













01 术语整理
本节概述机器学习及其三个分类(监督学习、非监督学习和强化学习)。首先,与机器学习相关的术语有人工智能(Artificial Intelligence,AI)、机器学习(Machine Learning,ML)、强化学习、深度学习等,这里对这些术语进行简单的整理。
AI意味着人工智能,其定义因研究人员而异。从广义上讲,它指“像人类一样具有智能的系统和配备这种系统的机器人”。实现AI的方法之一是机器学习。
机器学习可以简单地描述为“向系统提供数据(称为训练数据或学习数据)并通过数据自动确定系统的参数(变量值)”。相反,基于规则的系统是非机器学习系统的一个例子。在基于规则的系统中,由人类来清楚地定义分支条件的参数,例如实现代码中所存在的if语句等。
另一方面,机器学习自动根据训练数据确定代码中的参数,以使系统运行良好。之所以称为机器学习,正是因为系统能根据训练数据计算和确定系统运行所需的参数。
强化学习是机器学习中的一种。机器学习可分为三大类:监督学习、非监督学习和强化学习。我们稍后会讨论这三个分类,这里只需要认识到强化学习是机器学习的一部分即可。
接下来是深度学习。深度学习是实现机器学习的算法之一。机器学习的算法包括逻辑回归、支持向量机(Support Vector Machine,SVM)、决策树、随机森林和神经网络等。深度学习是神经网络中的一种。
最后是深度强化学习。深度强化学习是强化学习和深度学习的结合。
02 监督学习、非监督学习、强化学习
这里对三种机器学习(监督学习、非监督学习和强化学习)分别进行介绍。
首先说明监督学习。
例如,“对邮政编码中的手写数字进行分类”是一种监督学习。邮政编码分类系统将每个数字的手写图像分类为0~9中的一个。诸如0到9的数据的分类目标被称为标签或类。这种系统被称为监督学习,因为给事先提供的训练数据预先标记出了正确的标签。换句话说,带标签的训练数据成了系统的教师。
监督学习包括学习阶段和推理阶段。我们将以图为例来解释手写数字的分类(见图1.1)。
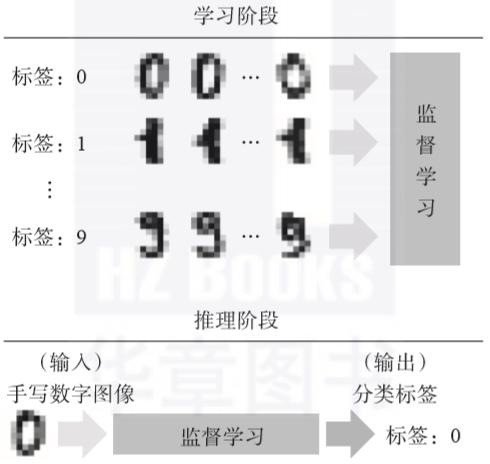
▲图1.1 使用监督学习区分手写数字的示例
在学习阶段,准备许多0到9的手写数字图像数据,这些数据作为训练数据。训练数据有一个标签(0到9中的某个数值),根据标签可以找到关于手写数字图像的正确答案信息,例如“此手写数字图像为1”。在学习阶段,当将手写数字图像输入系统时,调整(学习)系统的参数以尽量将输入图像分类为正确的标签。
在应用阶段,将无标签的未知手写数字图像数据输入系统,图像被分类为0到9中的某一个输出标签并给出结果。如果已经学习到正确的结果,当输入未知的手写数字图像时,系统将输出正确的数值标签。除了手写数字的分类之外,还可使用监督学习来对图像、声音和文本数据进行分类。
此外,除了上面例子中提到的分类任务,监督学习也用于回归等任务。
接下来,介绍非监督学习。用一个词表达非监督学习就是“分组”。它将大量数据中类似的数据分为一组(称为聚类)。例如,“根据购买数据对客户进行分组的系统”是非监督学习。根据购买历史记录的特征对客户进行分组,可以为每个组实施不同的销售策略。
我们使用图来说明购买数据分析的例子(见图1.2)。假设存储了每个客户过去一年的购买数量和每次平均消费金额的数据,并对此数据进行分析。根据这些数据,客户可以分为两组。A组(左上角)是以较低频次购买高价商品的组,B组(右下角)是多次重复但每次消费金额较低的组。
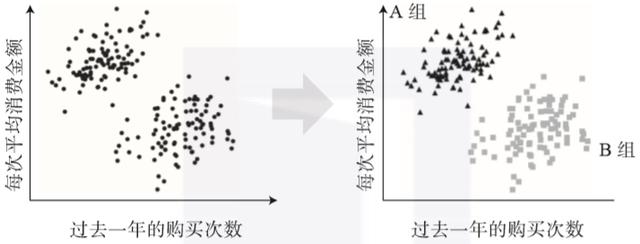
▲图1.2 使用非监督学习根据购买数据对客户分组的示例
使用非监督学习进行分组将有助于了解每个客户所属的组,并针对每个组实施优秀销售策略(尽管部分业务还需要更详细的分析)。除了本例中提到的分组(聚类)以外,非监督学习也用于降维和推荐系统。
最后,我们讨论强化学习。强化学习是一种主要用于“时变系统控制规则构建”和“对战博弈策略构建”的方法。例如,强化学习用于机器人的步行控制和围棋对战程序(见图1.3)。

▲图1.3 强化学习示例(机器人步行控制和围棋比赛系统)
在我们熟悉的例子中,可能更容易想象一个孩子学会骑自行车的情形。当一个孩子学习骑自行车时,并没有人去教其诸如牛顿力学等力学法则以及如何骑车的详细方法,也不必通过观看视频来学习骑自行车。事实上,自己尝试骑自行车,在多次失败的过程中找到一种骑自行车的方法。
强化学习正如学骑自行车的例子,它是一种学习方法,它在不知道控制对象的物理定律的情况下重复试错,以学习到所希望的控制方法。
强化学习中没有带标签的数据作为训练数据,但这并不意味着根本没有监督信息。系统根据强化学习程序运行,在获得所需结果时给出称为奖励的信号。例如,在机器人的步行控制中,可以走的距离就是奖励。在围棋的比赛程序中,赢或输的结果就是奖励。失败时的奖励是负值,也称为惩罚。
如果想通过监督学习来学习机器人的步行控制,就需要尽可能多的“如果腿的关节处于这个角度并且速度是某值,那么就像这样转动电动机A”这样的模式,并预先给出其正确的做法。然而,当机器人行走时,对于每个时刻变化的状态,很难预先给出控制该电动机的正确做法。
另一方面,在强化学习中,将行走距离作为奖励提供给步行控制系统,并且重复试验多次。
这样一来,强化学习系统会根据重复试验和获得的奖励自行改变控制规则,以“如果之前的试验中所做改变使我可以走得更远,则这种改变是正确的”为基础。因此,可以在不教导机器人如何行走的情况下让机器人能渐渐行走更长的距离。
即使在像围棋这样的对战游戏的策略构建中,也无须在每个阶段将强者视为教师数据来进行教导,仅通过将成功或失败作为奖励来重复试验即可。这样做,强化学习系统会一点一点地改变游戏方式并变得更强。
学到的围棋或将棋系统比设计者本人更强大,这一点通过强化学习可以很容易实现。只听这个解释,强化学习就像魔术,但在实践中却存在着种种困难。
强化学习主要适用于“时变系统控制规则构建”和“对战博弈策略构建”,本书以前者“系统控制”为目标任务,通过编写相关程序来学习强化学习。
























