如果说 GPT 模型是所向披靡的战舰,那么 minGPT 大概算是个头虽小但仍能乘风破浪的游艇了吧。
最近,「史上最大 AI 模型」GPT-3 风靡全球。
GPT 系列可以说是人工智能领域「暴力美学」的代表作了。2018 诞生的 GPT,1.17 亿参数;2019 年 GPT-2,15 亿参数;2020 年 GPT-3,1750 亿参数。短短一年时间,GPT 模型的参数量就呈指数级增长。
GPT-3 发布后不久,OpenAI 即向社区开放了商业 API,鼓励大家使用 GPT-3 尝试更多的实验。然而,API 的使用需要申请,而且你的申请很有可能石沉大海。那么,除了使用官方 API 以外,我们还有没有其他方法能上手把玩一下这个「最大模型」呢?
近日,特斯拉人工智能研究负责人、前 OpenAI 研究科学家 Andrej Karpathy 进行了尝试。
他基于 PyTorch,仅用 300 行左右的代码就写出了一个小型 GPT 训练库,并将其命名为 minGPT。
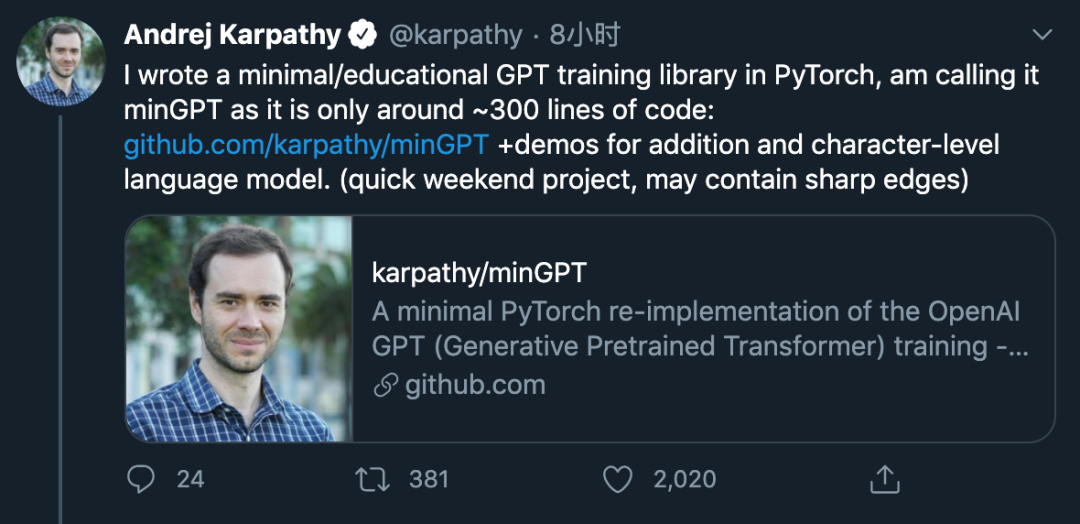
Karpathy 表示,这个 minGPT 能够进行加法运算和字符级的语言建模,而且准确率还不错。不过,在运行 demo 后,Andrej Karpathy 发现了一个有趣的现象:2 层 4 注意力头 128 层的 GPT 在两位数加法运算中,将 55 + 45 的结果计算为 90,而其他加法运算则没有问题。
目前,该项目在 GitHub 上亮相还没满 24 小时,但 star 量已经破千。
minGPT 项目地址:https://github.com/karpathy/minGPT
minGPT:只用 300 行代码实现的 GPT 训练
如果说 GPT 模型是所向披靡的战舰,那么 minGPT 大概算是个个头虽小但仍能乘风破浪的游艇了吧。
在项目页面中,Karpathy 介绍称:由于现有可用的 GPT 实现库略显杂乱,于是他在创建 minGPT 的过程中, 力图遵循小巧、简洁、可解释、具有教育意义等原则。
GPT 并非一个复杂的模型,minGPT 实现只有大约 300 行代码,包括样板文件和一个完全不必要的自定义因果自注意力模块。Karpathy 将索引序列变成了一个 transformer 块序列,如此一来,下一个索引的概率分布就出现了。剩下的复杂部分就是巧妙地处理 batching,使训练更加高效。
核心的 minGPT 库包含两个文档:mingpt/model.py 和 mingpt/trainer.py。前者包含实际的 Transformer 模型定义,后者是一个与 GPT 无关的 PyTorch 样板文件,可用于训练该模型。相关的 Jupyter notebook 则展示了如何使用该库训练序列模型:
- play_math.ipynb 训练一个专注于加法的 GPT;
- play_char.ipynb 将 GPT 训练成一个可基于任意文本使用的字符级语言模型,类似于之前的 char-rnn,但用 transformer 代替了 RNN;
- play_words.ipynb 是 BPE(Byte-Pair Encoding)版本,目前尚未完成。
使用 BPE 编码器、分布式训练和 fp16,这一实现有可能复现 GPT-1/GPT-2 的结果,不过 Karpathy 还没有尝试。至于 GPT-3,minGPT 可能无法复现,因为 GPT-3 可能不适合 GPU 内存,而且需要更精细的模型并行化处理。
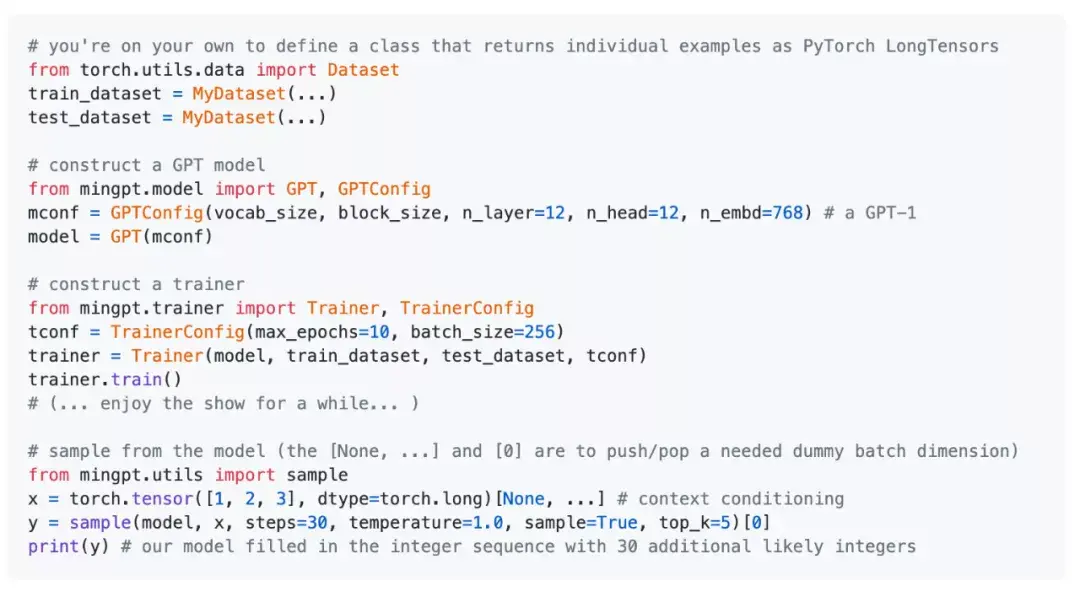
使用示例
Karpathy 在 minGPT 项目中提供了一些使用示例。
这些代码非常简单,只需 hack inline 即可,而非「使用」。目前的 API 外观如下:
minGPT 是如何实现的?
在实现过程中,Karpathy 参考了 OpenAI GPT 官方项目,以及其他组织的示例等。
代码
- OpenAI gpt-2 项目提供了模型,但没有提供训练代码(https://github.com/openai/gpt-2);
- OpenAI 的 image-gpt 库在其代码中进行了一些类似于 GPT-3 的更改,是一份不错的参考(https://github.com/openai/image-gpt);
- Huggingface 的 transformers 项目提供了一个语言建模示例。它功能齐全,但跟踪起来有点困难。(https://github.com/huggingface/transformers/tree/master/examples/language-modeling)
论文 + 实现说明
此外,项目作者还介绍了相关的论文和实现细节。
1. GPT-1:《Improving Language Understanding by Generative Pre-Training》
- 论文地址:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
GPT-1 模型大体遵循了原始 transformer,训练了仅包含 12 层解码器、具备遮蔽自注意力头(768 维状态和 12 个注意力头)的 transformer。具体实现细节参见下图:

2. GPT-2:《Language Models are Unsupervised Multitask Learners》
- 论文地址:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
GPT-2 将 LayerNorm 移动每个子模块的输入,类似于预激活残差网络,并在最后的自注意力模块后添加了一个额外的层归一化。此外,该模型还更改了模型初始化(包括残差层初始化权重等)、扩展了词汇量、将 context 规模从 512 个 token 增加到 1024、使用更大的批大小等。具体实现细节参见下图:

3. GPT-3:《Language Models are Few-Shot Learners》
- 论文地址:https://arxiv.org/pdf/2005.14165.pdf
GPT-3 使用了和 GPT-2 相同的模型和架构,区别在于 GPT-3 在 transformer 的各层上都使用了交替密集和局部带状稀疏的注意力模式,类似于 Sparse Transformer。具体实现细节参见下图:

Andrej Karpathy 其人
Andrej Karpathy 是计算机视觉、生成式模型与强化学习领域的研究者,博士期间师从斯坦福大学计算机科学系教授李飞飞。读博期间,他曾两次在谷歌实习,研究在 Youtube 视频上的大规模特征学习。此外,他还和李飞飞等人一起设计、教授了斯坦福经典课程 CS231n。
2016 年,Karpathy 加入 OpenAI 担任研究科学家。2017 年,他加入特斯拉担任人工智能与自动驾驶视觉总监。如今,Karpathy 已经升任特斯拉 AI 高级总监。他所在的团队负责特斯拉自动驾驶系统 Autopilot 所有神经网络的设计,包括数据收集、神经网络训练及其在特斯拉定制芯片上的部署。
和教授 CS231n 时一样,Karpathy 希望他利用业余时间做的这个 minGPT 也能有一定的教育意义。他这种化繁为简的举动得到了众多社区成员的赞赏:
除了关于 minGPT 本身的讨论之外,还有人提出:有没有可能借助社区力量一起训练 GPT-3?也就是说,如果成千上万的开发者在 GPU 空闲的时候将其贡献出来(比如夜间),最后有没有可能训练出一个 1750 亿参数的 GPT-3?这样的话,大家只需要分摊电费就好了。

不过,有人指出,这种分布式训练的想法非常有趣,但可能会在梯度等方面遇到瓶颈。

还有人调侃说,把电费众筹一下拿来买云服务岂不是更简单?