当对一个或多个人的谈话进行记录时,采用一种高度准确和自动化的方式将口语提取为文本非常有用。转换成文字后,便可以将其用于进一步分析或用作其他功能。
在本教程中,我们将使用称为AssemblyAI(https://www.assemblyai.com/)的高精度语音转文本Web API从MP3录音中提取文本(也支持许多其他格式)。
在本教程中,音频文件示例下载地址请扫描本文下方二维码添加Python小助手获取,下面是音频输出如下所示的高精度文本转录内容:
- An object relational mapper is a code library that automates the transfer of
- data stored in relational, databases into objects that are more commonly used
- in application code or EMS are useful because they provide a high level
- abstraction upon a relational database that allows developers to write Python
- code instead of sequel to create read update and delete, data and schemas in
- their database. Developers can use the programming language. They are
- comfortable with to work with a database instead of writing SQL...
教程要求
在本教程中,我们将使用以下依赖项,稍后将安装它们。请确保您的环境中还安装了Python 3,最好安装3.6或更高版本:
我们将使用以下依赖关系来完成本教程:
- requests 2.24.0 来向AssemblyAI语音文本API发出HTTP请求
- 一个 AssemblyAI 帐户,您可以在此处(https://app.assemblyai.com/login/)注册免费的API访问密钥
本文所有代码下载地址请扫描本文下方二维码添加Python小助手获取。
搭建开发环境
转到保存Python虚拟环境的目录。我将我的目录保存在用户主目录下的venvs子目录中。使用以下命令为此项目创建一个新的virtualenv。
- python3 -m venv ~/venvs/pytranscribe
用 shell 命令激活 virtualenv:
- source ~/venvs/pytranscribe/bin/activate
执行上述命令后,命令提示符将发生更改,因此virtualenv的名称将以原始命令提示符格式开头,如果您的提示符只是$,则其外观如下所示:
- (pytranscribe) $
请记住,您必须在每个 virtualenv 中使用依赖项的新终端窗口中激活您的 virtualenv 。
现在,我们可以将请求包安装到已激活但为空的 virtualenv 中。
- pip install requests==2.24.0
查找类似于以下内容的输出,以确认从PyPI正确安装了相应的软件包。
- (pytranscribe) $ pip install requests==2.24.0
- Collecting requests==2.24.0
- Using cached https://files.pythonhosted.org/packages/45/1e/0c169c6a5381e241ba7404532c16a21d86ab872c9bed8bdcd4c423954103/requests-2.24.0-py2.py3-none-any.whl
- Collecting certifi>=2017.4.17 (from requests==2.24.0)
- Using cached https://files.pythonhosted.org/packages/5e/c4/6c4fe722df5343c33226f0b4e0bb042e4dc13483228b4718baf286f86d87/certifi-2020.6.20-py2.py3-none-any.whl
- Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 (from requests==2.24.0)
- Using cached https://files.pythonhosted.org/packages/9f/f0/a391d1463ebb1b233795cabfc0ef38d3db4442339de68f847026199e69d7/urllib3-1.25.10-py2.py3-none-any.whl
- Collecting chardet<4,>=3.0.2 (from requests==2.24.0)
- Using cached https://files.pythonhosted.org/packages/bc/a9/01ffebfb562e4274b6487b4bb1ddec7ca55ec7510b22e4c51f14098443b8/chardet-3.0.4-py2.py3-none-any.whl
- Collecting idna<3,>=2.5 (from requests==2.24.0)
- Using cached https://files.pythonhosted.org/packages/a2/38/928ddce2273eaa564f6f50de919327bf3a00f091b5baba8dfa9460f3a8a8/idna-2.10-py2.py3-none-any.whl
- Installing collected packages: certifi, urllib3, chardet, idna, requests
- Successfully installed certifi-2020.6.20 chardet-3.0.4 idna-2.10 requests-2.24.0 urllib3-1.25.10
我们已经安装了所有必需的依赖项,因此我们可以开始对应用程序进行编码。
上传、启动和转录音频
我们已完成开始构建应用程序所需的一切,该应用程序会将音频转换为文本。我们将在三个文件中构建此应用程序:
1、upload_audio_file.py:将您的音频文件上传到AssemblyAI服务上的安全位置,以便可以进行处理。如果您的音频文件已经可以通过公共URL访问,则无需执行此步骤,只需按照此快速入门(https://docs.assemblyai.com/overview/getting-started)
2、initial_transcription.py:告诉API要转录并立即启动的文件
3、get_transcription.py:如果仍在处理转录,则显示转录状态,或者在处理完成后显示转录结果
创建一个名为pytranscribe的新目录,以在我们编写文件时存储这些文件。然后转到新的项目目录。
- mkdir pytranscibe
- cd pytranscribe
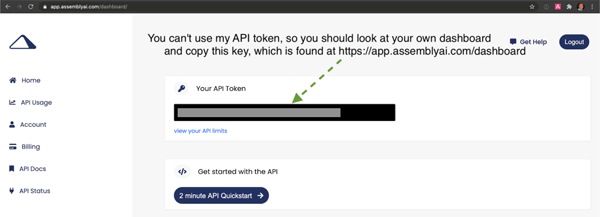
我们还需要将 AssemblyAI API 密钥导出为环境变量。注册 AssemblyAI 帐户并登录 AssemblyAI 仪表板,然后复制“您的API token”,如以下屏幕截图所示:
- export ASSEMBLYAI_KEY=your-api-key-here
请注意,必须每个命令行窗口中使用 export 命令以保证此密钥可访问。如果您没有在运行脚本的环境中将标记导出为 ASSEMBLYAI_KEY,则我们正在编写的脚本将无法访问API。
现在我们已经创建了项目目录并将API密钥设置为环境变量,让我们继续编写第一个文件的代码,该文件会将音频文件上传到AssemblyAI服务。
上传音频文件并进行转录
创建一个名为upload_audio_file.py的新文件,并将以下代码放入其中:
- import argparse
- import os
- import requests
- API_URL = "https://api.assemblyai.com/v2/"
- def upload_file_to_api(filename):
- """Checks for a valid file and then uploads it to AssemblyAI
- so it can be saved to a secure URL that only that service can access.
- When the upload is complete we can then initiate the transcription
- API call.
- Returns the API JSON if successful, or None if file does not exist.
- """
- if not os.path.exists(filename):
- return None
- def read_file(filename, chunk_size=5242880):
- with open(filename, 'rb') as _file:
- while True:
- data = _file.read(chunk_size)
- if not data:
- break
- yield data
- headers = {'authorization': os.getenv("ASSEMBLYAI_KEY")}
- response = requests.post("".join([API_URL, "upload"]), headersheaders=headers,
- data=read_file(filename))
- return response.json()
上面的代码导入了argparse,os和request软件包,以便我们可以在此脚本中使用它们。API_URL是一个常量,具有AssemblyAI服务的基本URL。我们使用单个参数定义upload_file_to_api函数,filename应该是一个字符串,其中包含文件及其文件名的绝对路径。
在函数中,我们检查文件是否存在,然后使用Request的分块传输编码将大文件流式传输到AssemblyAI API。
os模块的getenv函数读取使用带有getenv的export命令在命令行上设置的API。确保在运行此脚本的终端中使用该导出命令,否则ASSEMBLYAI_KEY值将为空白。如有疑问,请使用echo $ ASSEMBLY_AI查看该值是否与您的API密钥匹配。
要使用upload_file_to_api函数,请将以下代码行添加到upload_audio_file.py文件中,以便我们可以正确地将此代码作为使用python命令调用的脚本执行:
- if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("filename")
- args = parser.parse_args()
- upload_filename = args.filename
- response_json = upload_file_to_api(upload_filename)
- if not response_json:
- print("file does not exist")
- else:
- print("File uploaded to URL: {}".format(response_json['upload_url']))
上面的代码创建了一个ArgumentParser对象,它允许应用程序从命令行获取单个参数来指定我们要访问的对象,读取并上传到AssmeblyAI服务的文件。
如果文件不存在,脚本将显示一条消息,提示找不到该文件。在路径中,我们确实找到了正确的文件,然后使用upload_file_to_api函数中的代码上传了文件。
通过使用python命令在命令行上运行完整的upload_audio_file.py脚本,以执行该脚本。将FULL_PATH_TO_FILE替换为您要上传的文件的绝对路径,例如/Users/matt/devel/audio.mp3。
- python upload_audio_file.py FULL_PATH_TO_FILE
假设在您指定的位置找到文件,当脚本完成文件的上传后,它将打印一条带有唯一URL的消息:
- File uploaded to URL: https://cdn.assemblyai.com/upload/463ce27f-0922-4ea9-9ce4-3353d84b5638
该URL不是公开的,只能由AssemblyAI服务使用,因此除您及其转录的API外,其他任何人都无法访问您的文件及其内容。
重要的部分是URL的最后一部分,在此示例中为463ce27f-0922-4ea9-9ce4-3353d84b5638。保存该唯一标识符,因为我们需要将其传递给下一个启动转录服务的脚本。
启动转录
接下来,我们将编写一些代码来开始转录。创建一个名为initial_transcription.py的新文件。将以下代码添加到新文件中。
- import argparse
- import os
- import requests
- API_URL = "https://api.assemblyai.com/v2/"
- CDN_URL = "https://cdn.assemblyai.com/"
- def initiate_transcription(file_id):
- """Sends a request to the API to transcribe a specific
- file that was previously uploaded to the API. This will
- not immediately return the transcription because it takes
- a moment for the service to analyze and perform the
- transcription, so there is a different function to retrieve
- the results.
- """
- endpoint = "".join([API_URL, "transcript"])
- json = {"audio_url": "".join([CDN_URL, "upload/{}".format(file_id)])}
- headers = {
- "authorization": os.getenv("ASSEMBLYAI_KEY"),
- "content-type": "application/json"
- }
- response = requests.post(endpoint, jsonjson=json, headersheaders=headers)
- return response.json()
我们具有与先前脚本相同的导入,并添加了一个新常量CDN_URL,该常量与AssemblyAI存储上传的音频文件的单独URL匹配。
initiate_transcription函数本质上只是向AssemblyAI API设置了一个HTTP请求,以传入的特定URL对音频文件启动转录过程。这就是为什么file_id传递很重要的原因:完成音频文件的URL 我们告诉AssemblyAI进行检索。
通过附加此代码来完成文件,以便可以从命令行轻松地使用参数调用它。
- if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("file_id")
- args = parser.parse_args()
- file_id = args.file_id
- response_json = initiate_transcription(file_id)
- print(response_json)
通过在initiate_transcription文件上运行python命令来启动脚本,并传入您在上一步中保存的唯一文件标识符。
- # the FILE_IDENTIFIER is returned in the previous step and will
- # look something like this: 463ce27f-0922-4ea9-9ce4-3353d84b5638
- python initiate_transcription.py FILE_IDENTIFIER
API将发回该脚本打印到命令行的JSON响应。
- {'audio_end_at': None, 'acoustic_model': 'assemblyai_default', 'text': None,
- 'audio_url': 'https://cdn.assemblyai.com/upload/463ce27f-0922-4ea9-9ce4-3353d84b5638',
- 'speed_boost': False, 'language_model': 'assemblyai_default', 'redact_pii': False,
- 'confidence': None, 'webhook_status_code': None,
- 'id': 'gkuu2krb1-8c7f-4fe3-bb69-6b14a2cac067', 'status': 'queued', 'boost_param': None,
- 'words': None, 'format_text': True, 'webhook_url': None, 'punctuate': True,
- 'utterances': None, 'audio_duration': None, 'auto_highlights': False,
- 'word_boost': [], 'dual_channel': None, 'audio_start_from': None}
记下JSON响应中id键的值。这是我们需要用来检索转录结果的转录标识符。在此示例中,它是gkuu2krb1-8c7f-4fe3-bb69-6b14a2cac067。复制转录标识符到您自己的响应中,因为在下一步中我们将需要它来检查转录过程何时完成。
检索转录结果
我们已经上传并开始了转录过程,因此,准备就绪后,我们将尽快获得结果。
返回结果所需的时间取决于文件的大小,因此下一个脚本将向HTTP发送一个HTTP请求,并报告转录状态,或者在完成后打印输出。
创建一个名为 get_transcription.py 的第三个Python文件,并将以下代码放入其中。
- import argparse
- import os
- import requests
- API_URL = "https://api.assemblyai.com/v2/"
- def get_transcription(transcription_id):
- """Requests the transcription from the API and returns the JSON
- response."""
- endpoint = "".join([API_URL, "transcript/{}".format(transcription_id)])
- headers = {"authorization": os.getenv('ASSEMBLYAI_KEY')}
- response = requests.get(endpoint, headersheaders=headers)
- return response.json()
- if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument("transcription_id")
- args = parser.parse_args()
- transcription_id = args.transcription_id
- response_json = get_transcription(transcription_id)
- if response_json['status'] == "completed":
- for word in response_json['words']:
- print(word['text'], end=" ")
- else:
- print("current status of transcription request: {}".format(
- response_json['status']))
上面的代码与其他脚本具有相同的 imports 对象。在这个新的get_transcription函数中,我们只需使用我们的API密钥和上一步中的转录标识符(而不是文件标识符)调用AssemblyAI API。我们检索JSON响应并将其返回。
在main函数中,我们处理作为命令行参数传入的转录标识符,并将其传递给get_transcription函数。如果来自get_transcription函数的响应JSON包含completed状态,则我们将打印转录结果。否则,请在completed之前打印当前状态如queued或processing。
使用命令行和上一节中的转录标识符调用脚本:
- python get_transcription.py TRANSCRIPTION_ID
如果该服务尚未开始处理脚本,则它将返回queued,如下所示:
- current status of transcription request: queued
当服务当前正在处理音频文件时,它将返回processing:
- current status of transcription request: processing
该过程完成后,我们的脚本将返回转录文本,如您在此处看到的那样:
- An object relational mapper is a code library that automates the transfer of
- data stored in relational, databases into objects that are more commonly used
- in application code or EMS are useful because they provide a high level
- ...(output abbreviated)
就是这样,我们已经转录完成了!
您可能想知道如果精度不适合您的情况该怎么办。这就是需要用到提高关键字或短语的准确性方法(https://docs.assemblyai.com/guides/boosting-accuracy-for-keywords-or-phrases)和选择与数据更匹配的模型方法(https://docs.assemblyai.com/guides/transcribing-with-a-different-acoustic-or-custom-language-model)的地方。您可以使用这两种方法中的任一种,将记录的准确性提高到适合您情况的水平。
下一步是什么?
我们刚刚完成了一些脚本,这些脚本调用AssemblyAI API来将带有语音的录音转录为文本输出。您可以查阅文档(https://docs.assemblyai.com/overview/getting-started)来增加一些更高级功能:
- 支持不同的文件格式
- 转录双通道/立体声录音
- 获取扬声器标签(扬声器隔离)