












在AI模型开发的过程中,许多开发者被不够充足的训练数据挡住了提升模型效果的脚步,一个拥有出色效果的深度学习模型,支撑它的通常是一个庞大的标注数据集。因此,提升模型的效果的通用方法是增加数据的数量和多样性。但在实践中,收集数目庞大的高质量数据并不容易,在某些特定领域与应用场景甚至难以获取大量数据。那么如何能在少量数据的情况下提升模型的效果呢?
随着深度学习的发展,数据增强技术可以协助开发者解决数据量不够充足的问题。数据增强技术通过对数据本身进行一定程度的扰动从而产生“新”数据,模型通过不断学习大量的“新”数据来提升泛化能力。
不同数据集的数据特性决定了其所适用的数据增强策略组合,在没有对数据特性有专业理解能力的情况下,用户很难构建出能与数据集特性强相关的数据增强策略组合。比如在标准的ImageNet数据预处理流程中有使用Random Crop (随机剪裁)、Random Flip (随机翻转) 等数据增强技术,取得了不错的效果增益,但在某些特定用户场景(如零售场景SKU抠图场景)数据边缘存在重要信息时Random Crop会导致信息的损失、在某些特定用户场景(如数字识别)时Random Flip会导致特征的混淆。因此如何根据数据特征来自动化搜索数据增强策略组合成为了一个热门的研究方向。
追溯学术界对自动数据增强领域的研究,最具影响力的一篇论文是Google在2018年提出的AutoAugment技术。随后,相关的优化论文层出不穷,简单梳理依据现有方法的一些建模思想,如图1。
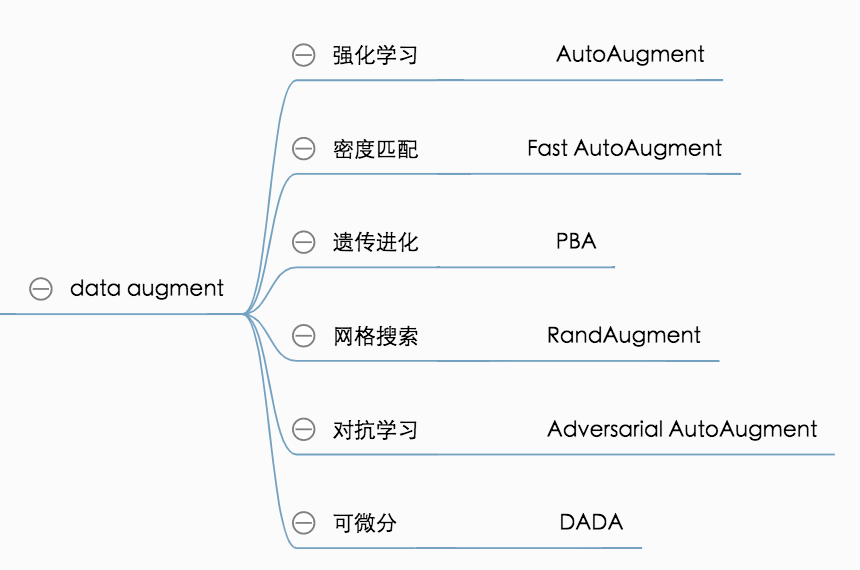
图1 自动数据增强算法建模思路归类
1)强化学习: AutoAugment [1] 借鉴了基于强化学习的架构搜索算法,在离散化的搜索空间内通过PPO (Proximal Policy Optimization)算法来训练一个policy generator, policy generator的奖励信号是其生成的policy应用于子网络训练完毕后的验证集准确率。其问题在于AutoAugment的搜索成本非常高,还无法满足工业界的业务需求,难以应用在业务模型开发中。
2)密度匹配: Fast AutoAugment [2] 采用了密度匹配的策略,希望验证数据通过数据增强后的数据点能与原始训练数据集的分布尽量匹配。这个思路直觉上可以排除一些导致数据集畸变的增强策略,但没有解决“如何寻找最优策略”这一问题。
3)遗传进化: PBA [3] 采用了PBT的遗传进化策略,在多个网络的并发训练中不断“利用”和“扰动”网络的权重,以期获得最优的数据增强调度策略。这个思路直觉上是可以通过优胜劣汰来搜索到最优策略。
4)网格搜索: RandAugment [4] 通过统一的强度和概率参数来大幅减小搜索空间,期望能用网格搜索就解决数据增强搜索的问题。但这一技术并不具备策略的可解释性,抛开实现手段不谈,这篇论文更像是对AutoAugment的自我否定(注: RandAugment也是Google出品的论文)。
5)对抗学习: Adversarial AutoAugment [5] 在AutoAugment的基础上借鉴了GAN的对抗思想,让policy generator不断产生难样本,并且使policy generator和分类器能并行训练,降低了搜索时长。但整体搜索成本还是非常高。
6)可微分: DADA[6]借鉴了DARTS的算法设计思路,将离散的参数空间通过Gumbel-Softmax重参数化成了可微分的参数优化问题,大大降低了搜索成本。
在上述的建模思路中,遗传进化和可微分的建模思路更适合应用到模型开发中,因为这两种思路将自动数据增强搜索的成本降低到了线上业务承受的资源范围内,并且具备较好的策略可解释性。基于对建模思路的评估和判断,百度工程师决定将遗传进化和可微分思路应用到零门槛AI开发平台EasyDL中,便于开发者进一步优化模型效果。
EasyDL面向企业开发者提供智能标注、模型训练、服务部署等全流程功能,针对AI模型开发过程中繁杂的工作,提供便捷高效的平台化解决方案,并且内置了丰富的预训练模型与优化的多种算法网络,用户可在少量业务数据上获得高精度的模型效果。EasyDL面向不同人群提供了经典版、专业版、行业版三种产品形态。
目前,遗传进化PBA技术已经在EasyDL平台中的成功实现,可微分的技术思路在EasyDL业务中的实践也在持续探索中。
PBA采用了PBT [7]的遗传进化策略,通过训练一群神经网络(种群, Trials)来找出超参数调度。Trials之间会周期性地将高性能Trial的权重复制给低性能的Trial(exploit),并且会有一定的超参扰乱策略(explore),如图2的PBT流程图。
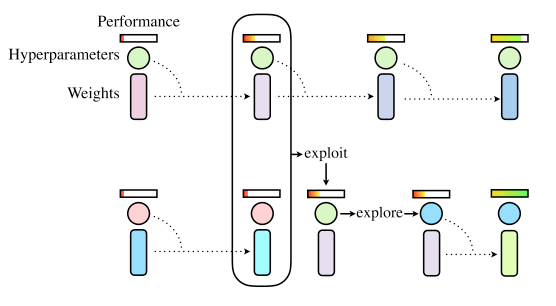
图2 PBT算法流程图
然而实际将能力落地到平台中并不容易,工程师们在复现论文开源代码的过程中发现了一些问题:
1)开源代码采用了Ray的Population Based Training实现,但这个接口并不能保证并行的Trials一定能实现同步的exploit, 尤其在资源受限的情况下,很大概率会出现进化程度较高的Trial和进化程度较低的Trial之间的exploit,这样的错误进化是不可接受的。
2)开源代码仅实现了单机多卡版本的搜索能力,想扩展到多机多卡能力,需要基于Ray做二次开发。
3)开源代码仅实现了图像分类的自动数据增强搜索,并未提供物体检测等其他任务的数据增强搜索能力。
4)开源代码现有增强算子实现方式比较低效。
综合以上考虑,最终百度工程师从零开始构建了基于PBA的自动数据增强搜索服务。
这一自研自动数据增强搜索服务有以下几个特点:
- 实现了标准的PBT算法,支持种群Trials的同步exploit、explore,保证公平进化。
- 支持分布式拓展,可不受限的灵活调节并发种群数,支持。
- 搜索服务与任务解耦,已支持飞桨深度学习平台的图像分类、物体检测任务,并且可扩展到其他的视觉任务与文本任务。
- 数据增强算子基于C++高效实现。
自研的能力效果如何呢?在公开数据集上,百度工程师基于自研的自动数据增强搜索服务与现有的Benchmark进行了对齐,其中表一的ImageNet Benchmark在PaddleClas[8]框架上训练,表二的Coco Benchmark在PaddleDetection [9]框架上训练。
结果显示,EasyDL自动数据增强服务能达到与AutoAugment同样高的精度,并有大幅的速度优势。目前,用于数据增强搜索的分类、检测算子已经与AutoAugment对齐,后续将会持续不断扩充更多更高效的算子,进一步提升模型效果。
|
模型 |
数据变化策略 |
TOP1 Acc |
数据增强策略搜索时长(GPU hours) |
|
ResNet50 |
标准变换 |
0.7731 |
\ |
|
AutoAugment |
0.7795 |
15000[1](P100) |
|
|
EasyDL自动数据增强服务 |
0.7796 |
45(V100) |
|
|
MobileNetV3_ small_x1_0 |
标准变换 |
0.682 |
\ |
|
EasyDL自动数据增强服务 |
0.68679 |
28(V100) |
表一 ImageNet Benchmark [8]
|
模型 |
数据变化策略 |
Box AP |
增强策略搜索时长(GPU hours) |
|
Faster_RCNN_R50_ VD_FPN_3x |
AutoAugment |
39.9 |
48*400[10](TPU) |
|
EasyDL自动数据增强服务 |
39.3 |
90(V100) |
表二 Coco Benchmark [9]
EasyDL目前已在经典版上线了手动数据增强服务,在专业版上线了自动数据增强搜索服务。在图像分类单标签的任务上,工程师随机挑选了11个线上任务进行效果评测。如下图,使用专业版自动数据增强服务后,11个任务准确率平均提长了5.42%, 最高一项任务获得了18.13%的效果提升。
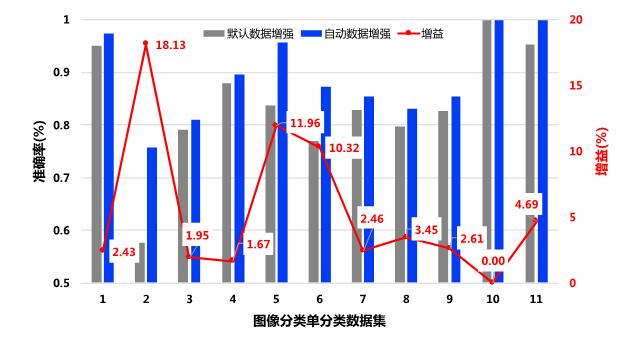
图3 图像分类单分类效果评测
在物体检测任务上,通过随机挑选的12个线上任务进行了效果评测,效果对比如下图,使用专业版自动数据增强服务后11个任务准确率平均提升了1.4%, 最高一项任务获得了4.2%的效果提升。
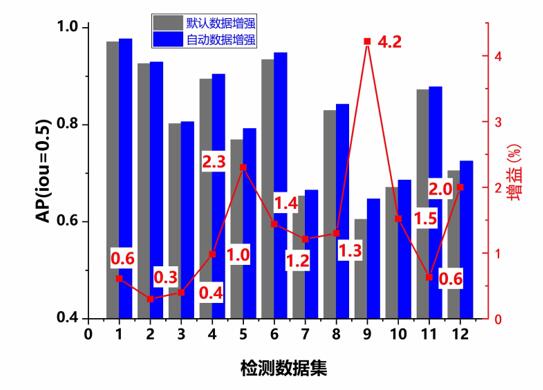
图4 物体检测效果评测
EasyDL平台通过交互式的界面,为用户提供简单易上手的操作体验。同样,使用EasyDL的数据增强服务操作非常简便。
目前,由于训练环境的资源消耗不同,EasyDL经典版与专业版提供两种数据增强策略。
在经典版中,已经上线了手动配置数字增强策略。如图5,用户可以在训练模型页面选择“手动配置”,实现数据增强算子的使用。
在专业版中,由于提供训练环境的多种选择,目前已支持自动搜索策略。如图6,在新建任务页面的“数据增强策略”中选择“自动搜索”,再设置需要搜索的算子范围,即可立刻实现自动数据增强。
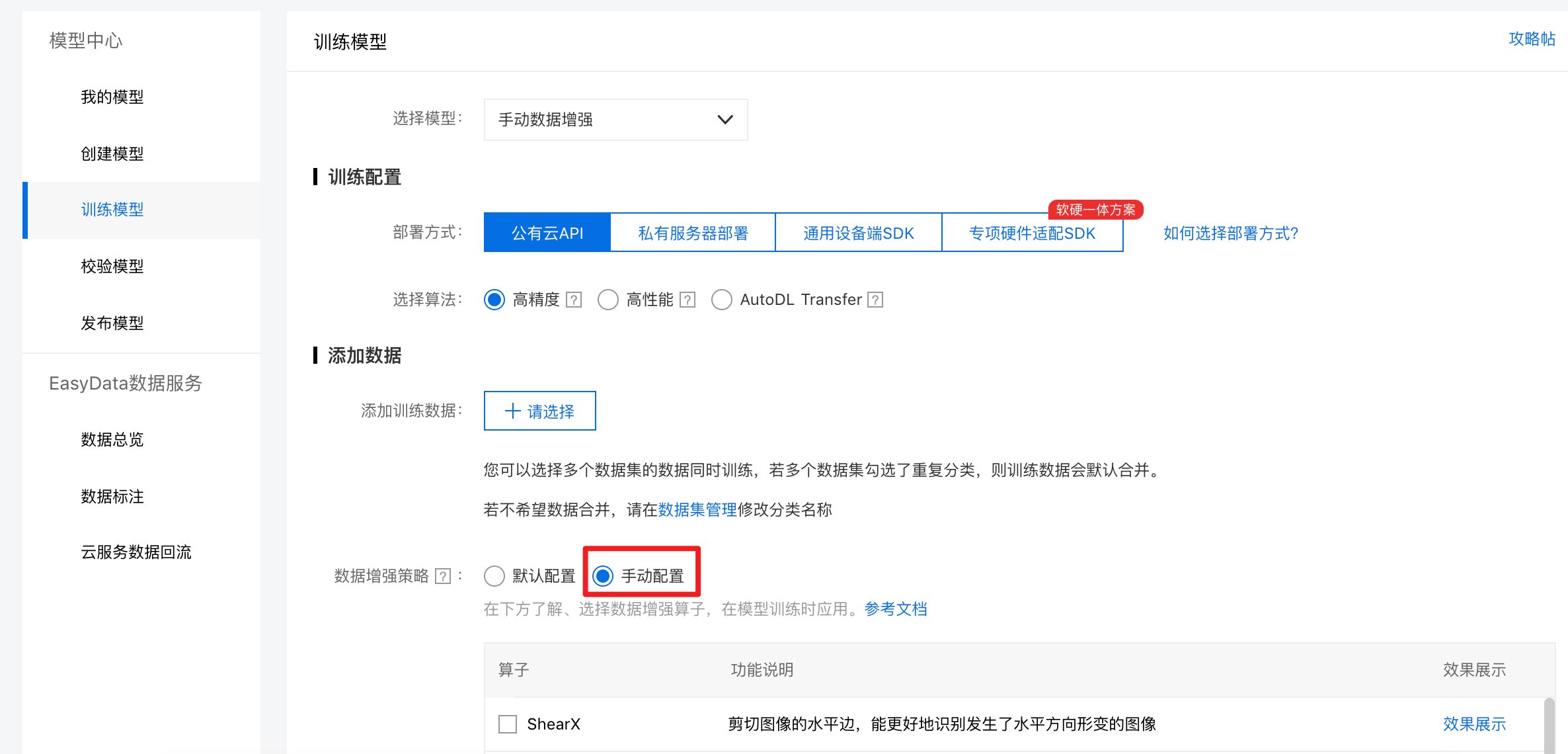
图5 经典版手动数据增强使用流程
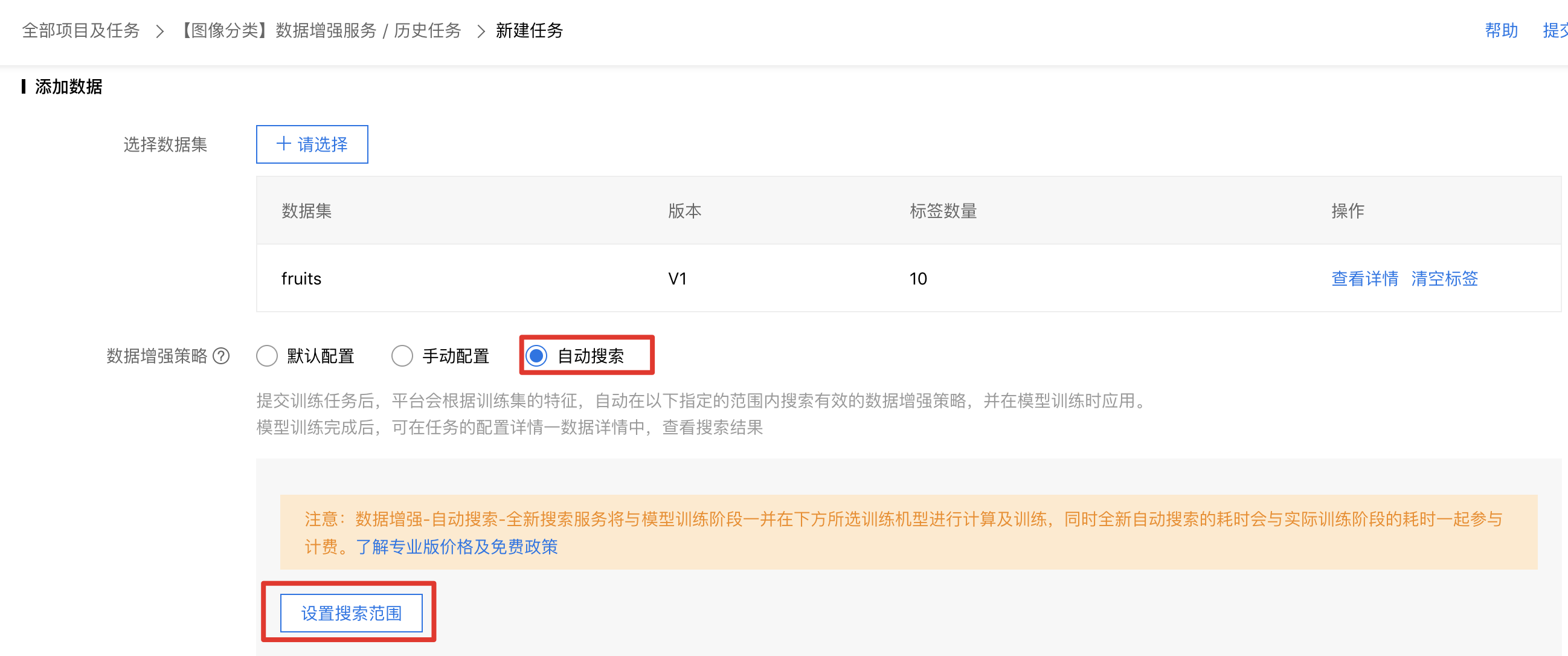
图6 专业版自动数据增强使用流程
为了让开发者使用EasyDL更便捷高效地开发效果出色的模型,EasyDL在框架设计中内置了多个组件与多种能力。如EasyDL智能搜索服务的整体架构图(图7)所示,其底层基础组件是分布式智能搜索,具备多机多卡搜索、训练容错、支持多种搜索优化算法等特性。基于分布式智能搜索提供的核心能力,产品构建了自动数据增强搜索、超参搜索、NAS搜索等服务,尽可能让用户可以在无需关心技术细节的情况下,简便使用EasyDL提供的多项搜索服务,获得模型效果的优化。
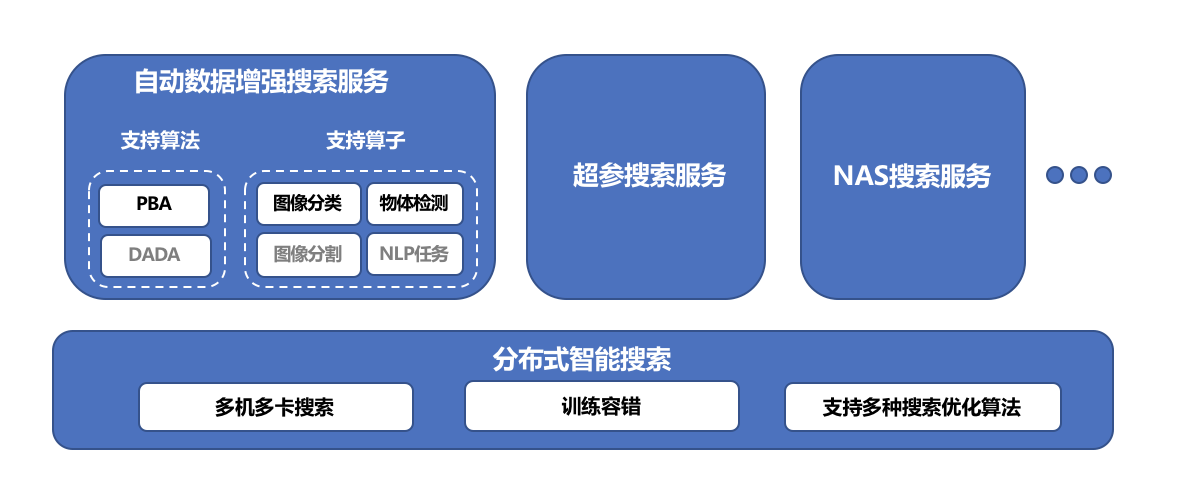
图7 EasyDL智能搜索服务整体架构图
在各行各业加速拥抱AI的今天,有越来越多的企业踏上智能化转型之路,借助AI能力完成降本增效。但在AI赋能产业的过程中,大规模的商业化落地十分复杂,需要企业投入大量的精力。由于不同行业、场景存在着差异化与碎片化,对AI的需求也不尽相同。因此,一个能够随场景变化定制开发AI模型的平台至关重要。通过零算法门槛的平台能力覆盖千变万化的场景需求,并提供灵活适应具体业务的多种部署方式,这就是EasyDL。
EasyDL零门槛AI开发平台,目前已在工业制造、智能安防、零售快消、交通运输、互联网、教育培训等行业广泛落地。
同时,除了零门槛AI开发平台EasyDL,百度也推出了全功能AI开发平台BML,面向企业数据科学家和算法工程师团队,提供功能全面、可灵活定制和被深度集成的机器学习开发平台。
百度搜索“EasyDL”或访问链接,开发高精度AI模型。https://ai.baidu.com/easydl/
[1]:Cubuk E D, Zoph B, Mane D, et al. Autoaugment: Learning augmentation policies from data[J]. arXiv preprint arXiv:1805.09501, 2018.
[2]:Lim S, Kim I, Kim T, et al. Fast autoaugment[C]//Advances in Neural Information Processing Systems. 2019: 6665-6675.
[3]:Ho D, Liang E, Chen X, et al. Population based augmentation: Efficient learning of augmentation policy schedules[C]//International Conference on Machine Learning. 2019: 2731-2741.
[4]:Cubuk E D, Zoph B, Shlens J, et al. Randaugment: Practical automated data augmentation with a reduced search space[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 2020: 702-703.
[5]:Zhang X, Wang Q, Zhang J, et al. Adversarial autoaugment[J]. arXiv preprint arXiv:1912.11188, 2019.
[6]:Li Y, Hu G, Wang Y, et al. DADA: Differentiable Automatic Data Augmentation[J]. arXiv preprint arXiv:2003.03780, 2020.
[7]:Jaderberg M, Dalibard V, Osindero S, et al. Population based training of neural networks[J]. arXiv preprint arXiv:1711.09846, 2017.
[8]:https://paddleclas.readthedocs.io/zh_CN/latest/advanced_tutorials/image_augmentation/ImageAugment.html#id6
[9]:https://github.com/PaddlePaddle/PaddleDetection/tree/master/configs/autoaugment
[10]: Zoph B, Cubuk E D, Ghiasi G, et al. Learning data augmentation strategies for object detection[J]. arXiv preprint arXiv:1906.11172, 2019.
















