正文开始
在前面的这篇文章中 —— 优秀的程序员是如何利用工具来提升工作效率的?,石头介绍了可以提高程序猿工作效率的一些软件和工具及相关配置。文中提到了, 程序猿应该了解一些常见的命令行工具来提高效率。
本文是一个命令行工具的综合应用,将用一个具体的例子来阐述如何用 Shell 来进行高效地数据统计和分析。最近北京又开始了新一批积分落户的填报工作,恰好这篇文章用 shell 来对首批北京积分落户同学进行 "大数据"分析。
现如今到处都是各种"大数据",本文分析对象也就是首批积分落户的6000多条数据而已,显然不能算什么大数据。
印象中,我记得当初该官网的这6000多条数据也是一次性就能wget下来的(后端估计没做限制,可能稍微调整下接口的分页参数之类不需要严格按照各种分页多次下载)。(注:本文旧文重新整理发送。)
问题描述
输入是 json数据,格式化之后的 json 数据主题结构如下所示,rows为数组,数组中元素所代表的 object 即描述了获得北京户口的同学的各种属性:例如分数、排名、身份证号(后四位打码了)、公司等等信息。为了方便大家练习对数据进行试验,我将文中的数据附在这里(https://www.tanglei.name/resources/use-shell-to-analysis-the-first-people-of-getting-residence-of-beijing-by-score/jifenluohu.json.gz)。
"rows": [
{
"id": 62981,
"idCard": "32092219721222****",
"idCardSHA": "9ef70bde894959a4e4a1d1b2b9592b470294f9e4012a8cf480319665d1a7c1c6",
"insertTime": 1539518353000,
"integralQualified": 1,
"internetAnnual": {
"annual": 2018,
"id": 43,
"insertTime": 1539518353000,
"publicityEnd": 1540224000000,
"publicityStart": 1539591600000,
"publishResultEndDate": 1541679300000,
"publishResultStartDate": 1539591600000,
"publishResultStatus": 1,
"score": 90.75,
"status": 1
},
"md5Code": "54e9ff7ce0b004f7141b157f8afc66db",
"name": "杨效丰",
"pxid": 1,
"ranking": 1,
"s1": 51,
"s10": 0,
"s2": 12.59,
"s3": 15,
"s4": 0,
"s5": 4,
"s6": 0,
"s7": 20,
"s8": 20,
"s9": 0,
"score": 122.59,
"unit": "北京利德华福电气技术有限公司"
},
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
拿到这个文件,比如希望你用最快的方法获得以下信息,你将会怎么做?
- 获取取得户口名额最多的top10公司
- 获取取得户口名额的人中姓氏最多的
- 获取户口名字中叫啥名最流行
- 获取年龄分布
- 获取取得户口的同学户籍地top10
- 生肖/星座/生日...
当然,方法有很多,比如熟悉各种编程语言的,例如 python, php, java 等等写个简单的脚本程序,也能比较快获取答案。或者把相应的数据提取出来,放到 excel 中也可以。
如果你对 Shell 很熟悉,那真的是分分钟,应该是秒秒钟就能获取答案。就算用 Shell 来实现,不同的人可能也有不同的写法,后面我就列举其中的一种来解决这些问题。
本文不对 Shell 具体每个命令做过多的解释,不熟悉的同学可以直接 man $cmd 或者 $cmd --help 等等查看。
之前我也写过一篇名叫 Shell 助力开发效率提升 的文章,算是给常用的命令的常用参数做了一个解释和示例,有兴趣的同学可以前往查阅。
问题解答
获取取得户口名额最多的top10公司
看看想通过积分落户,最好是进哪些公司,哈哈。
"unit": "北京利德华福电气技术有限公司"
先通过 grep 得到包含公司名字的一行,然后通过 ":" 分割 cut 取第2列得到公司名字,对结果进行sort排序进行去重uniq统计得到重复次数,次时结果为重复次数 公司名,再对第一列-k 1重复数字进行按照数字排序逆序-nr 即 sort -nr -k 1,最后取结果的前10行 head -n 10。
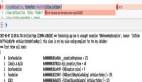
➜ 积分落户 > grep 'unit' jifenluohu.json| cut -f2 -d: | sort | uniq -c | sort -nr -k 1 | head -n 10
137 "北京华为数字技术有限公司"
73 "中央电视台"
57 "北京首钢建设集团有限公司"
55 "百度在线网络技术(北京)有限公司"
48 "联想(北京)有限公司"
40 "北京外企人力资源服务有限公司"
40 "中国民生银行股份有限公司"
39 "国际商业机器(中国)投资有限公司"
29 "中国国际技术智力合作有限公司"
27 "华为技术有限公司北京研究所"
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
获取取得户口名额的人中姓氏最多的
看看想通过积分落户,最好是姓啥,哈哈。
"name": "杨效丰",
套路跟之前差不多的,我这边就不特别指出了。
下面shell实际上是取到这行后,将真正表示名字之前的所有字符都删除,就只剩下名字开头了,取行首第一个字符cut -c 1即得到姓,再按照之前的套路就能拿到了。
其实用什么sed替换冗余的字符都是多余的,因为json的格式都是良好的,可以直接通过 cut -c ? 取姓这个字符即可。
也不用挨个去数到底是第几个字符,直接 copy出来,然后 echo -n $paste | wc -c 就能数到第几个字符了。
看结果还是姓 "张, 王" 之类的最有戏。??
# 或者 grep '"name":' jifenluohu.json| sed 's|"name": "||g' | sed 's|[[:space:]]||g' | cut -c 1 | sort | uniq -c | sort -nr -k 1 | head -n 10
➜ 积分落户 > grep '"name":' jifenluohu.json| sed 's|"name": "||g' | sed 's| ||g' | cut -c 1 | sort | uniq -c | sort -nr -k 1 | head -n 10
541 张
531 王
462 李
376 刘
205 陈
193 杨
166 赵
132 孙
95 郭
95 徐
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
获取户口名字中叫啥名最流行
套路差不多,不做过多解释了。
➜ 积分落户 > grep '"name":' jifenluohu.json| sed 's|"name": "||g' | sed 's|[[:space:]]||g' | cut -c 2-4 | sort | uniq -c | sort -nr -k 1 | head -n 10
51 伟",
39 静",
38 涛",
36 勇",
36 军",
32 敏",
31 颖",
30 鹏",
28 杰",
28 峰",
# 取名字, 必须包含2个字
➜ 积分落户 > grep '"name":' jifenluohu.json| sed 's|"name": "||g' | sed 's|[[:space:]]||g' | cut -c 2-3 | sed '/"/d' | sort | uniq -c | sort -nr -k 1 | head -n 10
19 海涛
19 晓东
12 志强
11 海燕
11 永强
11 建华
10 雪梅
9 海龙
9 丽娜
8 洪涛
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
作为码农,必须得养成对自己得到结果进行自测的习惯,所以如果对自己的结果不够自信,可以正向去计算一下最终的结果。
例如可以简单grep一下进行验证,叫 "海涛" 的是不是19个。
➜ 积分落户 > grep '海涛' jifenluohu.json | wc -l
19
- 1.
- 2.
获取年龄分布
思路是截取身份证中号码中代表出生年的4位数,然后拿当前年份2019减出生年得到年龄,后面的套路又一样了。
bc 一个简单的计算器程序,了解下?
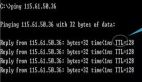
➜ shell-train > echo "3+2-5/5" | bc
4
➜ shell-train > echo "3.141592*5-4" | bc
11.707960
#思路1: `cut -c 9-12` 获取出生年, 拼接表达式 `2019-出生年` 得到年龄.
➜ 积分落户 > grep '"idCard":' jifenluohu.json| cut -f2 -d: | cut -c 9-12 | xargs -n1 echo 2019 -|bc | sort | uniq -c
3 34
13 35
39 36
109 37
162 38
302 39
507 40
773 41
799 42
813 43
757 44
586 45
507 46
378 47
238 48
4 49
9 50
1 51
4 52
3 53
2 54
5 55
1 56
1 58
1 59
1 60
1 61
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
awk 是个好东西, 多练练.
# 拿到出生年后, 直接通过 awk 计算结果输出
➜ 积分落户 > grep '"idCard":' jifenluohu.json| cut -f2 -d: | cut -c 9-12 |awk '{print 2019-$1}' | sort | uniq -c
3 34
13 35
39 36
109 37
162 38
302 39
507 40
773 41
799 42
813 43
757 44
586 45
507 46
378 47
238 48
4 49
9 50
1 51
4 52
3 53
2 54
5 55
1 56
1 58
1 59
1 60
1 61
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
获取取得户口的同学户籍地top10
有时候,我们在写Shell的时候,为了debug方便,可能会将一些中间结果缓存到文件中,后续以该文件为基础进行后续的计算。
比如先拿到top10的身份证中代表的户籍地的四位编码,这里需要借助另外的一个表示身份证户籍地的编码来进行对应。
借此机会解释下 join 这个命令。
# 身份证前4位为例, 拿到户籍地
grep '"idCard":' jifenluohu.json| cut -f2 -d: | cut -c 3-6 | sort | uniq -c | sort -nr -k 1 >topcity.code
# 城市列表
➜ 积分落户 > more city.csv
11,北京市
1101,北京市市辖区
110101,北京市东城区
110102,北京市西城区
110103,北京市崇文区
110104,北京市宣武区
110105,北京市朝阳区
# grep -E '^[0-9]{4},' city.csv | sed 's|,| |g' > city.code4
➜ shell-train > head -n 2 city.code4
1101 北京市市辖区
1102 北京市市辖县
➜ shell-train > head -n 2 topcity.code
197 1201
156 1302
➜ shell-train > join
usage: join [-a fileno | -v fileno ] [-e string] [-1 field] [-2 field]
[-o list] [-t char] file1 file2
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
其实,join 就类似sql中的 ...inner join ...on ..., -t 分隔符,默认为空格或tab。
# 未排序, 所以没有将所有的导出(join需要排序)
➜ shell-train > join -1 1 -2 2 city.code4 topcity.code
1201 天津市市辖区 197
1302 河北省唐山市 156
2301 黑龙江哈尔滨市 123
4201 湖北省武汉市 118
6101 陕西省西安市 100
6201 甘肃省兰州市 59
6501 新疆乌鲁木齐市 29
6523 新疆昌吉回族自治州 11
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
一定需要将结果输出到文件,然后再进行吗?
其实也不一定。用管道的方式 | 可以将上一个命令的输出结果作为下一个命令的输入,可以通过 <(command) 的方式,将command 的输出作为一个文件输入。
# 需要排序
➜ shell-train > join -1 1 -2 2 city.code4 <(head -n 10 topcity.code | sort -k 2)
1201 天津市市辖区 197
1301 河北省石家庄市 114
1302 河北省唐山市 156
1324 河北省保定地区 103
1501 内蒙古呼和浩特市 88
2101 辽宁省沈阳市 109
2201 吉林省长春市 113
2301 黑龙江哈尔滨市 123
4201 湖北省武汉市 118
6101 陕西省西安市 100
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
举个例子paste用来将两个文件按列合并在一起:
➜ shell-train > cat paste.f1
hello, i am
world, you are
➜ shell-train > cat paste.f2
tanglei, wechat is: tangleithu
?, hahaha
➜ shell-train > paste paste.f1 paste.f2
hello, i am tanglei, wechat is: tangleithu
world, you are ?, hahaha
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
以上用paste将两个文件合并在一起了,实际上通过 <(cmd)的方式,可以不借助外部文件也能做到。
方法如下:
➜ shell-train > paste <(echo "hello, i am \nworld, you are") <(echo "tanglei, wechat is: tangleithu\n?, hahaha")
hello, i am tanglei, wechat is: tangleithu
world, you are ?, hahaha
- 1.
- 2.
- 3.
本文转载自微信公众号「程序猿石头」,可以通过以下二维码关注。转载本文请联系程序猿石头公众号。