












人工智能中的图像处理
人工智能对于图像处理有不同的任务。在本文中,我将介绍目标检测和图像分割之间的区别。
在这两个任务中,我们都希望找到图像中某些感兴趣的项目的位置。例如,我们可以有一组安全摄像头照片,在每张照片上,我们想要识别照片中所有人的位置。
通常有两种方法可以用于此:目标检测(Object Detection)和图像分割(Image Segmentation)。
目标检测-预测包围盒
当我们说到物体检测时,我们通常会说到边界盒。这意味着我们的图像处理将在我们的图片中识别每个人周围的矩形。
边框通常由左上角的位置(2 个坐标)和宽度和高度(以像素为单位)定义。
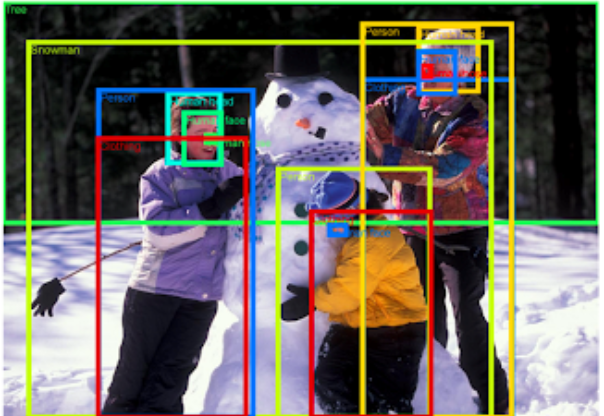
如何理解目标检测方法?
如果我们回到任务:识别图片上的所有人,则可以理解通过边界框进行对象检测的逻辑。
我们首先想到的解决方案是将图像切成小块,然后在每个子图像上应用图像分类,以区别该图像是否是人类。 对单个图像进行分类是一项较容易的任务,并且是对象检测的一项,因此,他们采用了这种分步方法。
当前,YOLO模型(You Only Look Once)是解决此问题的伟大发明。 YOLO模型的开发人员已经构建了一个神经网络,该神经网络能够立即执行整个边界框方法!
当前用于目标检测的最佳模型
- YOLO
- Faster RCNN
图像分割-预测掩模
一步一步地扫描图像的逻辑替代方法是远离画框,而是逐像素地注释图像。
如果你这样做,你将会有一个更详细的模型,它基本上是输入图像的一个转换。
如何理解图像分割方法?
这个想法很基本:即使在扫描产品上的条形码时,也可以应用一种算法来转换输入信息(通过应用各种过滤器),这样,除了条形码序列以外的所有信息在最终图像中都不可见。

左图:https://commons.wikimedia.org/wiki/File:Image-segmentation-example.jpg。右图:https://commons.wikimedia.org/wiki/File:Image-segmentation-example-segmented.png。两个文件都支持 https://en.wikipedia.org/wiki/en:Creative_Commons
这是在图像上定位条形码的基本方法,但与在图像分割中所发生的情况类似。
图像分割的返回格式称为掩码:与原始图像大小相同的图像,但是对于每个像素,它只有一个布尔值来指示对象是否存在。
如果我们允许多个类别,它就会变得更加复杂:例如,它可以将一个海滩景观分为三类:空气、海洋和沙子。
当下图像分割的最佳模型
- Mask RCNN
- Unet
- Segnet
比较总结
对象检测
- 输入是一个矩阵(输入图像),每个像素有 3 个值(红、绿、蓝),如果是黑色和白色,则每个像素有 1 个值
- 输出是由左上角和大小定义的边框列表
图像分割
- 输入是一个矩阵(输入图像),每个像素有 3 个值(红、绿、蓝),如果是黑色和白色,则每个像素有 1 个值
- 输出是一个矩阵(掩模图像),每个像素有一个包含指定类别的值
本文转自雷锋网,如需转载请至雷锋网官网申请授权。


























