本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
自打有了deepfake,再也不敢相信「眼见为实」了。
要说把朱茵换脸成杨幂,把海王换脸成徐锦江,大家还可以一笑而过。
△图源:微博用户@慢三与偏见
可若是公众人物被deepfake了什么不该说的话、不该做的事,就让人细思极恐了。

为了防止世界被破坏,为了维护世界的和平,(狗头)现在,阿里安全图灵实验室也加入了“围剿”deepfake的队列:
打造deepfake检测算法S-MIL,多人现场视频,只要其中1人被换脸,就能精准识别。
基于多实例学习的deepfake检测方法
魔高一尺,道高一丈。deepfake和deepfake检测技术的较量其实早已展开。
不过,此前存在的deepfake检测方法主要分为两类:帧级检测和视频级检测。
基于帧级的方法需要高成本的帧级别标注,在转化到视频级任务时,也需要设计巧妙的融合方法才能较好地将帧级预测转化为视频级预测。简单的平均值或者取最大值极易导致漏检或误检。
而基于视频级别的检测方法,比如LSTM等,在deepfake视频检测时,过多专注于时序建模,导致deepfake视频的检测效果受到了一定的限制。

△部分deepfake攻击,四个人中只有一人被换脸
为了解决这些问题,阿里安全图灵实验室的研究人员们提出了基于多实例学习的Sharp-MIL(S-MIL)方法,只需视频级别的标注,就能对deepfake作品进行检测。
核心思想是,只要视频中有一张人脸被篡改,那么该视频就被定义为deepfake视频。这就和多实例学习的思想相吻合。
在多实例学习中,一个包由多个实例组成,只要其中有一个实例是正类,那么该包就是正类的,否则就是负类。
S-MIL就将人脸和输入视频分别当作多实例学习里的实例和包进行检测。
并且,通过将多个实例的聚合由输出层提前到特征层,一方面使得聚合更加灵活,另一方面也利用了伪造检测的目标函数直接指导实例级深度表征的学习,来缓解传统多实例学习面临的梯度消失难题。
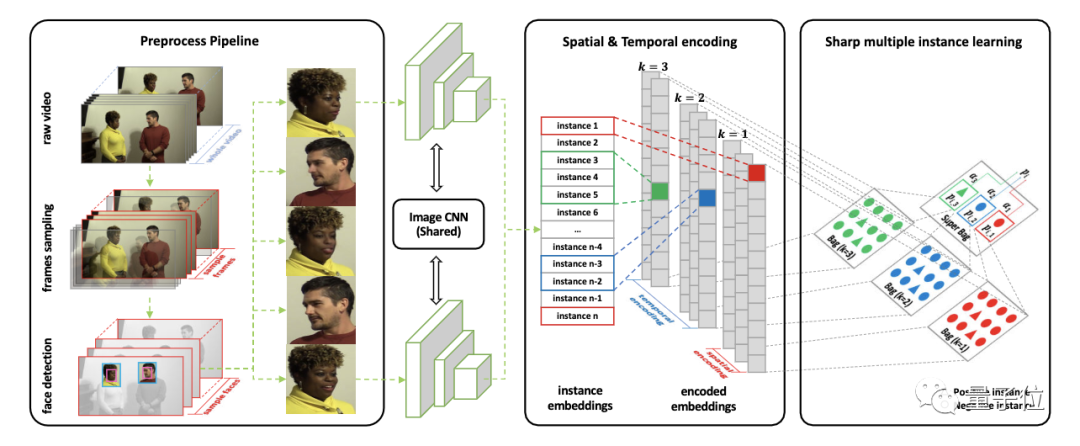
具体而言,算法主要由三个关键部分组成。
首先,对输入视频中的采样帧进行人脸检测,并将提取的人脸喂给CNN,以获取特征作为实例。
在实例设计上,与传统多实例学习的设定一样,实例与实例间是相互独立的。
但由于deepfake是单帧篡改的,导致同一人脸在相邻帧上会有一些抖动,就像这样:

为此,研究人员设计了时空实例,用来刻画帧间一致性,用于辅助deepfake检测。
具体而言,使用文本分类里常用的1-d卷积,使用不同大小的核对输入的人脸序列从多视角上进行编码,以得到时空实例,用于最终检测。
也就是说,第二步,是将编码后的时空实例提取出来,形成时间核大小不同的时空包。这些包被一起用来表示一段视频。
最后,对这些包进行S-MIL,算出所有包的fake分数,这样,就能得到整个视频的最终fake分数,从而判断视频到底是不是deepfake。
S-MIL定义如下:
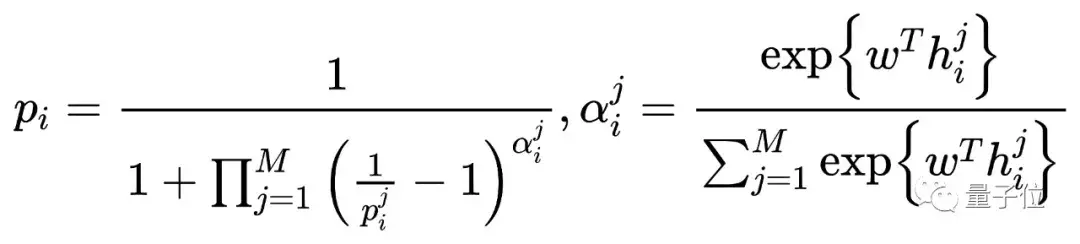
其中,pi和p(i)^(j)分别是第i个包及其包里的第j个实例的正类概率;M为包里的实例数;w是网络参数;h(i)^(j)是包i里的实例j对应的特征。

由于现有的带帧标签的数据集中,同一视频中真假人脸混杂的样本较少,研究人员还构建了一个部分攻击数据集FFPMS。
FFPMS共包含14000帧,包括4种类型的造假视频(DF、F2F、FS、NT)和原始视频,既有帧级标签,也包含视频级标签。
检测效果达到SOTA
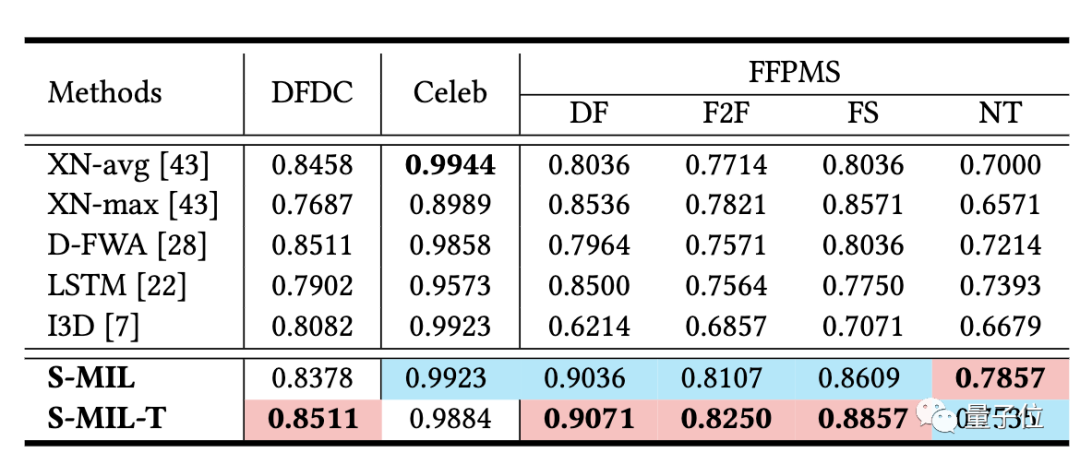
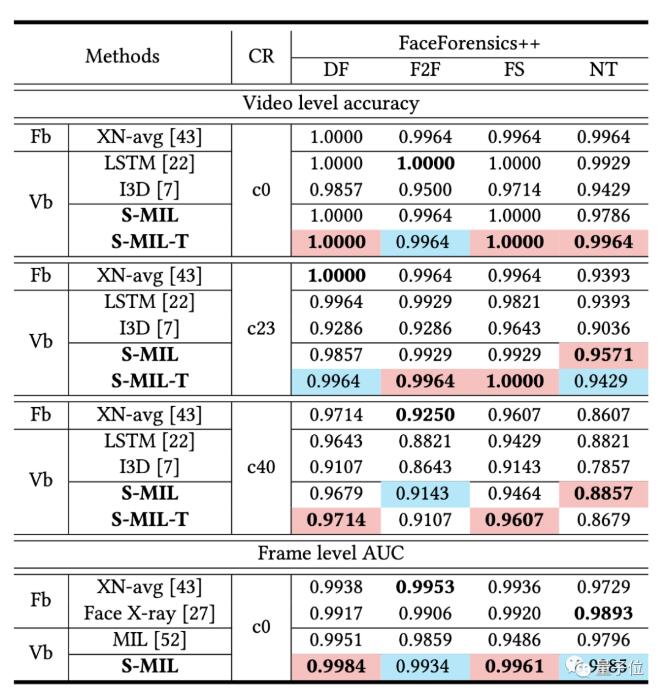
研究人员在DFDC、Celeb和FFPMS数据集上对S-MIL进行了评估。
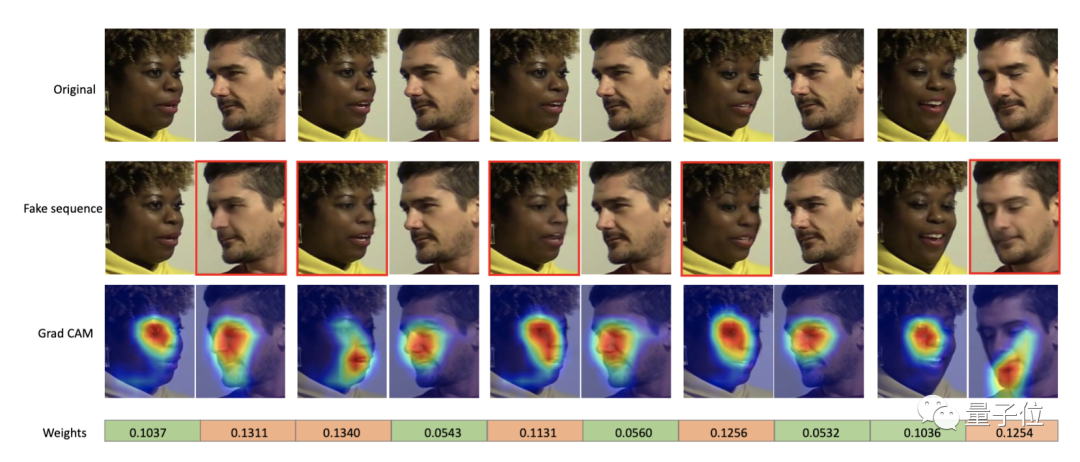
实验结果表明,假脸的权重比较高,说明该方法在仅需视频级别标签的情况下,可以很好地定位到假脸,具有一定的可解释性:
并且,该方法在视频检测上能到达到state-of-the-art的效果。