













本文转载自微信公众号「后端技术指南针」,作者指南针氪金入口 。转载本文请联系后端技术指南针公众号。
1. 写在前面
今天准备和盆友们一起学习下关于通用搜索引擎的一些技术点。
鉴于搜索引擎内容非常多,每一部分都够写好几篇文章的所以本文只是抛砖引玉,深入挖掘还得老铁们亲力亲为。
通过本文你将对通用搜索引擎的基本原理和组成有一个较为清晰的认识,用心读完,肯定有所收获!
废话不说,各位抓紧上车,冲鸭!
2. 初识搜索引擎
2.1 搜索引擎分类
搜索引擎根据其使用场景和规模,可以简单分为两大类:
通用搜索引擎
通用搜索又称为大搜,诸如谷歌、百度、搜狗、神马等等都属于这一类。

垂直搜索引擎
垂直搜索又称为垂搜,是特定领域的搜索,比如用QQ音乐搜周杰伦的歌等。

两类搜索引擎虽然数据规模和数据特征不一样,但都是为了填平用户和海量信息之间的鸿沟。
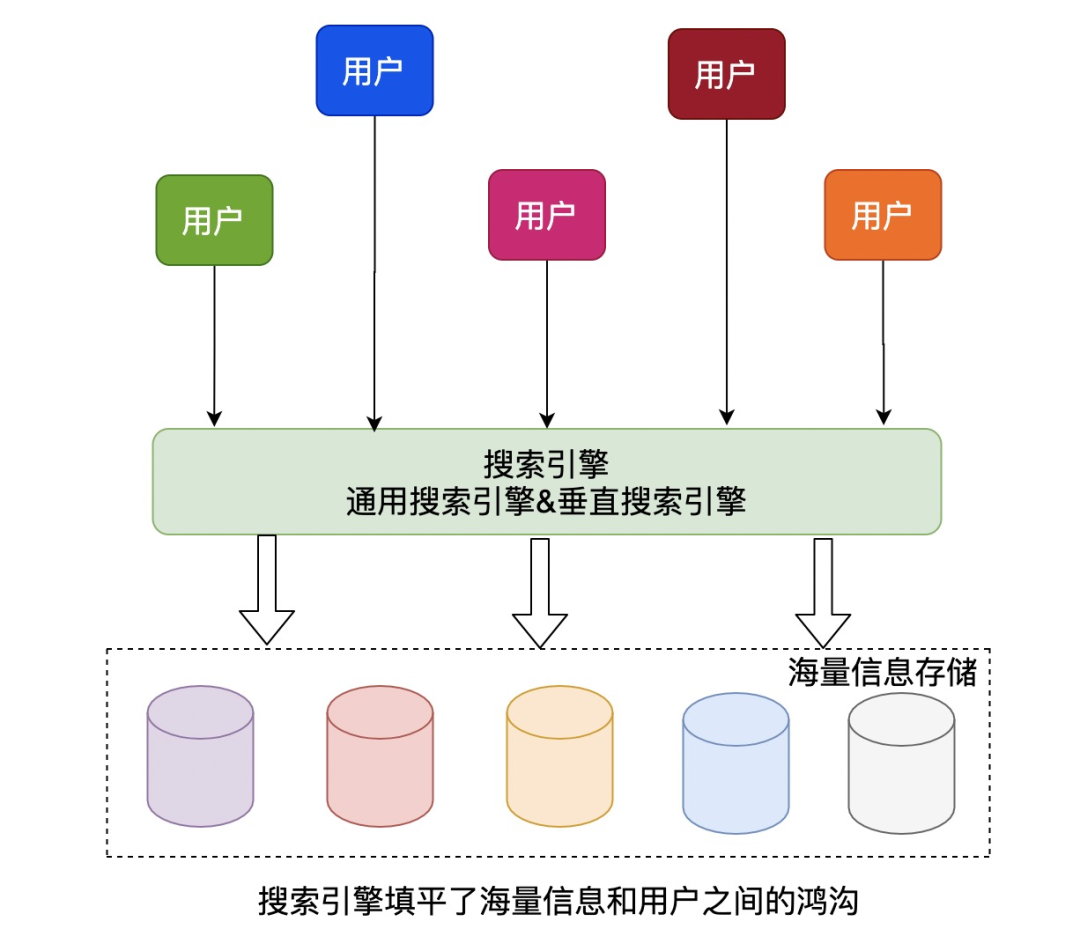
2.2 搜索和推荐
搜索和推荐经常被相提并论,但是二者存在一些区别和联系。
共同点
宏观上来说,搜索和推荐都是为了解决用户和信息之间的隔离问题,给用户有用的/需要的/喜欢的信息。
区别点
搜索一般是用户主动触发,按照自己的意图进行检索,推荐一般是系统主动推送,让用户看到可能感兴趣的信息。
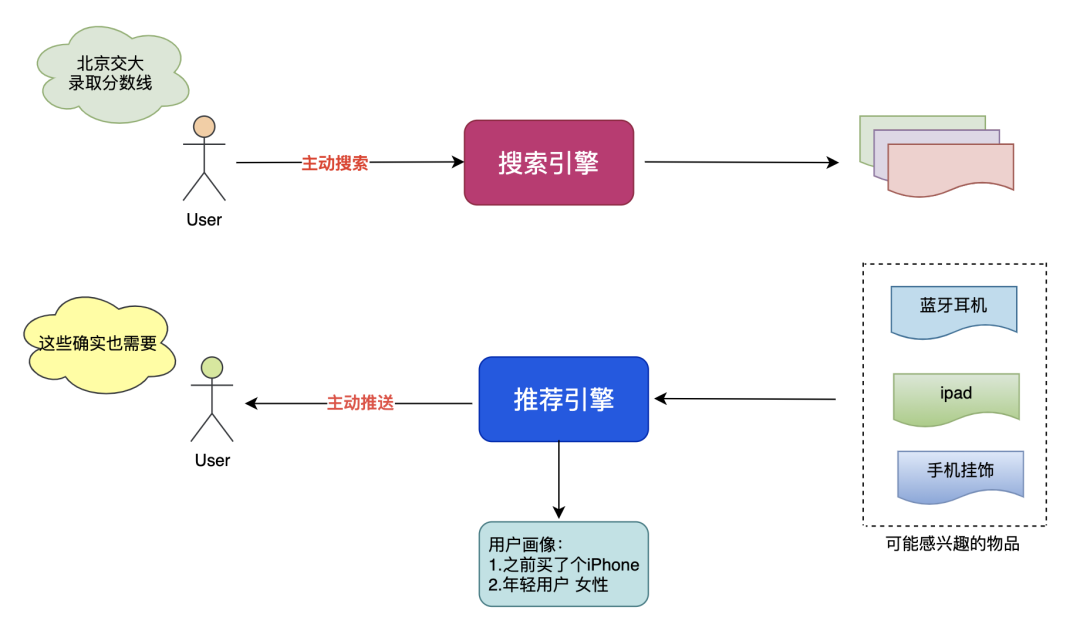
2.3 搜索引擎评价标准
我们每天都和搜索引擎打交道,评价一个搜索引擎的好坏可简单概括为:精准性、时效性、响应速度、权威性等。
换句话说,搜索引擎懂得用户真正想要找什么,可以快速准确地展示出来,对于一些热点突发信息也可以及时收录展示,就能很好地博得用户。
这个目标需要搜索引擎多个模块协作处理,是个复杂的系统工程,并非易事。
3. 通用搜索引擎的整体概览
3.1 搜索引擎的基本流程
大白尝试用朴实的语言来整体表达下,通用搜索引擎大致是怎么工作的:
1. 网络蜘蛛爬虫每天不辞辛苦地收录网页,然后存储起来,这样各个站点的页面就有了一份份镜像,这个规模是百亿/千亿级的。
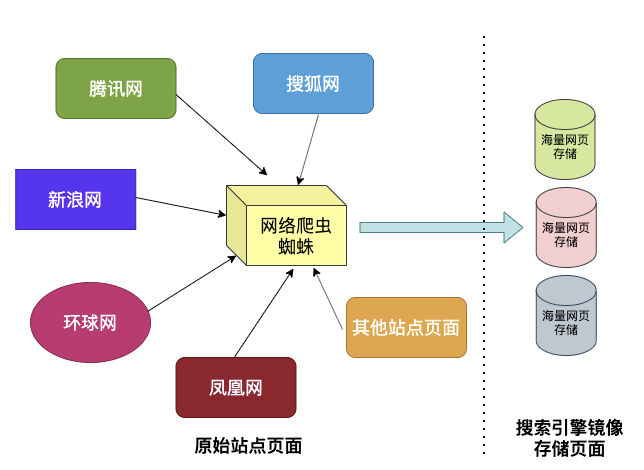
2. 单纯地镜像也不能直接用,需要加工处理,把一个个网页进行分词,建立搜索词和网页的对应关系,这样用户搜索某个东西时,才会拿到很多相关的网页。
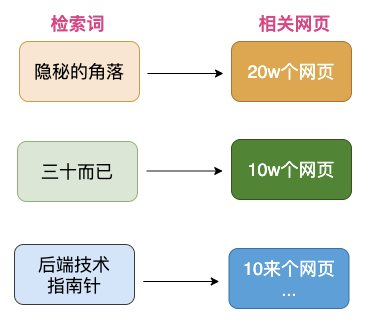
3. 比如"搜索隐秘的角落"可能会有100个相关网页被找到,但是网页和检索词的关联性肯定有强有弱,因此还需要进行网页的排序,排序策略有很多,最终把优质的网页排在前面展示给用户。
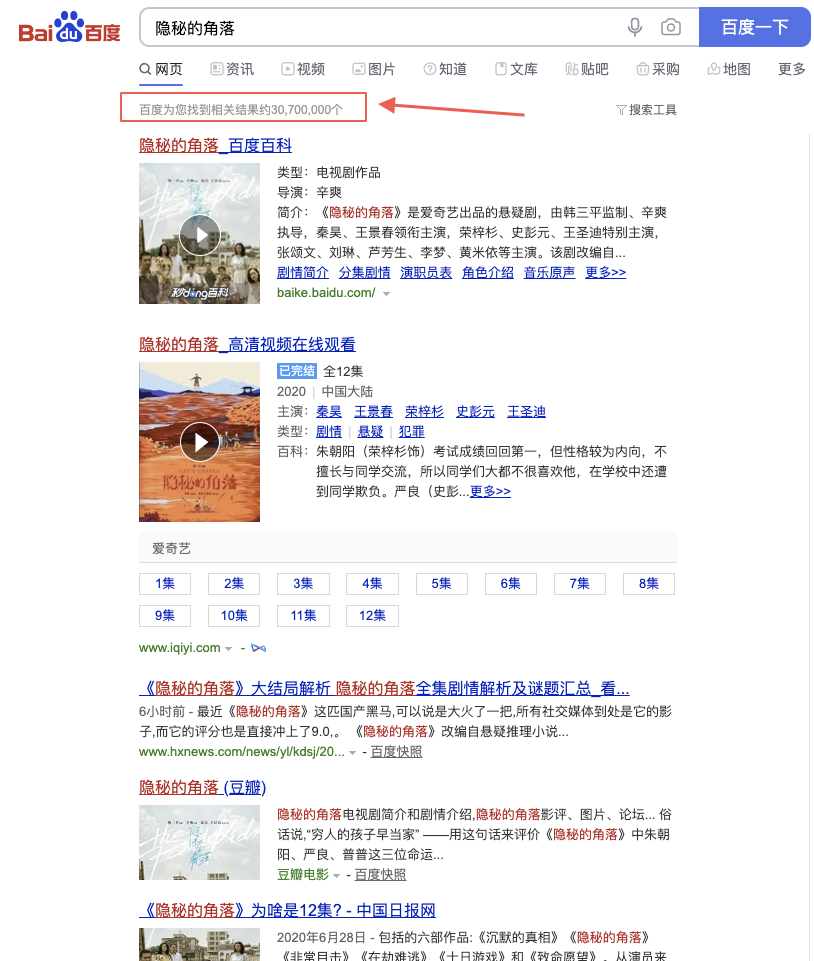
用户看到相关结果之后,进行点击或者跳过,搜索引擎根据用户的相关动作进行调整,实现整个闭环过程。
4. 为了能更好地理解用户的真实用途,需要进行检索词的意图理解、词条切分、同义词替换、语法纠错等处理,再根据这些检索词去获取数据,为用户找到心中所想的网页。
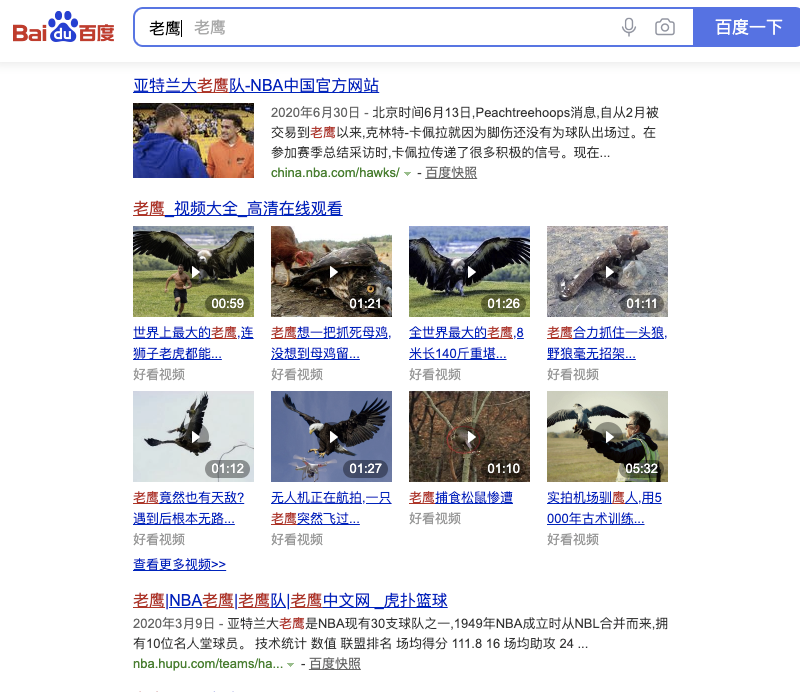
比如检索词为"老鹰",可能是自然界的老鹰,也可能是NBA的一只球队:
3.2 搜索引擎的基本组成
我们从整体简单看下基本组成以及各个模块的主要功能:
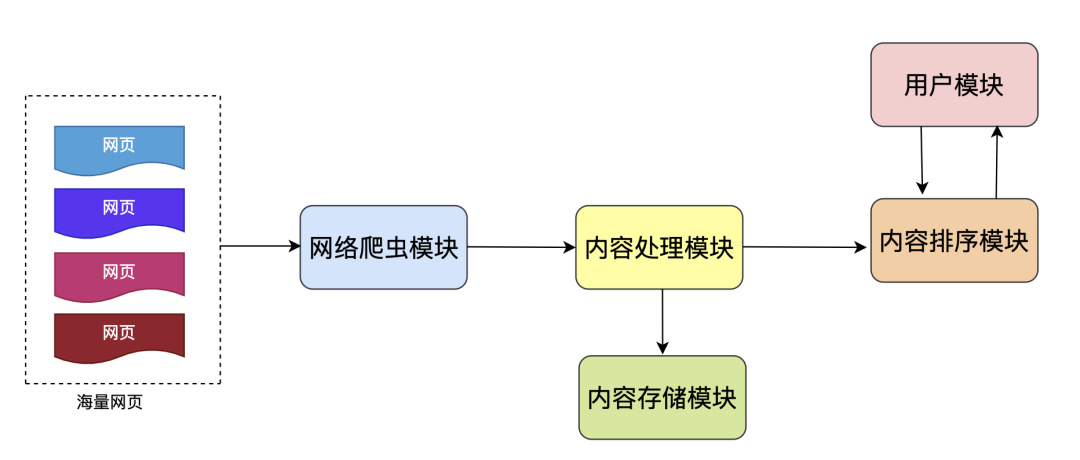
网络爬虫模块
搜索引擎中的网络爬虫就是网页的搬运工,负责将互联网上允许被抓取的网页进行下载,如果把搜索引擎看作一家餐厅,网络爬虫模块就是餐厅的采购员。
内容处理模块
负责将网络爬虫下载的页面进行内容解析、内容清洗、主体抽取、建立索引、链接分析、反作弊等环节。
内容存储模块
存储模块是搜索引擎的坚强后盾,将抓取的原始网页、处理后的中间结果等等进行存储,这个存储规模也是非常大的,可能需要几万台机器。
用户解析模块
用户模块负责接收用户的查询词、分词、同义词转换、语义理解等等,去揣摩用户的真实意图、查询重点才能返回正确的结果。
内容排序模块
结合用户模块解析的查询词和内容索引生成用户查询结果,并对页面进行排序,是搜索引擎比较核心的部分。
接下来,我们将粗浅地介绍几个模块的基本内容和技术点。
4. 网络爬虫模块简介
网络爬虫模块是通用搜索引擎非常的基础组件,一般都会采用分布式爬虫来实现,我们来看看这个搬运工是如何实现海量网页发掘的:
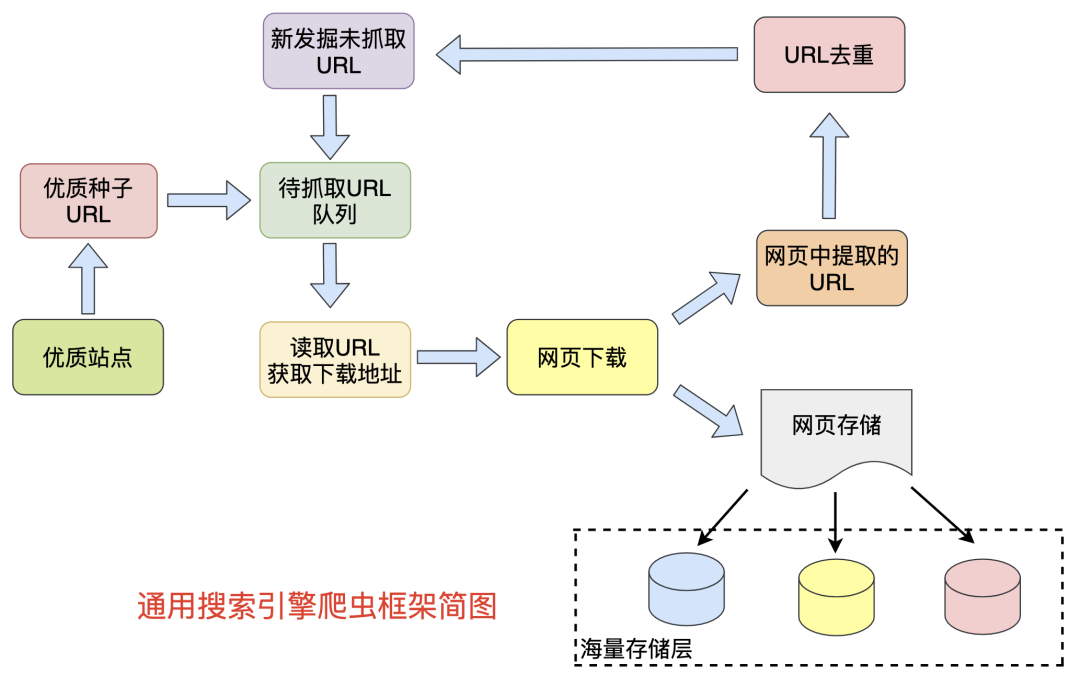
网络爬虫的基本流程:
- 将热门站点的优质URL作为种子,放到待抓取的URL队列中
- 读取待抓取URL获取地址进行下载
- 将下载的网页内容进行解析,将网页存储到hbase/hdfs等,并提取网页中存在的其他URL
- 发掘到新的URL进行去重,如果是未抓取的则放到抓取队列中
- 直到待抓取URL队列为空,完成本轮抓取
在抓取过程中会有多种遍历策略:深度优先遍历DFS、广度优先遍历BFS、部分PageRank策略、OPIC在线页面重要性计算策略、大站优先策略等。
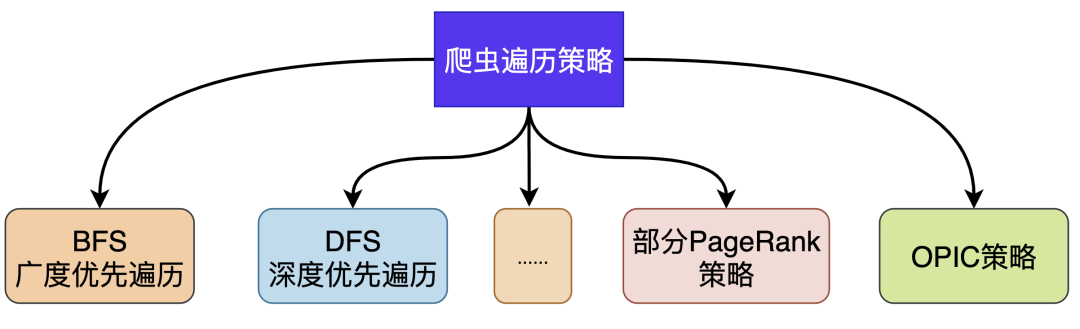
在工程实践中需要根据自身情况和搜索引擎特点进行选择某种策略或者多种策略组合。
网络爬虫需要遵循Robots协议(网络爬虫排除标准),这是网络爬虫和站点之间的君子协定,站点通过协议告诉网络爬虫哪些可以抓哪些不可以。
网络爬虫同时需要考虑抓取频率,防止给站点造成过重负担,总之,搜索引擎的网络爬虫需要是个谦谦君子。
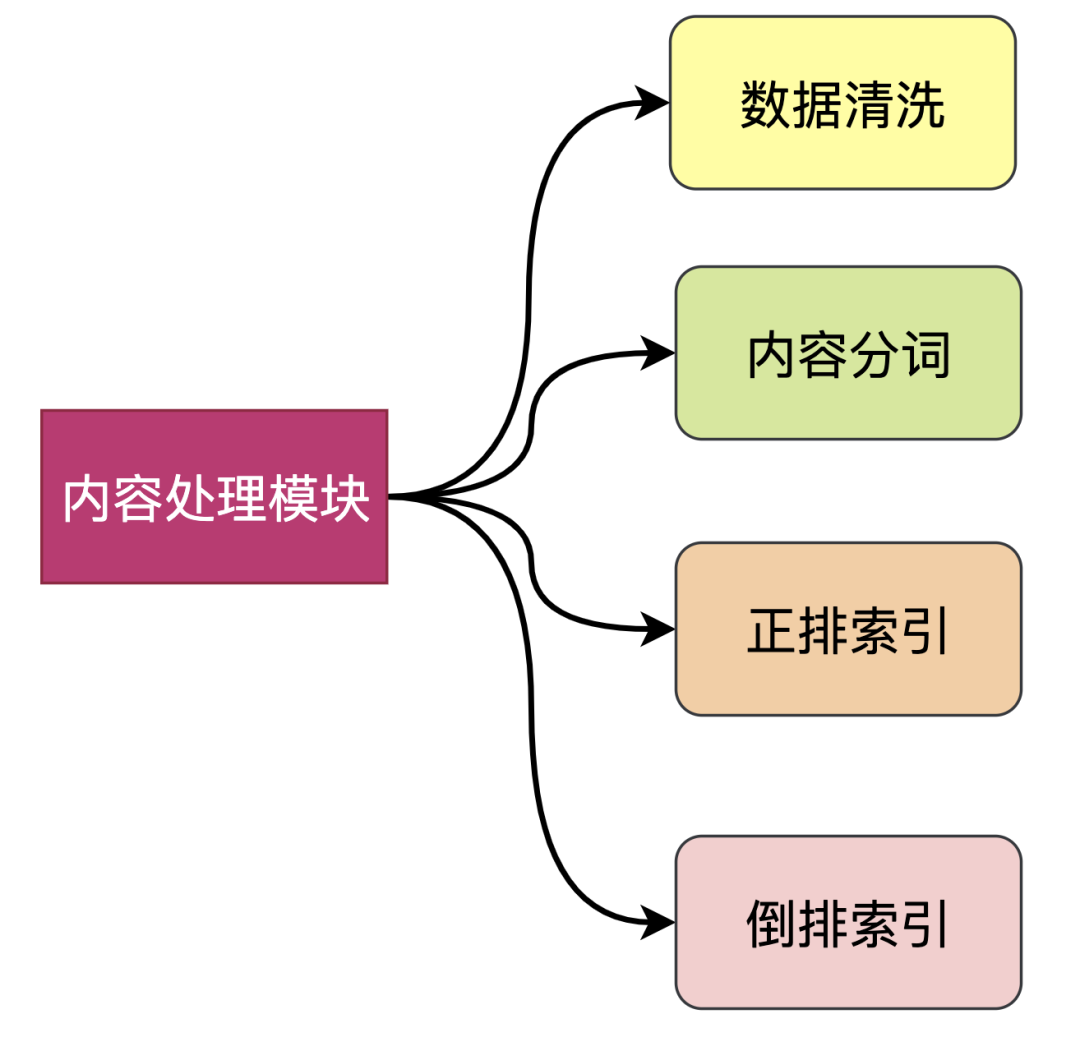
5. 网页内容处理模块
爬虫模块将网页内容存储之后,网页内存处理模块开始解析网页内容,主要工作包括:数据清洗、网页内容分词、建立正排索引、建立倒排索引等。
5.1 数据清洗
一般来说,网页中除了具体内容还会有很多无关的东西,比如html标签、推广等,这些在实际搜索引擎中都是无用的。

内容处理模块会将无用数据、标签清洗掉,为后续的分词做准备。
5.2 中文分词
将清洗完成的内容进行分词提取关键词,比如一个网页内容有1000字,分词之后大约有50个词,相当于提取了网页的主干,并且会对标题、摘要、正文等不同部分的内容做不同权重处理。
分词过程中会剔除停用词、虚词等,比如"的、得、地"等,从而极力还原网页的主干内容。
我们用在线网页分词工具和真实网页来模拟下这个过程:
网页分词在线工具:http://www.78901.net/fenci/
抓取网页:https://tech.huanqiu.com/article/3zMq4KbdTAA

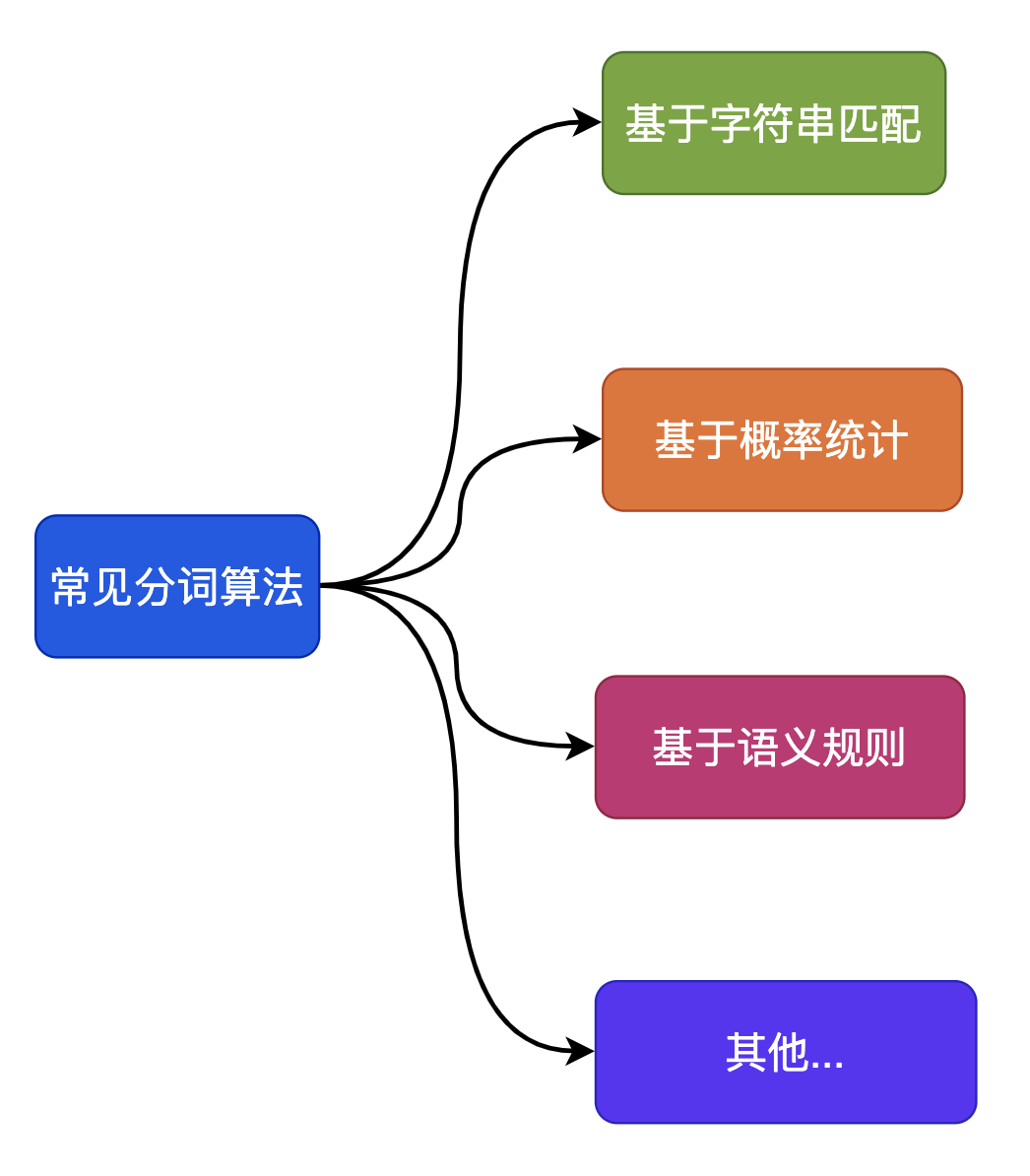
可以看到分词后可以标注词频,这些都是后续作为网页排序的重要来源,但是中文是很复杂的,因此分词算法会有很多种,常见的包括:
- 基于字符串匹配的分词算法
- 基于概率统计的分词算法
- 基于语义规则的分词算法
- 其他算法
5.3 正排索引
假定我们将每个网页进行唯一编号docid,经过前面的分词一个网页将被分成不同权重的多个实体词。
所谓正排就是根据docid可以拿到属于该网页的所有内容,是一个符合我们思维的正向过程,相对而言会有倒排索引。
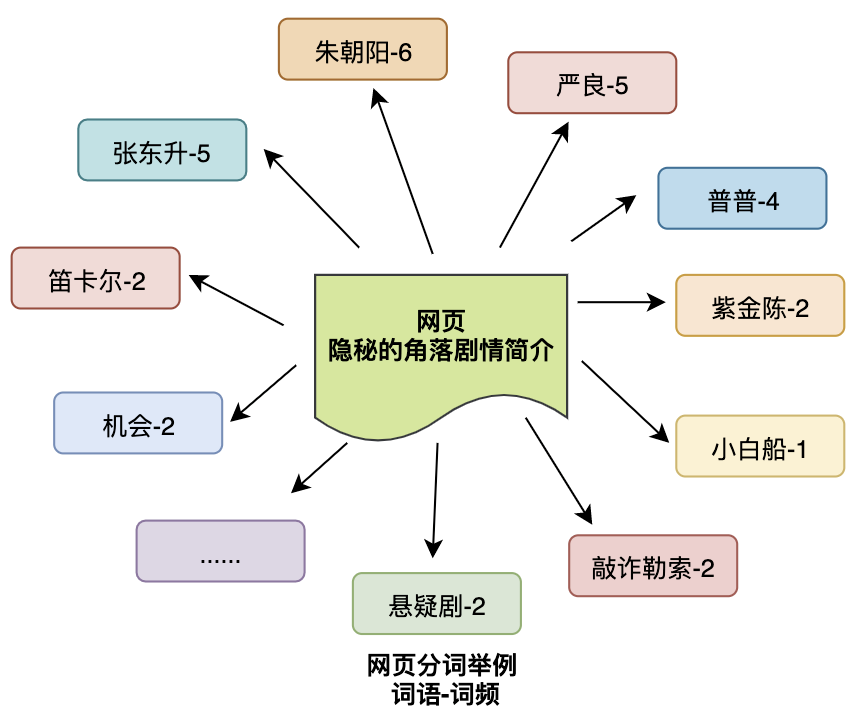
我们以一篇《隐秘的角落》剧情简介的页面为例,模拟分词情况,大致如下(本分词结果纯属脑补,以实际为准):
5.4 倒排索引
假如我们对10000个网页进行了分词,其中包含了一些公共检索词:微山湖、智取威虎山、三十而立、隐秘的角落等,因此我们汇总之后将建立检索词->网页的映射关系。
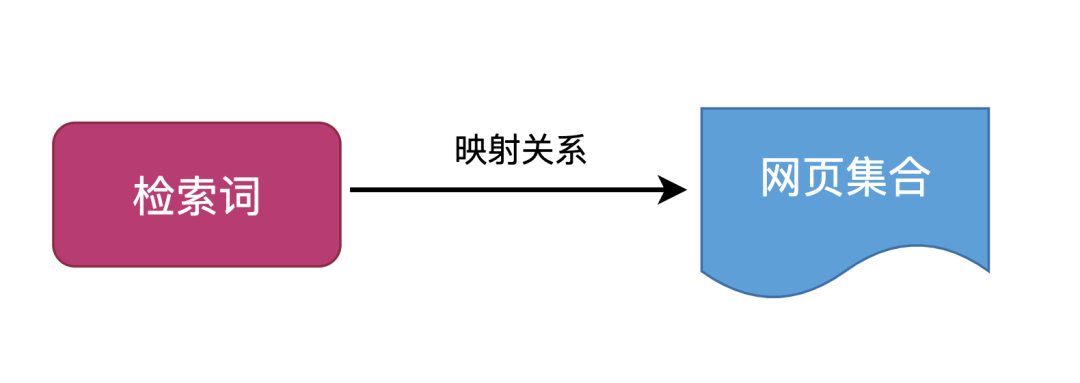
那么对于检索词"隐秘的角落"出现很多个网页,倒排索引就相当于从一个词能拉取到多少文章的过程。
就如同我们提到美食就想到:火锅、烧烤、烤鸭、炒菜等等,是一个从点到面的过程,这种逆向过程在搜索引擎中非常重要。
5.5 本章小结
内容处理模块将抓取到的网页进行清洗、提前新URL给爬虫模块、内容分词、建立正排索引和倒排索引,是个承上启下的中间环节。
特别地,提一下正排索引和倒排索引,字面上并不直观,其实道理并不难理解:
正排索引:具体到一篇网页有多少关键词,特指属于该网页本身的内容集合,是一个网页。
倒排索引:一个检索关键词对应多少相关联的网页,也就是可备选网页集合,是一类网页。
6. 网页排序和用户模块
6.1 网页排序的必要性
由于存储的网页是百千亿级的,那么一个检索词可能对于几万、几十万甚至更多相关的网页。
网页排序需要综合考虑:相关性、权威性、时效性、丰富度等多个方面。
搜索引擎要展示优质的强关联网页给用户,并且放在靠前的位置,否则搜索效果将会很差,用户并不买账。
事实上也是如此,比如搜索引擎返回了10页结果,每页10条,总结100条,一般用户点击到1-3页之后的网页大概率就不再点击了,因此排序的头部内容对于搜索结果至关重要。
我们仍然以检索"隐秘的角落"为例,百度共计返回了10页,其中1-2页的内容是强关联的,是个比较不错的检索结果了:

6.2 网页排序的常见策略
网页排序策略是个不断优化和提升的演进过程,我们来一起看下都有哪些排序策略:
基于词频和位置权重的排序
这是早期搜索引擎常采取的方法,相对简单但是效果还不错。
简单来说就是根据网页中关键词的出现频率以及出现位置作为排序依据,因为普遍认为:检索词出现次数越多、位置越重要,网页的关联性越好,排名越靠前。
词频并不是单纯的统计次数,需要有全局观念来判断关键词的相对次数,这就是我们要说的TF-IDF逆文档频率,来看下百度百科的解释:
TF-IDF (term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。
TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
举个栗子:
网页中"吃饭"这个词出现了10次,虽然次数很多,但是"吃饭"这个词过于普通,因为在很多其他网页都出现了,因此"吃饭"这个检索词的重要性就相对下降了。
基于链接分析的排序
链接分析排序认为:网页被别的网页引用的次数越多或者越权威的网页引用,说明该网页质量越高。
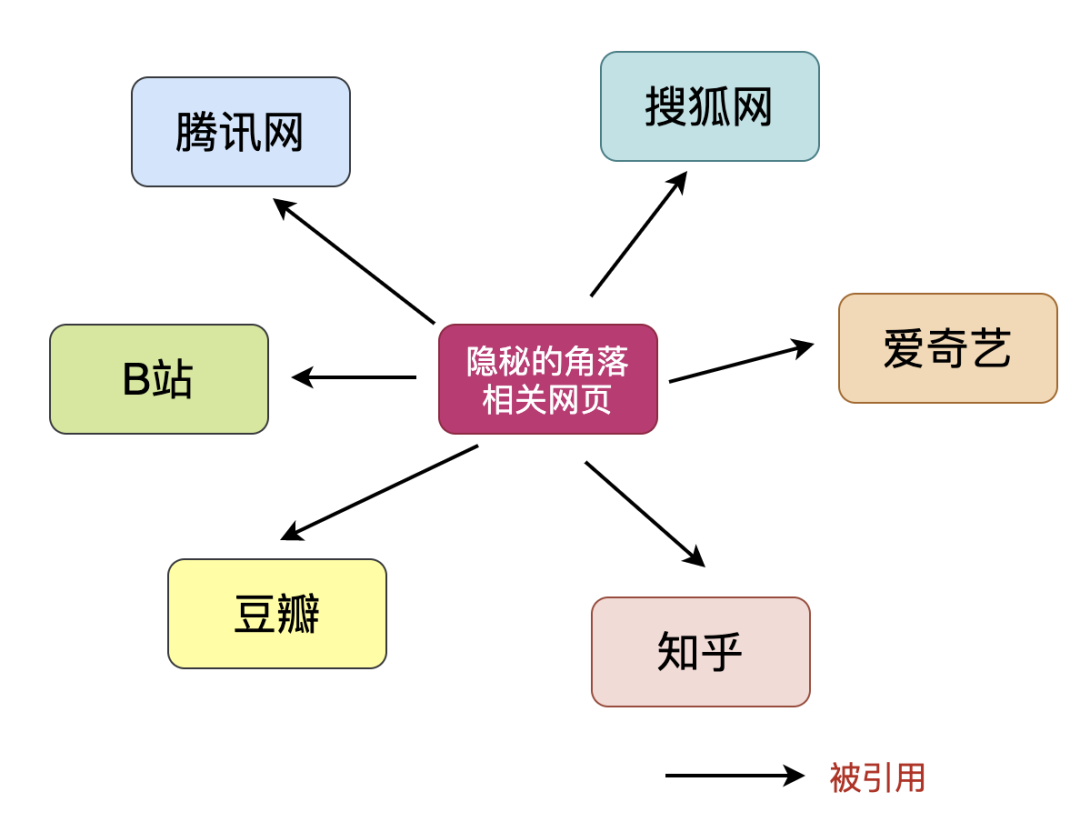
基于链接分析的排序算法有很多种,其中最有名的PageRank算法被谷歌广泛采用,是其核心排序算法。
来看下PageRank算法的基本思想:
网页的重要程度用PageRank值来衡量,网页的PageRank值体现在两个方面:引用该网页其他网页个数和引用该页面的其他页面的重要程度。
假定一个网页A被另一个网页B引用,网页B就将PageRank值分配给网页B所引用的网页,所以越多引用网页A则其PageRank值也就越高。
另外网页B越重要,它所引用的页面能分配到的PageRank值就越多,网页A的PageRank值也就越高越重要。
其实这个算法说起来非常简单:比如写公众号,有大V转载就相当于引用了,越多其他公众号转载,说明你的公众号内容质量越高。

PageRank算法也存在一定的问题,比如对新页面不友好,新页面暂时没有被大量引用,因此PageRank值很低,并且PageRank算法强调网页之间的引用关系,对网页本身的主题内容可能重视程度不够,也就是所谓的主题漂流问题。
与PageRank算法类似于的还有一些其他算法来弥补主题关联问题,包括:HillTop算法、Topic-Sensitive PageRank算法、HITS算法等,本文就不再展开了。
6.3 网页反作弊和SEO
搜索引擎也存在二八原则,头部的网页占据了大量的点击流量,也意味着巨大的商业价值。
这里就要提到SEO,先看下百度百科对SEO的定义:
搜索引擎优化又称为SEO,即Search Engine Optimization,它是一种通过分析搜索引擎的排名规律,了解各种搜索引擎怎样进行搜索、怎样抓取互联网页面、怎样确定特定关键词的搜索结果排名的技术。
搜索引擎采用易于被搜索引用的手段,对网站进行有针对性的优化,提高网站在搜索引擎中的自然排名,吸引更多的用户访问网站,提高网站的访问量,提高网站的销售能力和宣传能力,从而提升网站的品牌效应。
道高一尺魔高一丈,只有魔法可以打败魔法。

网页反作弊是搜索引擎需要解决的重要问题,常见的有内容反作弊、链接分析反作弊等。
网页内容作弊
比如在网页内容中增加大量重复热词、在标题/摘要等重要位置增加热度词、html标签作弊等等,比如在一篇主题无联系的网页中增加大量"隐秘的角落"热度词、增加 等强调性html标签。
链接分析作弊
构建大量相互引用的页面集合、购买高排名友链等等,就是搞很多可以指向自己网页的其他网页,从而构成一个作弊引用链条。
6.4 用户搜索意图理解
用户模块直接和用户交互,接收用户的搜索词,准确理解用户的搜索意图非常重要。
实际上用户的输入是五花八门的,偏口语化,甚至有拼写错误、并且不同背景的用户对同一个检索词的需求不一样、无争议检索词的使用目的也不一样。
检索词为:美食宫保鸡丁
这个检索词算是比较优质了,但是仍然不明确是想找饭店去吃宫保鸡丁?还是想找宫保鸡丁的菜谱?还是想查宫保鸡丁的历史起源?还是宫保鸡丁的相关评价?所以会出现很多情况。
检索词为:你说我中午迟点啥呢?
口语化检索词并且存在错别字,其中可能涉及词语纠错、同义词转换等等,才能找到准确的检索词,进而明确检索意图,召回网页。
7. 全文总结
搜索引擎是个非常复杂的系统工程,涉及非常多的算法和工程实现,本文旨在和大家一起简单梳理搜索引擎的基本组成和运行原理,算是科普文章了。
搜索引擎中每一个模块做好都不容易,也是互联网产品中技术含金量的典型代表,深挖一个模块都受益匪浅。















