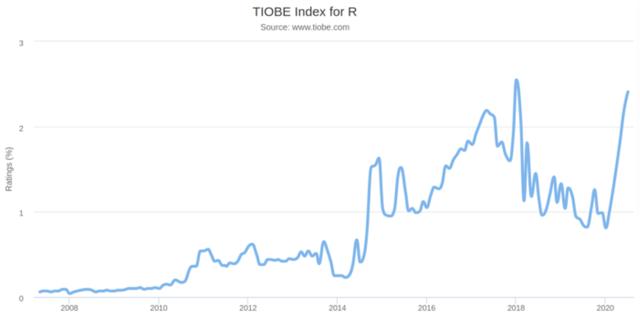
我们从下图可以看出 R 的 TIOBE 指数,在2018年1月达到峰值后,该语言开始出现显著下降。然而,自3月份以来,指数明显回升。
这是什么原因?
很明显是因为新冠病毒在全球爆发,而引发了大家对统计数据的兴趣。
因此,如果一个人想快速进行有效的统计分析,就应该寻求一个直观的统计环境来计算数据。而 R 在数据的统计分析中占主导地位。
下面是我对 R 如何优于 Python 的经验:
1.在分析时间序列数据时,R 可以优于 Python
如果你从事过时间序列分析,那么你可能很熟悉所谓的 ARIMA(自回归综合移动平均线)模型。
这是一个可以用来根据时间序列的结构进行预测的模型。ARIMA 模型由坐标(p、d、q)组成:
- p 代表自回归项的数量,即用于预测未来值的过去时间值的观察数。例如,如果 p 的值是2,那么这意味着序列中前两次时间观测值被用来预测未来的趋势。
- d 表示使时间序列平稳所需的差异数(即具有恒定均值、方差和自相关的差分)。例如,如果d=1,则意味着必须获得级数的第一个差分才能将其转换为平稳差。
- q 代表模型中先前预测误差的移动平均值,或误差项的滞后值。例如,如果 q 的值为1,那么这意味着我们在模型中有一个误差项的滞后值。
但是,R 和 Python 都允许基于最佳拟合自动选择这些坐标。可以使用 R 中的 auto.arima 和Python中的 pyramid 来完成。金字塔中的 auto-arima 函数是在原有的 R 函数的基础上发展起来的,即 R 是第一个能够自动选择 p、d、q 坐标的语言。
2.回归分析
对于回归分析,在某些情况下,与 Python 相比,R 可以使用更少的代码行来运行分析。
让我们举个例子。假设我们正在运行回归以基于各种因素来预测股票收益,例如公司股息、收益和债转股。
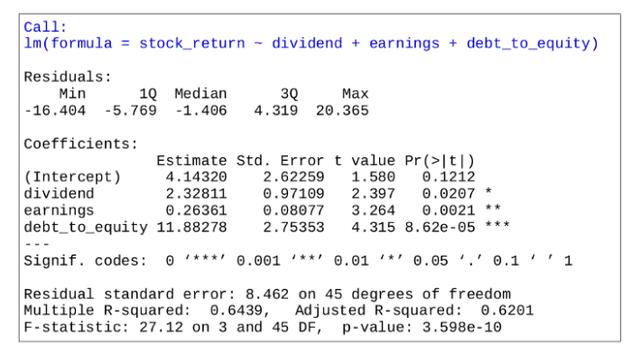
现在,假设我们希望测试多重共线性,即测试是否有任何自变量彼此显着相关,从而导致结果的偏差。 回归(reg1)运行如下:
现在,我们需要计算方差膨胀因子。 计算方法如下:
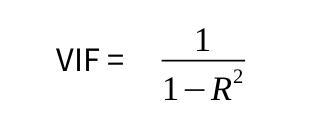
但是,我们不需要在 R 中手动计算该值。相反,可以使用 car 库,按如下所示调用 VIF 函数:

VIF 统计数据处于常用阈值5和10之下,这表明模型中不存在多重共线性。
但是,使用 Python 的过程要复杂一些。
使用 sklearn 时,我们将分别获得每个变量的 VIF。例如,让我们试着找到股息变量的 VIF 值。

在上述示例中,必须首先手动计算 R 平方统计,然后仅计算一个变量的 VIF 统计:

我们已经得到了这个变量的 VIF,但是为了达到这个目的还需要采取更多的步骤。此外,要找到其他两个变量的 VIF 值,必须对每个变量重复此过程。
从这个角度来看,R 仍然可以证明在快速生成统计信息时更直观。
3.直观的统计分析
Python中的 pyplot 和 seaborn 等库在生成统计图时已经变得非常流行。
但是,除了 shinny 的交互式可视化功能之外,R 的快速生成统计信息能力更加强大。
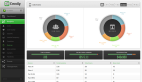
这是一个在 Shiny 中生成的累积二项式概率图的示例,可以通过操纵左侧的滑块(单个概率)来计算某个事件在指定次数的试验中发生的累积概率。
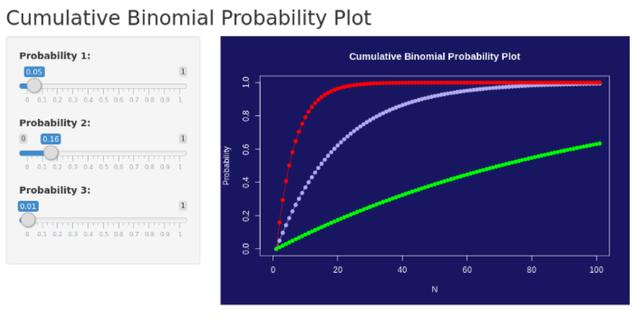
对于那些可能不擅长编写代码,但正在寻找一种有效的方式来操纵统计信息并快速产生洞察力的人来说,这种工具具有巨大的价值。 而且,Shiny 本身就是一个非常直观的 R 语言库,并不难学!
你可以直接在以下 GitHub 库中使用Shiny Web App:
- https://github.com/MGCodesandStats/shiny-web-apps/tree/master/probability
要运行该应用程序,只需:
- 下载资料库
- 单击 Shiny Web App 文件夹,然后在 RStudio 中打开 ui.R 和 server.R 文件。
- 完成此操作后,只需选择“运行应用程序”按钮,上面的应用程序就会显示:
总结
Python在机器学习方面表现出色,并且在通用编程方面将继续主导R。
从技术上讲,R 不是编程语言,而是一种统计环境。
但是,统计学作为一个领域将因为 R 语言而继续存在。