工作中,频繁切换是件麻烦事儿。一些程序员只熟悉SQL中的数据操作,却不熟悉Python中的数据操作,因此在完成项目时,我们不得不频繁地在SQL和Python之间进行切换,导致了工作效率低下和生产能力下降。
本文就教你一种方法,使用Pandas在Python中轻松重现SQL结果。
入门指南
如果电脑中没有pandas包,则需要先安装一下:
- Conda install pandas
在这个阶段,我们将使用著名的Kaggle泰坦尼克数据集:https://www.kaggle.com/c/titanic/data?select=test.csv。
安装软件包并下载数据后,需要将其导入Python环境中:
- import pandas as pd
- titanic_df = pd.read_csv("titanic_test_data.csv")
我们将使用pandas数据框架来存储数据,还将用到各种pandas函数来操作数据框架。
- SELECT, DISTINCT, COUNT, LIMIT
让我们从经常使用的简单SQL查询开始。

titanic_df [“ age”]。unique()将在此处返回唯一值的数组,因此需要使用len()来获取唯一值的计数。
- SELECT,WHERE,OR,AND,IN(有条件选择)
现在你知道了如何以简单的方式探索数据框架,接着来尝试一些条件吧(在SQL中是WHERE子句)。

如果只想从数据框架中选择特定的列,则可以使用另一对方括号进行选择。注意,如果要选择多列,则需要在方括号内放置数组[“ name”,“ age”]。
isin()与SQL中的IN完全相同。要使用NOT IN,需要在Python中使用negation(〜)来获得相同的结果。
- GROUP BY,ORDER BY,COUNT
GROUP BY和ORDER BY也是用来探索数据的流行SQL,让我们在Python中尝试一下。

如果只想对COUNT进行排序,可以将布尔值传递给sort_values函数;如果想对多列进行排序,则必须将布尔数组传递给sort_values函数。sum()函数将提供数据框架中的所有聚合数值总和列,如果只需要特定列,则需要使用方括号指定列名。
- MIN,MAX,MEAN,MEDIAN
最后,来尝试一些常见的统计功能,这些功能对于数据探索非常重要。
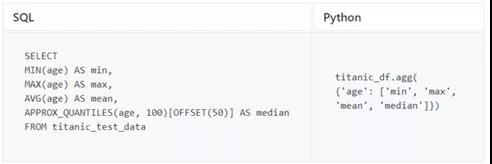
由于SQL没有中位数函数,因此将使用BigQuery APPROX_QUANTILES获取年龄中位数。pandas聚合函数.agg()还支持其他函数,例如sum。
拒绝频繁切换,轻松重现查询,你值得拥有!
你可以在我的Github中查看完整的脚本:https://github.com/chingjunetao/medium-article/tree/master/rewrite-sql-with-python
本文转载自微信公众号「读芯术」,可以通过以下二维码关注。转载本文请联系读芯术公众号。