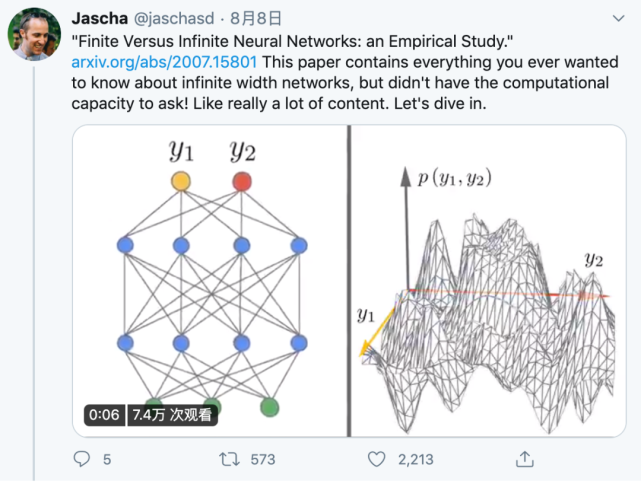
无限宽度神经网络是近来一个重要的研究课题,但要通过实证实验来探索它们的性质,必需大规模的计算能力才行。近日,谷歌大脑公布的一篇论文介绍了他们在有限和无限神经网络方面的系统性探索成果。该研究通过大规模对比实验得到了 12 条重要的实验结论并在此过程中找到了一些新的改进方法。该文作者之一 Jascha Sohl-Dickstein 表示:「这篇论文包含你想知道的但没有足够的计算能力探求的有关无限宽度网络的一切!」
近日,谷歌大脑的研究者通过大规模实证研究探讨了宽神经网络与核(kernel)方法之间的对应关系。在此过程中,研究者解决了一系列与无限宽度神经网络研究相关的问题,并总结得到了 12 项实验结果。
此外,实验还额外为权重衰减找到了一种改进版逐层扩展方法,可以提升有限宽度网络的泛化能力。
最后,他们还为使用 NNGP(神经网络高斯过程)和 NT(神经正切)核的预测任务找到了一种改进版的最佳实践,其中包括一种全新的集成(ensembling)技术。这些最佳实践技术让实验中每种架构对应的核在 CIFAR-10 分类任务上均取得了当前最佳的成绩。

论文链接:https://arxiv.org/pdf/2007.15801v1.pdf
当使用贝叶斯方法和梯度下降方法训练的神经网络的中间层是无限宽时,这些网络可以收敛至高斯过程或紧密相关的核方法。这些无限宽度网络的预测过程可通过贝叶斯网络的神经网络高斯过程(NNGP)核函数来描述,也可通过梯度下降方法所训练网络的神经正切核(NTK)和权重空间线性化来描述。
这种对应关系是近来在理解神经网络方面获得突破的关键,同时还使核方法、贝叶斯深度学习、主动学习和半监督学习取得了切实的进步。在为大规模神经网络提供确切理论描述时,NNGP、NTK 和相关的宽度限制都是独特的。因此可以相信它们仍将继续为深度学习理论带来变革。
无限网络是近来一个活跃的研究领域,但其基础性的实证问题仍待解答。谷歌大脑的这项研究对有限和无限宽度神经网络进行了广泛深入的实证研究。在此过程中,研究者通过实证数据定量地解答了影响有限网络和核方法性能的变化因素,揭示了出人意料的新行为,并开发了可提升有限与无限宽度网络性能的最佳实践。
实验设计
为了系统性地对无限和有限神经网络进行实证研究,研究者首先确立了每种架构的 base,方便直接对比无限宽度核方法、线性化权重空间网络和基于非线性梯度下降的训练方法。对于有限宽度的情况,base 架构使用了恒定小学习率且损失为 MSE(均方误差)的 mini-batch 梯度下降。在核学习设置中,研究者为整个数据集计算了 NNGP 和 NTK。
完成这种一对一的比较之后,研究者在 base 模型之上进行了大量不同种类的修改。某些修改会大致保留其对应关系(比如数据增强),而另一些则会打破这种对应关系,并且假设对应关系的打破会影响到性能结果(比如使用较大的学习率)。
此外,研究者还围绕 base 模型的初始化对其进行线性化尝试,在这种情况下,其训练动态可使用常量核来精准地描述。由于有限宽度效应,这不同于前文描述的核设置。
该研究使用 MSE 损失的原因是能更容易地与核方法进行比较,交叉熵损失在性能方面比 MSE 损失略好,但这还留待未来研究。
该研究涉及的架构要么是基于全连接层(FCN)构建的,要么就是用卷积层(CNN)构建的。所有案例都使用了 ReLU 非线性函数。除非另有说明,该研究使用的模型都是 3 层的 FCN 和 8 层的 CNN。对于卷积网络,在最后的读出层(readout layer)之前必须压缩图像形状数据的空间维度。为此,要么是将图像展平为一维向量(VEC),要么是对空间维度应用全局平均池化(GAP)。
最后,研究者比较了两种参数化网络权重和偏置的方法:标准参数化(STD)和 NTK 参数化(NTK)。其中 STD 用于有限宽度网络的研究,NTK 则在目前大多数无限宽度网络研究中得到应用。
除非另有说明,该研究中所有核方法的实验都是基于对角核正则化(diagonal kernel regularization)独立优化完成的。有限宽度网络则全都使用了与 base 模型相对应的小学习率。
这篇论文中的实验基本都是计算密集型的。举个例子,要为 CNN-GAP 架构在 CIFAR-10 上计算 NTK 或 NNGP,就必须用 6×10^7 乘 6×10^7 的核矩阵对各项进行评估。通常来说,这需要双精度 GPU 时间约 1200 小时,因此研究者使用了基于 beam 的大规模分布式计算基础设施。
所有实验都使用了基于 JAX 的 Neural Tangents 库:https://github.com/google/neural-tangents。
为了尽可能地做到系统性,同时又考虑到如此巨大的计算需求,于是研究者仅使用了一个数据集 CIFAR-10,即在该数据集上评估对每种架构的每种修改措施。同时,为了保证结果也适用于不同的数据集,研究者还在 CIFAR-100 和 Fashion-MNIST 上评估了部分关键结果。
从实验中得到的 12 条结论
以下为基于实验结果总结的 12 个结论(详细分析请参阅原论文):
1. NNGP/NTK 的表现可胜过有限网络
在无限网络研究中,一个常见假设是它们在大数据环境中的表现赶不上对应的有限网络。通过比较核方法与有限宽度架构(使用小学习率,无正则化)的 base 模型,并逐一验证可打破(大学习率、L2 正则化)或改进(集成)无限宽度与核方法对应性的训练实践的效果,研究者验证了这一假设。结果见下图 1:
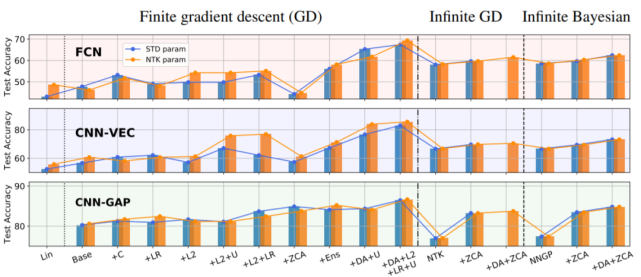
图 1:有限和无限网络及其变体在 CIFAR-10 上的测试准确率。从给定架构类别的有限宽度 base 网络开始,标准和 NTK 参数化的模型表现随着修改而发生变化:+C 指居中(Centering)、+LR 指大学习率、+U 指通过早停实现欠拟合、+ZCA 指使用 ZCA 正则化进行输入预处理、+Ens 指多个初始化集成,另外还有一些组合方案。Lin 指线性化 base 网络的性能。
从中可以观察到,对于 base 有限网络,无限 FCN 和 CNN-VEC 的表现要优于它们各自对应的有限网络。另一方面,无限 CNN-GAP 网络的表现又比其对应的有限版本差。研究者指出这其实与架构有关。举例来说,即使有限宽度 FCN 网络组合了高学习率、L2 和欠拟合等多种不同技巧,无限 FCN 网络的性能还是更优。只有再加上集成之后,有限网络的性能才能达到相近程度。
另一个有趣的观察是,ZCA 正则化预处理能显著提升 CNN-GAP 核的表现。
2. NNGP 通常优于 NTK
从下图 2 中可以看出,在 CIFAR-10、CIFAR-100 和 Fashion-MNIST 数据集上 NNGP 的性能持续优于 NTK。NNGP 核不仅能得到更强的模型,而且所需的内存和计算量也仅有对应的 NTK 的一半左右,而且某些性能最高的核根本就没有对应的 NTK 版本。

图 2:当对角正则化经过精心调整时,NNGP 在图像分类任务上通常优于 NTK。
3. 居中和集成有限网络都会得到类 kernel 的表现

图 3:居中可以加速训练和提升性能。

图 4:集成 base 网络可让它们达到与核方法相媲美的表现,并且在非线性 CNN 上还优于核方法。
4. 大学习率和 L2 正则化会让有限网络和核之间出现差异
从上图 1 中可以观察到,大学习率(LR)的效果容易受到架构和参数化的影响。
L2 正则化则能稳定地提升所有架构和参数化的性能(+1-2%)。即使使用经过精心调节的 L2 正则化,有限宽度 CNN-VEC 和 FCN 依然比不上 NNGP/NTK。L2 结合早停能为有限宽度 CNN-VEC 带来 10-15% 的显著性能提升,使其超过 NNGP/NTK。
5. 使用标准参数化能为网络提升 L2 正则化
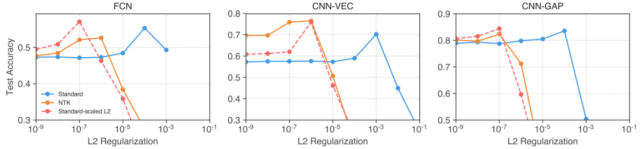
图 5:受 NTK 启发的逐层扩展能让 L2 正则化在标准参数化网络中更有帮助。
研究者发现,相比于使用标准参数化,使用 NTK 参数化时 L2 正则化能为有限宽度网络带来显著的性能提升。使用两种参数化的网络的权重之间存在双射映射。受 NTK 参数化中 L2 正则化项性能提升的启发,研究者使用这一映射构建了一个可用于标准参数化网络的正则化项,其得到的惩罚项与原版 L2 正则化在对应的 NTK 参数化网络上得到的一样。
6. 在超过两次下降的宽度中,性能表现可能是非单调的

图 6:有限宽度网络在宽度增大时通常会有更好的表现,但 CNN-VEC 表现出了出人意料的非单调行为。L2:在训练阶段允许非零权重衰减,LR:允许大学习率,虚线表示允许欠拟合(U)。
7. 核对角正则化的行为类似于早停

图 7:对角核正则化的行为类似于早停。实线对应具备不同对角正则化 ε 的 NTK 推断;虚线对应梯度下降到时间 τ = ηt 后的预测结果,线条颜色表示不同的训练集大小 m。在时间 t 执行早停紧密对应于使用系数 ε = Km/ηt 的正则化,其中 K=10 表示输出类别的数量。
8. 浮点数精度决定了核方法失败的关键数据集大小
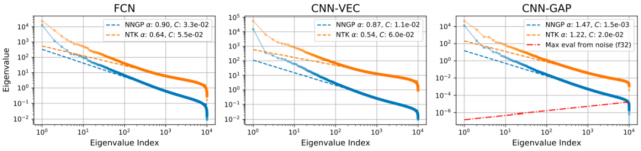
图 8:无限网络核的尾部特征值表现出了幂律衰减趋势。
9. 由于条件不好,线性化 CNN-GAP 模型表现很差
研究者观察到线性化 CNN-GAP 在训练集上的收敛速度非常慢,导致其验证表现也很差(见上图 3)。
这一结果的原因是池化网络的条件很差。Xiao 等人的研究 [33] 表明 CNN-GAP 网络初始化的条件比 FCN 或 CNN-VEC 网络差了像素数倍(对 CIFAR-10 来说是 1024)。
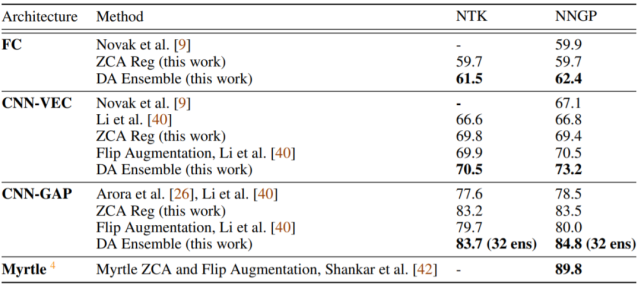
表 1:对应架构类型的核的 CIFAR-10 测试准确率。
10. 正则化 ZCA 白化(whitening)可提升准确率
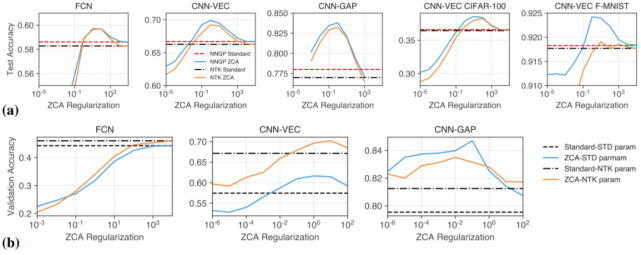
图 9:正则化 ZCA 白化可提升有限和无限宽度网络的图像分类性能。所有的图都将性能表现为 ZCA 正则化强度的函数。a)在 CIFAR-10、Fashion-MNIST、CIFAR-100 上核方法输入的 ZCA 白化;b)有限宽度网络输入的 ZCA 白化。
11. 同变性(equivariance)仅对远离核区域的窄网络有益

图 10:同变性仅在核区域之外的 CNN 模型中得到利用。
如果 CNN 模型能有效地利用同变性,则预计它能比 FCN 更稳健地处理裁剪和平移。出人意料的是,宽 CNN-VEC 的性能会随输入扰动的幅度而下降,而且下降速度与 FCN 一样快,这说明同变性并未得到利用。相反,使用权重衰减的窄模型(CNN-VEC+L2+narrow)的性能下降速度要慢得多。正如预期,平移不变型 CNN-GAP 依然是最稳健的。
12. 集成核预测器可使用 NNGP/NTK 进行实用的数据增强

图 11:集成核预测器(ensembling kernel predictors)可使基于大规模增强数据集的预测在计算上可行。
可以观察到,DA 集成可提升准确率,且相比于 NTK,它对 NNGP 的效果要好得多。
这里研究者提出了一种直接让集成核预测器实现更广泛的数据增强的方法。该策略涉及到构建一组经过增强的数据批,为其中每一批执行核推断,然后执行所得结果的集成。这相当于用模块对角近似替代核,其中每个模块都对应一个数据批,所有增强的数据批的并集即为完整的增强数据集。该方法在该研究所有无线宽度架构的对应核方法上都取得了当前最佳结果。