前言
在很多网站上,都会以表格的形式展示数据,而我们获取这种数据只需通过十几行爬虫代码就可以搞定,轻松搞定网页爬虫,实现高效办公
知识点:
- 爬虫基本原理
- requests的简单使用
- pandas库
- pyecharts可视化工具
第三方库:
- requests
- pandas
开发环境:
- Python 3.6
- Pycharm
这里就只展示部分代码了
爬虫代码
1.导入工具
- from urllib.parse import urlencode
- import requests
- import csv
- from bs4 import BeautifulSoup
- import pandas as pd
2.网页提取函数
- def get_one_page(i):
- paras = {
- 'reportTime': '2019-12-31',
- # 可以改报告日期,比如2018-6-30获得的就是该季度的信息
- 'pageNum': i # 页码
- }
- url = 'http://s.askci.com/stock/a/?' + urlencode(paras)
- response = requests.get(url, headers=headers)
- if response.status_code == 200:
- return response.text
3.提取表格数据
- def parse_one_page(html):
- tb = pd.read_html(html)[3]
- return tb
4.保存数据
- def save_csv():
- pass
- if __name__ == '__main__':
- html = get_one_page(1)
- parse_one_page(html)
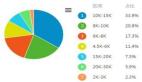
运行代码,效果如下图
数据可视化代码
- ffrom pyecharts import options as opts
- from pyecharts.charts import Map
- from pyecharts.faker import Faker
- df = pd.read_csv('1.csv')
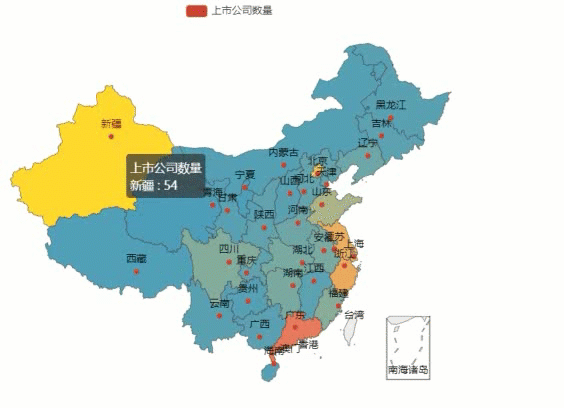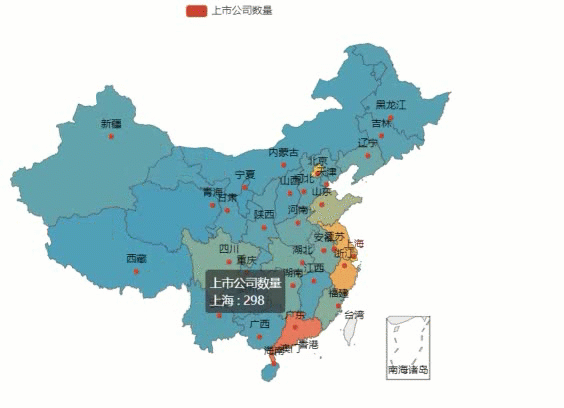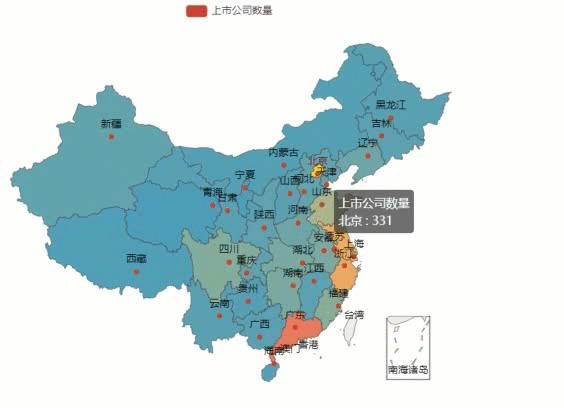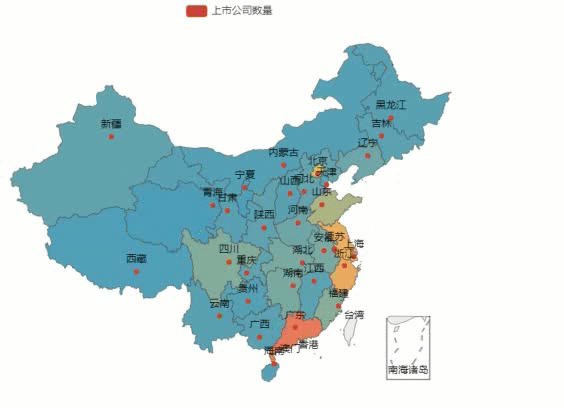
- data = [['北京',331], ['西藏',18], ['湖北',103], ['上海',298], ['天津',50], ['陕西',51], ['安徽',106], ['河北',58], ['贵州',29], ['河南',79], ['山东',206], ['广东',603], ['江西',41], ['江苏',420], ['浙江',443], ['湖南',105], ['黑龙江',37], ['辽宁',78], ['福建',134], ['四川',125], ['重庆',50], ['广西',38], ['新疆',54], ['云南',37], ['山西',38], ['宁夏',14], ['海南',30], ['甘肃',33], ['吉林',42], ['内蒙古',25], ['青海',12]]
- c = (
- Map()
- .add("上市公司数量 ", data, "china")
- .set_global_opts(
- title_opts=opts.TitleOpts(title="上市公司数量分布"),
- visualmap_opts=opts.VisualMapOpts(max_=700),
- )
- )
- c.render_notebook()
最后运行代码,效果如下图