












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
今天很高兴能够与大家分享矩阵元最近的一些研究成果。主要的方向是隐私计算,以及基于密码学的隐私开源框架—Rosetta。
隐私计算时代来临?
目前数据面临着一些挑战。随着数字化的发展,数据量指数级增加,一些核心的、关键的数据保护做得远远不够。目前来看,随着数据的生产要素化,不论国内国外对整个数据相关方向的关注程度越来越高,当然其中也有越来越多的挑战。而众多挑战之中我们认为其中最关键的一点就是数据隐私。
从AI的角度来看,AI需要用数据来“喂”,只有通过足够多的数据或多样化的数据,才能训练出一个相对较好的模型使用。所以随着数据量的增大、数据多样化的增加,以及随着数据隐私的关注程度越来越高,AI面临着一个所谓的“窘境”——从AI角度来看,数据的多样化程度越高,对于整个模型的训练更有好处,模型精度也会相应提高。
所以这给AI带来了一系列问题。如何能够在保护数据隐私的前提下,把各不同源、不同企业之间的数据能够融合运用?在目前传统的技术方法里很难解决这个问题,所以成为了AI可能面临的一大痛点。因此也引出了“隐私计算”的概念。
关于隐私计算,简单来说就是保证数据在使用和融合过程中,保护隐私的综合性技术,而不是简单的一项技术。隐私计算大致分为三类:
第一是密码学,第二是联邦学习(Federated Learning),是偏机器学习的技术;第三是可信执行环境(TEE),是硬件安全的技术。当然技术没有绝对的好坏之分,每个技术都有它的优势和劣势,所以在很多的综合性解决方案中,很多技术都是融合在一起使用的。
密码学简单来说是研究各类不同情况下,如何保护数据隐私的一类学科。最主要的特点是:所有密码学的方向,在涉及算法、方案的时候,要先去定义一个安全模型,要定义什么样才是安全。之后在这个定义之下,会通过一些数学的方法技巧去证明这个方案是满足安全定义的,所以它相对来说具有完整的数学理论基础的密码理论。当然它的优势是,密码学考虑的是一个非常广泛的场景。所以它能够更好的适合或适配不同的场景。在某些场景下,能够做到比较高效。
当然密码学也有瓶颈,在部分场景里性能、计算时间、通讯复杂度存在一定的瓶颈。当然更大的瓶颈在于,给没有密码学背景的人解释密码学原理,是一件难于上青天的事情。
所以本次分享中,会更倾向于密码学的介绍,包括密码学的历史及主要技术,之后我会对其中的安全多方计算的基本原理做一些简单的介绍。
密码学如何实现隐私保护?
密码学中的隐私计算技术,大概分为三大类。分别是:安全多方计算、同态加密、零知识证明。
安全多方计算(简称MPC),在1982年由姚期智先生提出,缘起于“百万富翁问题”。此问题讲的是有两个百万富翁,他们都很有钱,想比谁更有钱,但是又不想把各自的资产告诉对方,也不想找第三方帮他们做比较。所以他们如何能够在不泄露自己财产的前提之下,知道谁更有钱呢?安全多方计算领域由此开辟。
抽象的来说,可以理解为有多个本地参与,他们各自都拥有一个隐私的收入,但是他们想去计算一个共同的函数或者说共同的模型,叫做f。这个f会跟各自的输入都有关系,然后各自拿到一个结果。所以我们把它抽象出来,如果f是一个比较的函数,模型里面只有两个人的话,就形成了一个经典的百万富翁问题。
和我们今天讲的内容联系起来呢?如果这个f是一个模型或是机器学习的模型,比如说是一个逻辑回归、是一个CNN,相当于这三方各自都拥有一些数据,他们想共同训练这个模型。
这就对应了今日主题:如何进行隐私 AI 建模的方式?
也就是说,安全多方计算其实是一个非常广的概念。从密码学的角度看,MPC用到机器学习、AI里面,就是一个非常具体的应用了。那么应用运用了何种具体的方式?这就是Rosetta所要解决的问题。
Rosetta如何连接隐私计算与AI?
讲到现在,相信大家一定会遇到一个很大的问题,就是我们很想运用密码学解决问题,但是如果没有很高的数学基础或者没有学习过密码学的话,相关算法实在是门槛太高了。但是一些AI领域的专家、学者对于AI的应用,深度学习、机器学习的框架已经非常熟了。所以这两种具有不同专业技能的人,之间有很深的沟壑。在现实生活中,急需把这两种技术做一个融合,但是密码学相对的技术门槛太高,会影响整个行业的发展,也会影响整套隐私计算或者隐私AI的计算技术问题和理论进展。
所以我们想让熟悉机器学习,但是对密码学不了解的用户能够将隐私计算技术运用起来。另外对于一些熟悉了AI、或者TensorFlow、Pytorch等机器学习框架的开发者,让他们能够在几乎不改变开发习惯的前提下,就可以运用隐私AI的技术。我们需要做这样一个平台,或者开源框架,能够让不太熟悉密码学或者根本不懂密码学的AI层面的开发者或专家,能够用上隐私计算技术,这就是我们设计Rosetta的初衷,或者说设计Rosetta的一个根本原则。
因此Rosetta具备以下特点:易用性,高效性和可扩展性。
易用性,目前完全复用了TensorFlow接口。在明文和密文写模型的时候,TensorFlow的接口是一样的,没有再变。极大地降低了AI工程师使用隐私计算技术的成本。
高效性,完全兼容原生TensorFlow对数据流图自动执行的各种运行时优化。我们用C++来实现算法,能够保持底层算法的高效性。我们同时在跟业界的密码学家设计高效前沿的MPC技术,来适配机器学习或者深度学习的一些模型。
可扩展性,因为在MPC领域算法和协议非常多,而且涉及不同的场景,可能用不同的算法会有更好的效果。如果有了新的算法过来,Rosetta能够非常快速的集成到整个框架里面去。
下面,我们举例说明一下:
这里有三个参与方,A、B、C,然后每个人都有一个矩阵Ma、Mb、Mc,之后他们去计算Ma乘Mb乘Mc,他们三个只能知道结果,中间的过程都不知道。在这样一个场景下,如何运用Rosetta来实现它呢?和TensorFlow明文使用的区别有两个,一个是import包和选择算法,一个是简单处理隐私输入,即需要把Rosetta包import进来,选择算法,然后定义隐私输入即可。
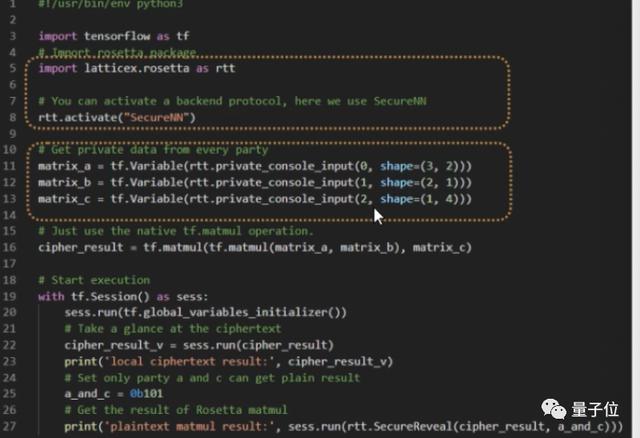
Rosetta的架构如下:
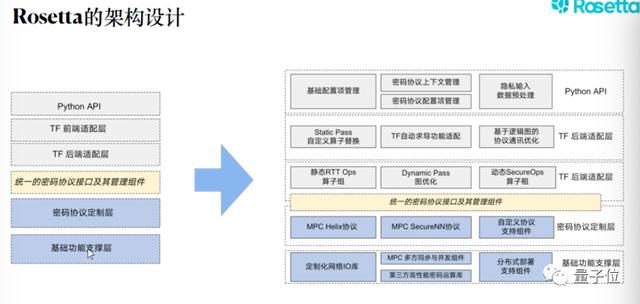
整体而言,Rosetta的框架图如上图所示,它包括Python的前端APl,这块是Rosetta方便用户使用而特色支持的,然后与TensorFlow的前后端做了适配,同时我们开发了一个统一的密码协议管理层,可以去适配不同的密码协议。
我们的目标是既能够让懂密码学的开发者把现在的东西复用到整个框架里来,也能够让不懂密码学的AI开发者能够无门槛的或者非常低门槛的去使用隐私计算技术,相当于把密码学与机器学习,有机的结合起来。这就是Rosetta的目标。
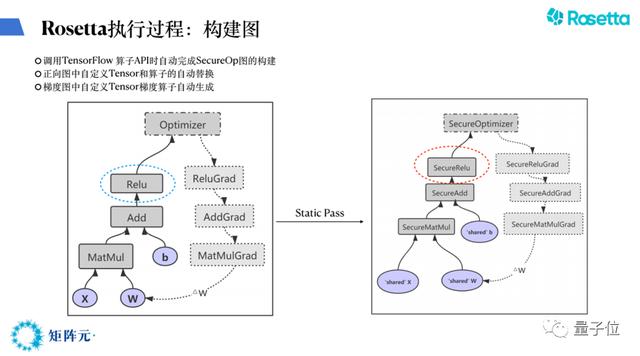
下面说一下Rosetta的架构,首先要讲TensorFlow架构,TensorFlow架构简单地说就是一个图转化和一个图执行。我们充分利用了TensorFlow架构来进行密码适配。
当TensorFlow把那个图变成下图左边标准的传统图时,我们去做了一个static pass,把每一个操作全部都转成SecureOp,这个统称是为了后面能够支持密码算法。
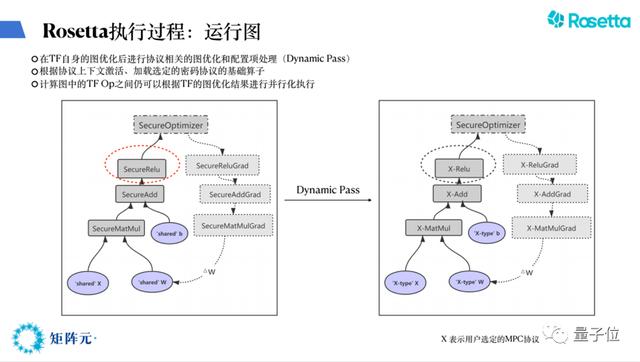
然后第二步就是图执行,图执行我们运用了dynamic pass,左边的图就是刚才转化之后的图,然后当数据的时候,根据每一个这样的图,dynamic pass可以动态去适配用某一类密码协议去执行这个图。
我们能够充分运用TensorFlow框架,同时因为能够利用整个底层的密码算法,dynamic pass也可充分利用TensorFlow这种optimizer之间的并行,可以让它跑得更快。
下面讲一个Rosetta在实际场景落地中的应用案例:金融场景下的应用。银行A与B,他们各有各的数据,然后互联网公司C也有数据,大家希望能够通过Rosetta把模型建起来,比如说训练逻辑回归后,把风控模型训练出来,训练出一个更加高效的模型。同时保证abc各方数据都不会被对方拿到,这种场景下,用Rosetta解决问题非常简单。

如上图,把Rosetta import进来,然后选一个协议,然后选相应的输入。后面就是标准的用TensorFlow去回归,所以后面完全不需要有任何密码学背景,也可以完全写出来。在多数据融合的训练场景里,只要Rosetta一个包,然后把数据做一些处理。后面整个逻辑回归的代码书写,跟原来的是一模一样的,甚至可以把代码直接拷贝过来。这里有一个问题,我们用MPC的方式也就是密文的方式,它的精度与明文的方式有何区别?
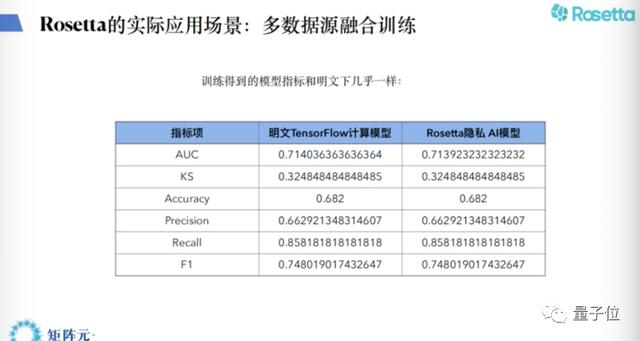
如上图,我们做了一个对比,大家可以看到几乎没有区别,基本等价了,所以在设计足够多的参数足够多的精度之后,完全可以保证整个模型的精度。当然还有一个场景就是所谓的模型预测服务。

最后讲一点,Rosetta刚刚开始,目前已经开源了0.2.1版本。下面是GitHub链接:
https://github.com/LatticeX-Foundation/Rosetta























