今天的内容依然是来自《R for datascience》,目前已经看到了15.4了,每次遇到比较有意思的我自己不会的操作就会在这儿写下来,所以,如果你对我写的东西感兴趣的话,建议你去看原版书籍,顺便关注我一波。嘿嘿。
实例操练
这个例子使用的数据集为tidyverse包自带的数据集,大家可以使用?gss_cat查看相关变量,这儿不再赘述。
在数据可视化过程中改变因子顺序是一个经常性的操作,比如我们想看看不同religions的average number of hours spent watching TV per day有什么不同,我们可以用以下代码:
- relig_summary <- gss_cat %>%
- group_by(relig) %>%
- summarise(
- age = mean(age, na.rm = TRUE),
- tvhours = mean(tvhours, na.rm = TRUE),
- n = n()
- )
- ggplot(relig_summary, aes(tvhours, relig)) + geom_point()
运行代码得到输出的点图如下:
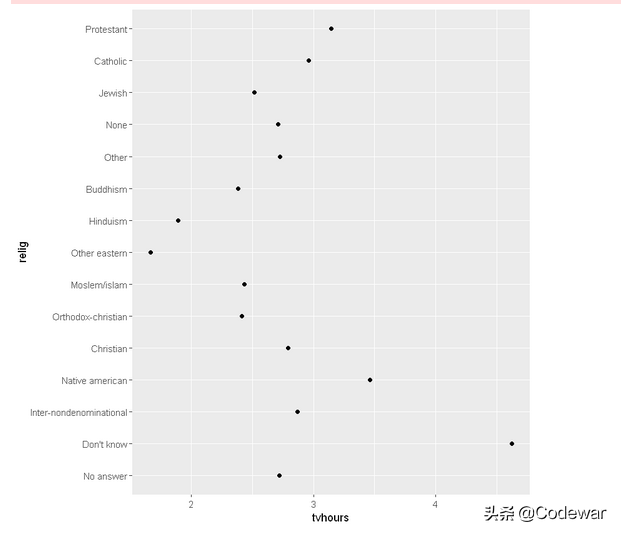
上面的这个点图其实很不好看,我们可能会觉得能不能把religions的顺序变一变,让有最小tvhours的religion在y轴的最下面,有最大tvhours的在最上面。
怎么做呢,需要用到fct_reorder()方法,这个方法取2个参数:
- 第一个就是你想改变顺序的因子,本例中:religions
- 第二个,改变顺序的参照物,本例中:tvhours
代码如下:
- ggplot(relig_summary, aes(tvhours, fct_reorder(relig, tvhours))) +
- geom_point()
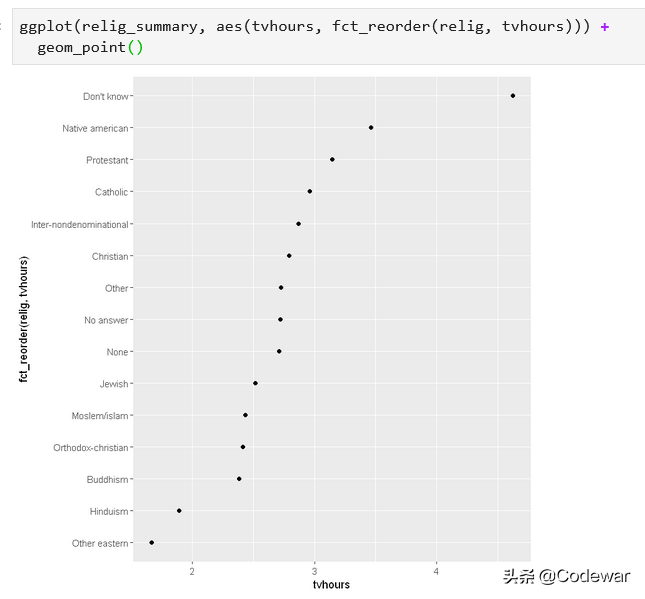
可以看到,改变了religions的顺序后这个图就更加清晰明白了。
再看一个例子:
- rincome_summary <- gss_cat %>%
- group_by(rincome) %>%
- summarise(
- age = mean(age, na.rm = TRUE),
- tvhours = mean(tvhours, na.rm = TRUE),
- n = n()
- )
- ggplot(rincome_summary, aes(age, fct_reorder(rincome, age))) + geom_point()
上面的代码,可以画出按年龄排序后不同rincome和age的关系:
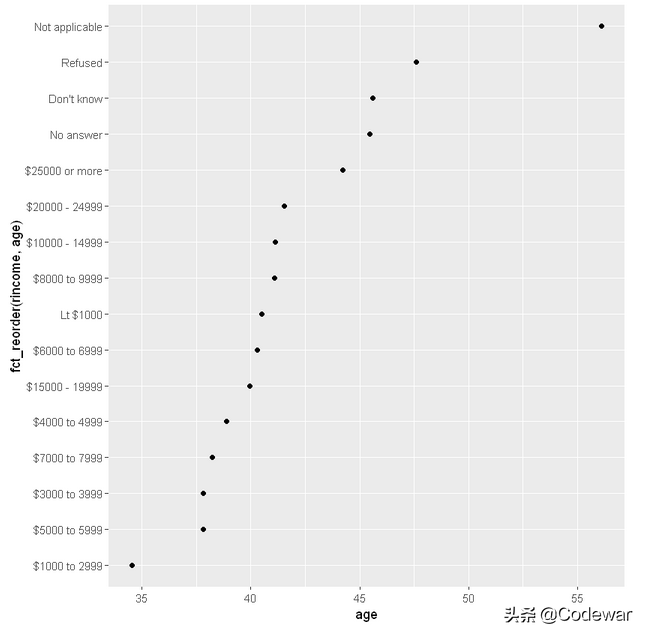
但是,问题出在按年龄排序后我们的收入(y轴)显得很乱,所以这个方法并不好,考虑到收入本来就是有顺序的,所以好的处理方法为保留收入的原始顺序,于是我们写出了如下代码:
- rincome_summary <- gss_cat %>%
- group_by(rincome) %>%
- summarise(
- age = mean(age, na.rm = TRUE),
- tvhours = mean(tvhours, na.rm = TRUE),
- n = n()
- )
- ggplot(rincome_summary, aes(age, rincome)) + geom_point()
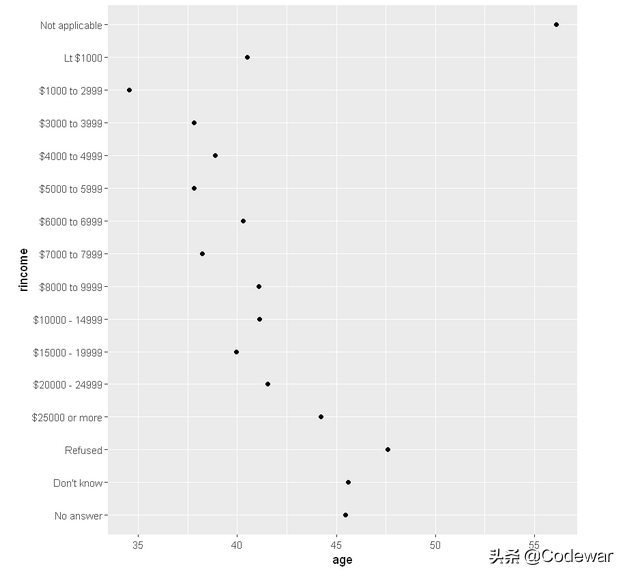
这次再看我们的图,虽然其他的收入levels都排的挺好,但是我们不希望“Not applicable”排在第一。这个时候我们可以用fct_relevel(),它也有2个参数:
- 需要排序的因子,本例中:rincome
- 需要放在最前面的levels,本例中:Not applicable
代码如下:
- ggplot(rincome_summary, aes(age, fct_relevel(rincome, "Not applicable"))) +
- geom_point()
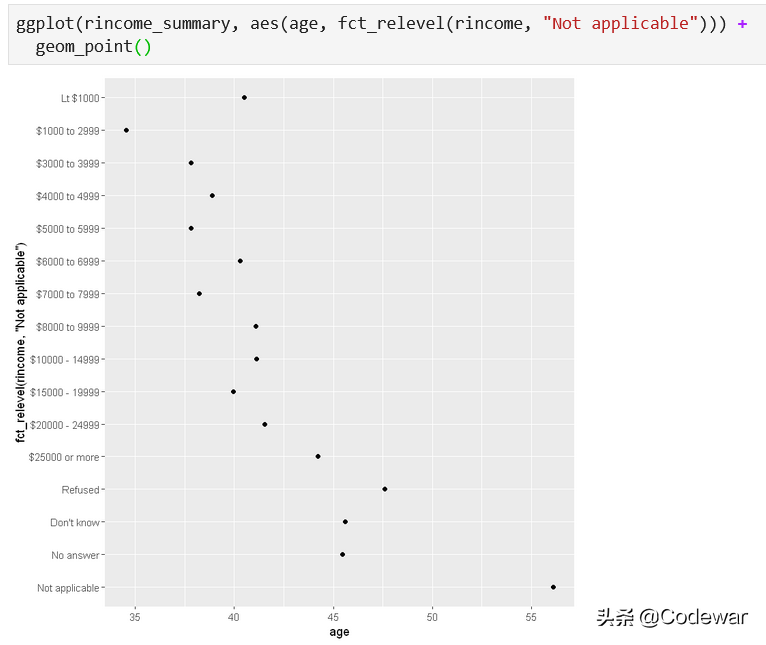
这一下,我们的图形就比较满意了。
再看一个例子:线图的颜色控制:
- by_age <- gss_cat %>%
- filter(!is.na(age)) %>%
- count(age, marital) %>%
- group_by(age) %>%
- mutate(prop = n / sum(n))
- ggplot(by_age, aes(age, prop, colour = marital)) +
- geom_line(na.rm = TRUE)
- ggplot(by_age, aes(age, prop, colour = fct_reorder2(marital, age, prop))) +
- geom_line() +
- labs(colour = "marital")
上面的代码画的是不同的年龄中婚姻状况的比例变化:
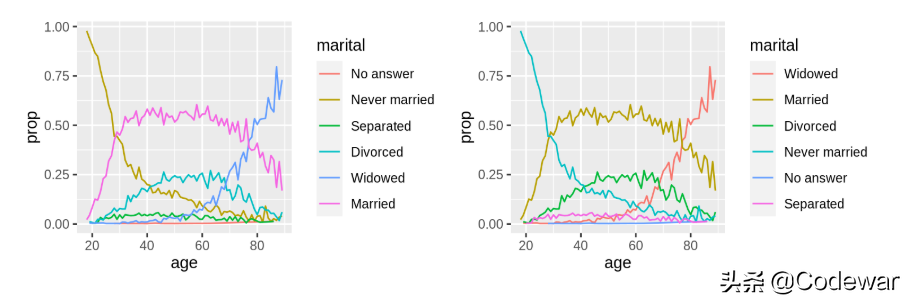
我们通过fct_reorder2实现了图例和x变量最大时y的值的顺序一致,可以更加明晰。
最后再看一个柱状图调整因子顺序的例子
下面的代码可以,正序逆序改变x轴标签:
- gss_cat %>%
- mutate(marital = marital %>% fct_infreq() ) %>%
- ggplot(aes(marital)) +
- geom_bar()
- gss_cat %>%
- mutate(marital = marital %>% fct_infreq() %>% fct_rev()) %>%
- ggplot(aes(marital)) +
- geom_bar()
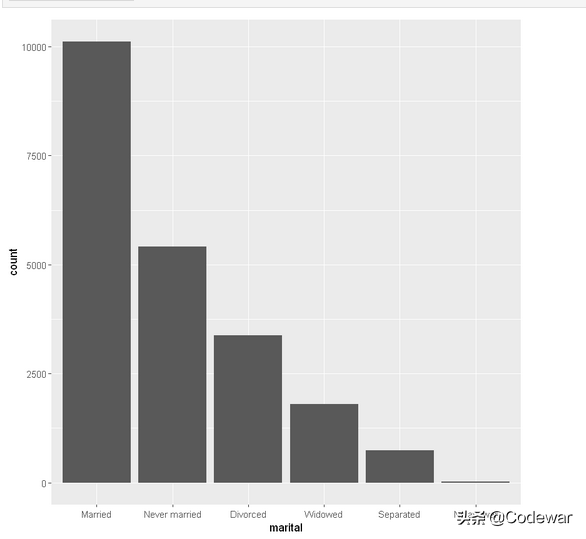
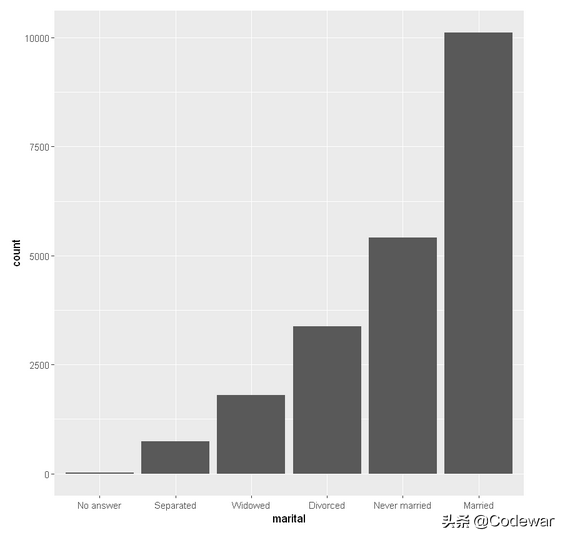
大家可以在自己电脑上运行试试,关键就在于fct_rev()。
小结
今天通过3个例子给大家介绍了可视化中因子顺序的改变,感谢大家耐心看完。发表这些东西的主要目的就是督促自己,希望大家关注评论指出不足,一起进步。内容我都会写的很细,用到的数据集也会在原文中给出链接,你只要按照文章中的代码自己也可以做出一样的结果,一个目的就是零基础也能懂,因为自己就是什么基础没有从零学Python和R的,加油。