(vals) / len(vals)
return avg, vals
else:
raise EmptyError()
else:
raise AuthError('unauthorized')
else:
raise ValueError('wrong encoding')
else:
raise RpcError(response.GetStatus())
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
B. Code with less nesting
response = server.Call(request)
if response.GetStatus() != RPC.OK:
raise RpcError(response.GetStatus())
if not response.GetAuthorizedUser():
raise ValueError('wrong encoding')
if response.GetEnc() != 'utf-8':
raise AuthError('unauthorized')
if not response.GetRows():
raise EmptyError()
vals = [ParseRow(r) for r in
response.GetRows()]
avg = sum(vals) / len(vals)
return avg, vals
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
比较A和B,逻辑是完全等价的,但是B的逻辑明显更容易理解,自然也更容易在B的代码基础上增加功能,且新增的功能很可能也会维持这样一个比较好的状态。
而我们看到A的代码,很难理解其逻辑,在维护的过程中,会有更大的概率引入bug,代码的质量也会持续恶化。
(2)模型失配:和现实世界不完全符合的模型带来高认知负荷
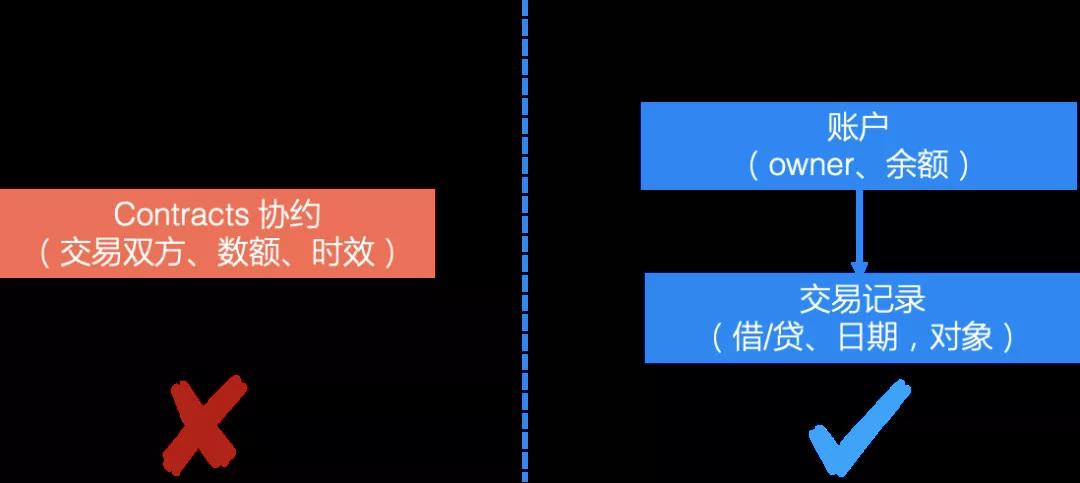
软件的模型设计需要符合现实物理世界的认知,否则会带来非常高的认知成本。我遇到过这样一个资源管理系统的设计,设计者从数学角度有一个非常优雅的模型,将资源账号 用合约来表达(下图左侧),账户的balance可以由过往合约的累计获得,确保数据一致性。但是这样的设计,完全不符合用户的认知,对于用户来说,感受到的应该是账号和交易的概念,而不是带着复杂参数的合约。可以想象这样的设计,其维护成本非常之高。
(3)接口设计不当
以下是一个典型的接口设计不当带来的理解成本。
class BufferBadDesign {
explicit Buffer(int size);// Create a buffer with given sized slots
void AddSlots(int num);// Expand the slots by `num`
// Add a value to the end of stack, and the caller need to
// ensure that there is at least one empty slot in the stack before
// calling insert
void Insert(int value);
int getNumberOfEmptySlots(); // return the number of empty slots
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
希望我们的团队不会设计出这样的模块。这个问题可以明显看到一个接口设计的不合理带来的维护成本提升:一个Buffer的设计暴露了内部内存管理的细节(slot维护),从而导致在调用最常用接口 “insert”时存在陷阱:如果不在insert前检查空余slot,这个接口就会有异常行为。
但是从设计角度看,维护底层的Slot的逻辑,也外部可见的buffer的行为其实并没有关联,而只是一个底层的实现细节。因此更好的设计应该可以简化接口。把Slot数量的维护改为内部的实现逻辑细节,不对外暴露。这样也完全消除了因为使用不当带来问题的场景。同时也让接口更易于理解,降低了认知成本。
class Buffer { explicit Buffer(int size); // Create a buffer with given sized slots // Add a value to the end of buffer. New slots are added // if necessary. void Insert(int value);}
事实上,当我们发现一个模块在使用时具备如下特点时,一般就是难以理解、容易出错的信号:
- 一个模块需要调用者使用初始化接口才能正常行为:对于调用者来说,需要调用初始化接口看似不是大的问题,但是这样的模块,带来了多种后患,尤其是当存在多个参数需要设置,相互关联关系复杂时。配置问题应该单独解决(比如通过工厂模式,或者通过单独的配置系统来管理)。
- 一个模块需要调用者使用后做清理/ finalizer才能正常退出。
- 一个模块有多种方式让调用者实现完全相同的功能:软件在维护过程中,出现这种状况可能是因为初始设计不当后来修改设计 带来的冗余,也可能是设计原版的缺陷,无论如何这种模块,带着强烈的“坏味道”。
完全避免这些问题很难,但是我们需要在设计中尽最大努力。有时通过文档的解释来弥补这些问题是必要的,但是好的工程师/架构师,应该清醒的意识到,这些都是“坏味道”。
(4)一个简单的修改需要在多处更新
简单修改涉及多处更改也是常见的软件维护复杂度因素,而且主要影响的是我们的认知负荷:维护修改代码时需要花费大量的精力确保各处需要修改的地方都被照顾到了。
最简单的情形是代码当中有重复的“常数”,为了修改这个常数,我们需要多处修改代码。程序员也知道如何解决这一问题,例如通过定义个constant 并处处引用避免magic number。再例如网页的风格/色彩,每个页面相同配置都重复设置同样的色彩和风格是一种模式,而采用css模版则是更加易于维护的架构。这在架构原则中对应了数据归一化原则(Data normalization)。
稍微复杂一些的是类似的逻辑/或者功能被copy-paste多次,原因往往是不同的地方需要稍微不同的使用方式,而过去的维护者没有及时refactor代码提取公共逻辑(这样做往往需要更多的时间精力),而是省时间情况下选择了copy-paste。这就是常说的 Don't repeat yourself原则:
Every piece of knowledge must have a single, unambiguous, authoritative representation within a system[8]
(5)命名
软件中的API、方法、变量的命名,对于理解代码的逻辑、范围非常重要,也是设计者清晰传达意图的关键。然而,在很多的项目里我们没有给Naming /命名足够的重视。
我们的代码一般会和一些项目关联,但是需要注意的是项目是抽象的,而代码是具体的。项目或者产品可以随意一些命名,如阿里云喜欢用中国古代神话(飞天、伏羲、女娲)命名系统,K8s也是来自于希腊神话,这些都没有问题。而代码中的API、变量、方法不能这样命名。
一个不好的例子是前一段我们的Cluster API 被命名为Trident API(三叉戟),设想一下代码中的对象叫Trident时,我们如何理解在这个对象应该具备的行为?再对比一下K8s中的资源:Pod, ReplicaSet, Service, ClusterIP,我们会注意到都是清晰、简单、直接符合其对象特征的命名。名实相符可以很大程度上降低理解该对象的成本。
有人说“Naming is the most difficult part of software engineering[9][10]”,或许也不完全是个玩笑话:Naming的难度在于对于模型的深入思考和抽象,而这往往确实是很难的。
需要注意的是:
(a)Intention vs what it is
需要避免用“是什么”来命名,要用“for what / intention”。“是什么”来命名是会很容易将实现细节。比如我们用 LeakedBarrel做rate limiting,这个类最好叫 RateLimiter,而不是LeakedBarrel:前者定义了意图(做什么的),后者 描述了具体实现,而具体实现可能会变化。再比如 Cache vs FixedSizeHashMap,前者也是更好的命名。
(b)命名需要符合当前抽象的层级
首先我们软件需要始终有清晰的抽象和分层。事实上我们Naming时遇到困难,很多就是因为软件已经缺乏明确的抽象和分层带来的表象而已。
(6)不知道一个简单特性需要在哪些做修改,或者一个简单的改动会带来什么影响,即unknown unknowns
在所有认知复杂度的表现中,这是最坏的一种,不幸的是,所有人都曾经遇到过这样的情况。
一个典型的unknown unknown是一部分代码存在这样的情况:
- 代码缺乏充分的测试覆盖,一些重要场景依赖维护者手工测试。
- 代码有隐藏/不易被发现的行为或者边界条件,与文档和接口描述并不符合。
对于维护者来说,改动这样的代码(或者是改动影响到了这样代码 / 被这样代码影响到了)时,如果按照接口描述或者文档进行,没发现隐藏行为,同时代码又缺乏足够测试覆盖,那么就存在未知的风险unknown unknowns。这时出现问题是很难避免的。最好的方式还是要尽量避免我们的系统质量劣化到这个程度。
上线时,我们最大的噩梦就是unknown unknowns:这类风险,我们无法预知在哪里或者是否有问题,只能在软件上线后遇到问题才有可能发现。其他的问题 尚可通过努力来解决(认知成本),而unknown unknowns可以说已经超出了认知成本的范围。我们最希望避免的也是unknown unknowns。
(7)认知成本低要不易出错,而不是无脑“简化”
从认知成本角度来说,我们还要认识到,衡量不同方案/写法的认知成本,要考虑的是不易出错,而不是表面上的简化:表面上简化可能带来实质性的复杂度上升。
例如,为了表达时间段,可以有两种选择:
// Time period in seconds.
void someFunction(int timePeriod);
// time period using Duration.
void someFunction(Duration timePeriod);
- 1.
- 2.
- 3.
- 4.
在上面这个例子里面,我们都知道,应该选用第二个方案,即采用Duration作time period,而不是int:尽管Duration本身需要一点点学习成本,但是这个模式可以避免多个时间单位带来的常见问题。
3 影响协同成本的因素
协同成本则是增长这块模块所需要付出的协同成本。什么样的成本是协同成本?(1)增加一个新的特性往往需要多个工程师协同配合,甚至多个团队协同配合;(2) 测试以及上线需要协调同步。
(1)系统模块拆分与团队边界
在微服务化时代,模块/服务的切分和团队对齐,更加有利于迭代效率。而模块拆分和边界的不对齐,则让代码维护的复杂度增加,因这时新的特性需要在跨多个团队的情况下进行开发、测试和迭代。
另外一个角度,则是:
Any piece of software reflects the organizational structure that produces it.
或者就是我们常说的“组织架构决定系统架构”,软件的架构最后会围绕组织的边界而变化(当然也有文化因素),当组织分工不合理时,会产生重复的建设或者冲突。
(2)服务之间的依赖,Composition vs Inheritance/Plugin
软件之间的依赖模式,常见的有Composition 和Inheritance模式,对于local模块/类之间的依赖还是远程调用,都存在类似模式。
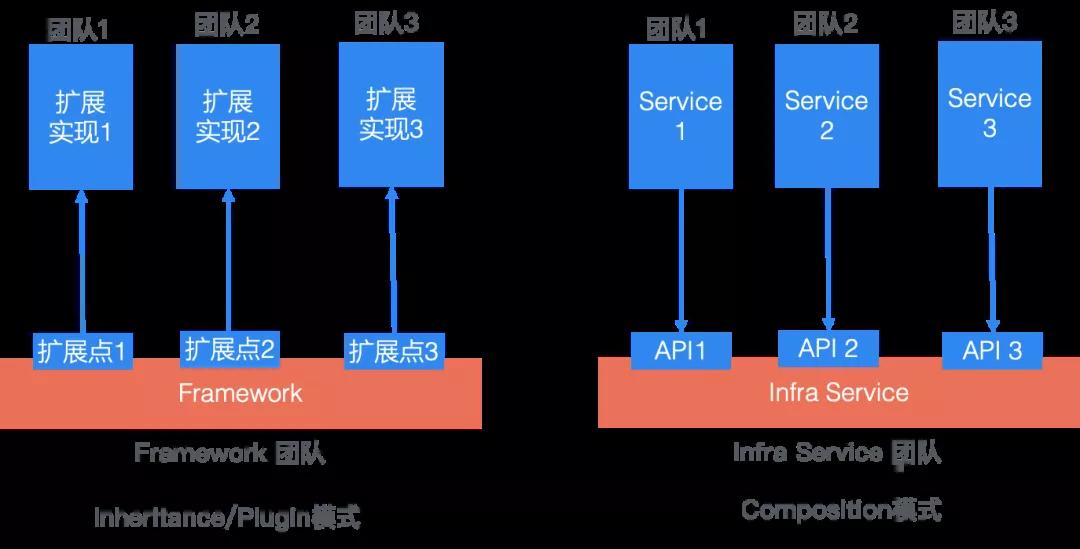
上图左侧是Inheritance(继承或者是扩展模式),有四个团队,其中一个是Framework团队负责框架实现,框架具有三个扩展点,这三个扩展点有三个不同的团队实现插件扩展,这些插件被Framework调用,从架构上,这是一种类似于继承的模式。
右侧是组合模式(composition):底层的系统以API服务的方式提供接口,而上层应用或者服务通过调用这些接口来实现业务功能。
这两种模式适用于不同的系统模型。当Framework偏向于底层、不涉及业务逻辑且相对非常稳定时,可以采用inheritance模式,也即Framework被集成到团队1,2,3的业务实现当中。例如RPC framework就是这样的模型:RPC底层实现作为公共的base 代码/SDK提供给业务使用,业务实现自己的RPC 方法,被framework调用,业务无需关注底层RPC实现的细节。因为Framework代码被业务所依赖,因此这时业务希望Framework的代码非常稳定,而且尽量避免对framework层的感知,这时inheritance是一种比较合适的模型。
然而,我们要慎用Inheritance模式。Inheritance模式的常见陷阱:
(a)要避免出现管理倒置
即Framework层负责整个系统的运维(framework团队负责代码打包、构建、上线),那么会出现额外的协同复杂度,影响系统演进效率(设想一下如果Dubbo的团队要求负责所有的使用Dubbo的应用的打包、发布成为一个大的应用,会是多么的低效)。
(b)要避免破坏业务逻辑流程的封闭性
Inheritance模式如果使用不当,很容易破坏上层业务的逻辑抽象完整性,也即“扩展实现1”这个模块的逻辑,依赖于其调用者的内部逻辑流程甚至是内部实现细节,这会带来危险的耦合,破坏业务的逻辑封闭性。
如果你所在的项目采用了插件/Inheritance模式,同时又出现上面所说的管理倒置、破坏封闭性情况,就需要反思当前的架构的合理性。
而右侧的Composition是更常用的模型:服务与服务之间通过API交互,相互解耦,业务逻辑的完整性不被破坏,同时框架/Infra的encapsulation也能保证。同时也更灵活,在这种模型下,Service 1, 2, 3 如果需要也可以产生相互调用。
另外《Effective Java》一书的Favor composition over inheritance有很好的分析,可以作为这个问题的补充。
(3)可测试性不足带来的协同成本
交付给其他团队(包括测试团队)的代码应该包含充分的单元测试,具备良好的封装和接口描述,易于被集成测试的。然而因为 单测不足/模块测试不足,带来的集成阶段的复杂度升高、失败率和返工率的升高,都极大的增加了协同的成本。因此做好代码的充分单元测试,并提供良好的集成测试支持,是降低协同成本提升迭代效率的关键。
可测试性不足,带来协同成本升高,往往导致的破窗效应:上线越来越靠运气,unknown unknowns越来越多。
(4)文档
降低协同成本需要对接口/API提供清晰的、不断保持更新一致的文档,针对接口的场景、使用方式等给出清晰描述。这些工作需要投入,开发团队有时不愿意投入,但是对于每一个用户/使用方,需要依赖钉钉上的询问、或者是依靠ATA文章(多半有PR性质或者是已经过时,没有及时更新,毕竟ATA不是产品文档),协同成本太高,对于系统来说出现bug/使用不当的几率大为增加了。
最好的方式:(1)代码都公开;(2)文档和代码写在一起(README.md, *.md),随着代码一起提交和更新,还计算代码行数,多好。
4 软件复杂度生命周期
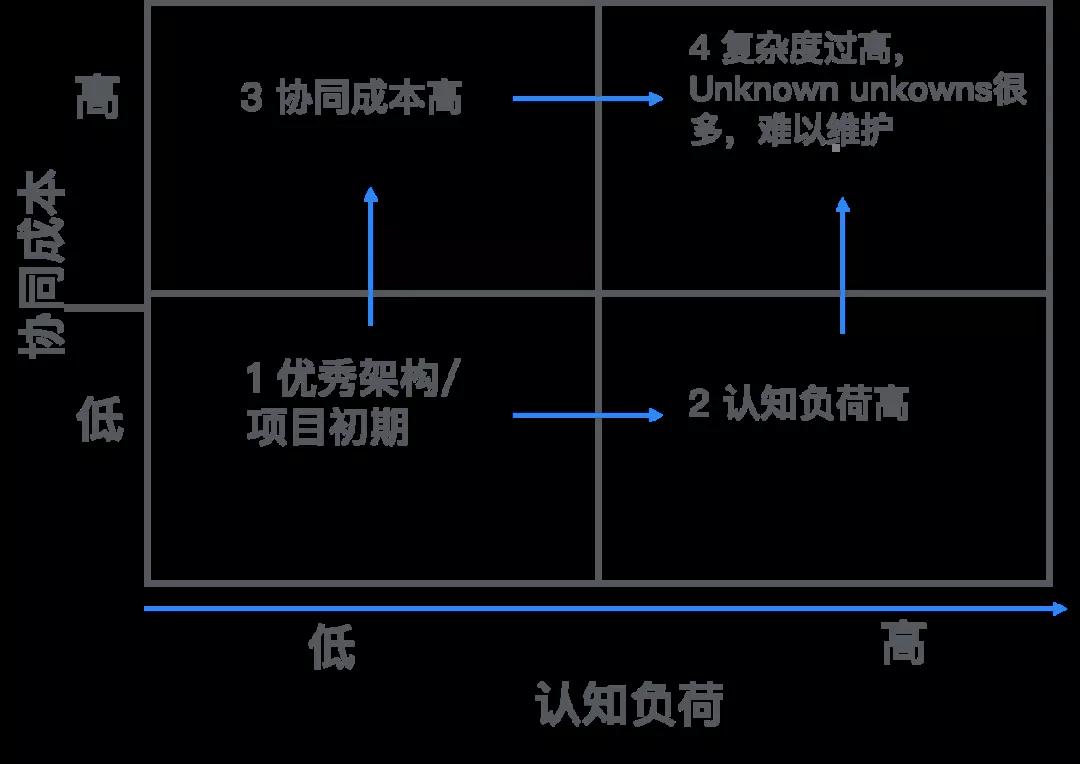
复杂度的恶化到一定程度,一定进入有诸多unknown unknown的程度。好的工程师一定要能识别这样的状态:可以说,如果不投入力气去做一定的重构/改造,有过多unknown unknowns的系统,很难避免失败的厄运了。
这张图是要表明,软件演进的过程,是一个“不由自主”就会滑向过于复杂而无法维护的深渊的过程。如何要避免失败的厄运?这篇文章的篇幅不容许我们展开讨论如何避免复杂度,但是首要的,对于真正重要的、长生命周期的软件演进,我们需要做到对于复杂度增量零容忍。
5 Good enough vs Perfect
软件领域,从效率和质量的折中,我们会提“Good enough”即可。这个理论是没错的。只不过现实中,我们极少看到“overly good”,因为过于追求perfection而影响效率的情况。大多数情况下,我们的系统是根本没做到Good enough。
四 对复杂度增长的对策
每一份新的代码的引入,都在增加系统的复杂度:因为每一个类或者方法的创建,都会有其他代码来引用或者调用这部分代码,因而产生依赖/耦合,增加系统的复杂度(除非之前的代码过度复杂unncessarily complex,而通过重构可以降低复杂度),如果读者都意识到了这个问题,并且那些识别增加复杂度的关键因素对于大家有所帮助,那么本文也就达到了目标。
而如何Keep it simple,是个非常大的话题,本文不会展开。对于API设计,在[5]中做了一些总结,其他的希望后续有时间能继续总结。
有人会说,项目交付的压力才是最重要的,不要站着说话不腰疼。实际呢?我认为绝对不是这样。多数情况下,我们要对复杂度增长采用接近于“零容忍”的态度,避免“能用就行”,原因在于:
- 复杂度增长带来的风险(unknown unknowns、不可控的失败等)往往是后知后觉的,等到问题出现时,往往legacy已经形成一段时间,或者坑往往是很久以前埋的。
- 当我们在代码评审、设计评审时面临一个个选择时,每一个Hack、每一个带来额外成本和复杂度的设计似乎都显得没那么有危害:就是增加了一点点复杂度而已,就是一点点风险而已。但是每一个失败的系统的问题都是这样一点点积累起来的。
- 破窗效应Broken window:一个建筑,当有了一个破窗而不及时修补,这个建筑就会被侵入住认为是无人居住的、风雨更容易进来,更多的窗户被人有意打破,很快整个建筑会加速破败。这就是破窗效应,在软件的质量控制上这个效应非常恰当。所以,Don't live with broken windows (bad designs, wrong decisions, poor code) [6]:有破窗尽快修。
零容忍,并不是不让复杂度增长:我们都知道这是不可能的。我们需要的是尽力控制。因为进度而临时打破窗户也能接受,但是要尽快补上。
当然文章一开始就强调了,如果所写的业务代码生命周期只有几个月,那么多半在代码变得不可维护之前就可以下线了,那可以不用关注太多,能用就行。
最后,作为Software engineer,软件是我们的作品,希望大家都相信:
- 真正的工程师一定在意自己的作品:我们的作品就是我们的代码。工匠精神是对每个工程师的要求。
- 我们都可以带来改变:代码是最公平的工作场地,代码就在那里,只要我们愿意,就能带来变化。
Reference
[1]John Ousterhout, A Philosophy of software design
[2]Frederick Brooks, No Silver Bullet - essence and accident in software engineering
[3]Robert Martin, Clean Architecture
[4]https://medium.com/monsterculture/getting-your-software-architecture-right-89287a980f1b
[5]API设计最佳实践思考 https://developer.aliyun.com/article/701810
[6]Andrew Hunt and David Thomas, The pragmatic programmer: from Journeyman to master
[7]https://testing.googleblog.com/2017/06/code-health-reduce-nesting-reduce.html
[8]https://en.wikipedia.org/wiki/Don%27t_repeat_yourself
[9]http://www.multunus.com/blog/2017/01/naming-the-hardest-software/
[10]https://martinfowler.com/bliki/TwoHardThings.html
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】






















