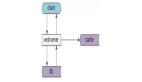
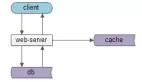
下图是一个典型的,互联网分层架构:
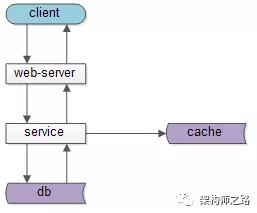
- 客户端层:典型调用方是浏览器browser或者手机APP
- 站点应用层:实现核心业务逻辑,从下游获取数据,对上游返回html或者json
- 服务层:业务服务,数据服务,基础服务,对上游提供友好的RPC接口
- 数据缓存层:缓存加速访问存储
- 数据固化层:数据库固化数据存储
同一个层次的内部,例如端上的APP,以及web-server,也都会进行MVC分层:
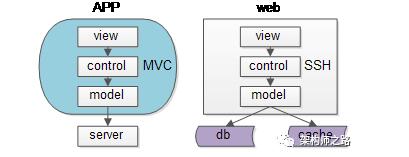
- view层:展现
- control层:逻辑
- model层:数据
工程师骨子里,都潜移默化的实施着分层架构设计。
互联网分层架构的本质究竟是什么呢?
如果我们仔细思考会发现,不管是跨进程的分层架构,还是进程内的MVC分层,都是一个“数据移动”,然后“被处理”和“被呈现”的过程。
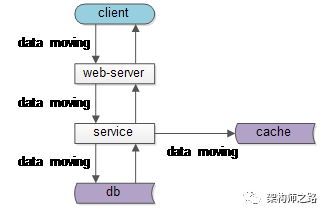
如上图所示:数据处理和呈现,需要CPU计算,而CPU是固定不动的:
- db/service/web-server都部署在固定的集群上
- 端上,不管是browser还是APP,也有固定的CPU处理
而数据是移动的:
- 跨进程的:数据从数据库和缓存里,转移到service层,到web-server层,到client层
- 同进程的:数据从model层,转移到control层,转移到view层
归根结底一句话:互联网分层架构,是一个CPU固定,数据移动的架构。
MapReduce的架构,是不是也遵循这个架构特点呢?
假如MapReduce也使用类似的的分层架构模式:
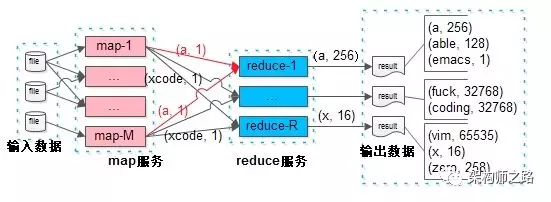
提前部署服务:
- map服务层:接收输入数据,产出“分”的数据,集群部署M=1W个实例
- reduce服务层:接受“合”的数据,产出最终数据,集群部署R=1W个实例
当用户提交作业时:
- 把数据数据传输给map服务集群;
- map服务集群产出结果后,把数据传输给reduce服务集群;
- reduce服务集群把结果传输给用户;
存在什么问题?
将有大量的时间浪费在大量数据的网络传输上。
画外音:输入给map,map给reduce,reduce给用户。
会发现,“固定CPU,移动数据”的架构并不适合。
Google MapReduce工程架构是如何思考这一个问题的呢?
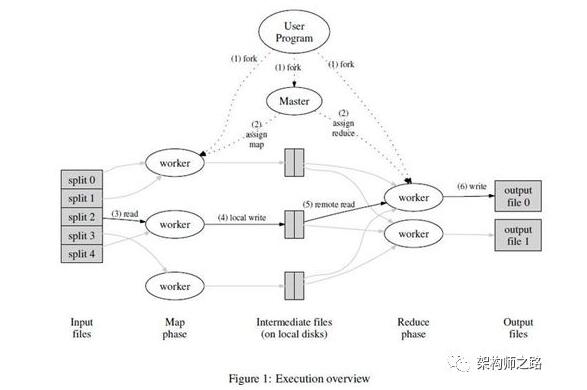
为了减少数据量的传输:
(1) 输入数据,被分割为M块后,master会尽量将执行map函数的worker实例,启动在输入数据所在的服务器上;
画外音:不需要网络传输了。
(2) map函数的worker实例输出的的结果,会被分区函数划分成R块,写到worker实例所在的本地磁盘;
画外音:不需要网络传输了。
(3) reduce函数,由于有M个输入数据源(M个map的输出都有一部分数据可能对应到一个reduce的输入数据),所以,master会尽量将执行reduce函数的worker实例,启动在离这些输入数据源尽可能“近”的服务器上;
- 画外音:目的也是最小化网络传输;
- 服务器之间的“近”,可以用内网IP地址的相似度衡量。
所以,对于MapReduce系统架构,“固定数据,移动CPU”更为合理。
这是为什么呢?
互联网在线业务的特点是:
- 总数据量大
- 吞吐量比较大,同时发起的请求多
- 每个请求,处理的数据相对比较小
- 用户对处理时延比较敏感
这类业务,使用“固定CPU,移动数据”的分层架构是合理的。
MapReduce离线业务的特点是:
- 吞吐量比较小,同时发起的任务比较少
- 每个任务,处理的数据量非常大
- 用户对处理时延容忍性大
这类业务,使用“固定数据,移动CPU”的分层架构是合理的。
任何脱离业务的架构设计,都是耍流氓。
思考问题的本质,希望大家有收获。
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】