












【51CTO.com快译】
为什么转向Spark?
虽然我们都在谈论大数据,但通常在职场闯荡一段时间后才遇到大数据。在我供职的Wix.com,有逾1.6亿个用户在生成大量数据,因此需要扩展我们的数据流程。
虽然有其他选择(比如Dask),但我们决定选择Spark,原因主要有两个:(1)它是目前的最新技术,广泛用于大数据。(2)我们拥有Spark所需的基础架构。
如何针对pandas人群用PySpark编写代码?
您可能很熟悉pandas,仅仅搞好语法可能开了个好头,但确保PySpark项目成功还需要具备更多的条件,您要了解Spark的工作原理。
让Spark正常工作很难,但一旦可以正常工作,它效果很棒!
Spark简述
建议看看这篇文章,阅读MapReduce方面的说明以便更深入的了解:《如何使用Spark处理大数据?》(https://towardsdatascience.com/the-hitchhikers-guide-to-handle-big-data-using-spark-90b9be0fe89a)。
我们在这里要了解的概念是横向扩展。
从纵向扩展入手比较容易。如果我们有一个运行良好的pandas代码,但后来数据对于它来说太大了,我们可能会转移到一台内存更多、功能更强的机器上,希望它能应付得了。这意味着我们仍有一台机器同时在处理全部数据——这就是纵向扩展。
如果我们改而决定使用MapReduce,并将数据分成多个块,然后让不同的机器来处理每个块,这就是横向扩展。
五个Spark最佳实践
这五个Spark最佳实践帮助我将运行时间缩短至十分之一,并扩展项目。
1. 从小处入手——采样数据
如果我们想让大数据起作用,先要使用少量数据看到我们方向正确。在我的项目中,我采样10%的数据,并确保管道正常工作,这让我可以使用Spark UI中的SQL部分,并查看数字流经整个流程,不必等待太长的时间来运行流程。
凭我的经验,如果您用小样本就能达到所需的运行时间,通常可以轻松扩展。
2. 了解基础部分:任务、分区和核心
这可能是使用Spark时要理解的最重要的一点:
1个分区用于在1个核心上运行的1个任务。
您要始终了解自己有多少分区——密切关注每个阶段的任务数量,并在Spark连接中将它们与正确数量的核心进行匹配。几个技巧和经验法则可以帮助您做到这一点(所有这些都需要根据您的情况进行测试):
- 任务与核心之间的比例应该是每个核心约2至4个任务。
- 每个分区的大小应约为200MB–400MB,这取决于每个worker的内存,可根据需要来调整。
3. 调试Spark
Spark使用惰性求值,这意味着它在等到动作被调用后才执行计算指令图。动作示例包括show()和count()等。
这样一来,很难知道我们代码中的bug以及需要优化的地方。我发现大有帮助的一个实践是,使用df.cache()将代码划分为几个部分,然后使用df.count()强制Spark在每个部分计算df。
现在使用Spark UI,您可以查看每个部分的计算,并找出问题所在。值得一提的是,如果不使用我们在(1)中提到的采样就使用这种做法,可能会创建很长的运行时间,到时将很难调试。
4. 查找和解决偏度
让我们从定义偏度开始。正如我们提到,我们的数据分到多个分区;转换后,每个分区的大小可能随之变化。这会导致分区之间的大小出现很大的差异,这意味着我们的数据存在偏度。
可以通过在Spark UI中查看阶段方面的细节,并寻找最大数和中位数之间的显著差异以找到偏度:

图1. 很大的差异(中位数= 3秒,最大数= 7.5分钟)意味着数据有偏度。
这意味着我们有几个任务比其他任务要慢得多。
为什么这不好——这可能导致其他阶段等待这几项任务,使核心处于等待状态而无所事事。
如果您知道偏度来自何处,可以直接解决它并更改分区。如果您不知道/或没办法直接解决,尝试以下操作:
调整任务与核心之间的比例
如前所述,如果拥有的任务比核心更多,我们希望当更长的任务运行时,其他核心仍然忙于处理其他任务。尽管这是事实,但前面提到的比例(2-4:1)无法真正解决任务持续时间之间这么大的差异。我们可以试着将比例提高到10:1,看看是否有帮助,但是这种方法可能有其他缺点。
为数据加入随机字符串(salting)
Salting是指用随机密钥对数据重新分区,以便可以平衡新分区。这是PySpark的代码示例(使用通常会导致偏度的groupby):
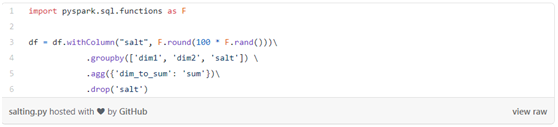
图2
5. Spark中迭代代码方面的问题
这是个棘手的问题。如前所述,Spark使用惰性求值,因此运行代码时,它仅构建计算图(DAG)。但当您有一个迭代过程时,该方法可能会很成问题,因为DAG重新打开了先前的迭代,而且变得很大。这可能太大了,驱动程序在内存中装不下。由于应用程序卡住了,因此很难找到问题所在,但是在Spark UI中好像没有作业在长时间运行(确实如此),直到驱动程序最终崩溃才发现并非如此。
这是目前Spark的一个固有问题,对我来说有用的解决方法是每5-6次迭代使用df.checkpoint()/ df.localCheckpoint()(试验一番可找到适合您的数字)。这招管用的原因是,checkpoint()打破了谱系和DAG(不像cache()),保存了结果,并从新的检查点开始。缺点在于,如果发生了什么岔子,您就没有整个DAG来重新创建df。
原文标题:5 Apache Spark Best Practices For Data Science,作者:Zion Badash
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】













