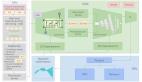
在这篇文章中,我展示了使用H2o.ai框架的机器学习,使用R语言进行股票价格预测的分步方法。 该框架也可以在Python中使用,但是,由于我对R更加熟悉,因此我将以该语言展示该教程。 您可能已经问过自己:如何使用人工智能预测股价? 这是执行此操作的步骤:
- 收集资料
- 导入数据
- 清理和处理数据
- 分开进行测试和培训观察
- 选择型号
- 训练模型
- 将模型应用于测试数据
- 评估结果
- 必要时增强模型
- 重复步骤5至10,直到对结果满意为止。
在上一篇文章中,我展示了如何使用Plotly库绘制高频数据,并解释了如何收集数据以进行分析。 让我们直接跳到列表中的第3步,如果您想知道如何执行第1步和第2步,请访问上一本出版物。
我们的研究问题是:"下一个小时资产的收盘价是多少?"
数据清理
导入要使用MetaTrader进行预测的资产数据后,我们需要更改一些变量。 首先,我们定义变量的名称:
- #seting the name of variables
- col_names <- c("Date", "Open", "High", "Low", "Close", "Tick", "Volume")
- colnames(data) <- col_nameshead(data)
我们的数据将采用以下形式:
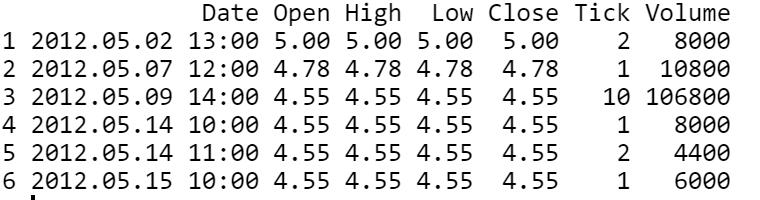
> Data — Image by Author
我们将仅使用一些可用变量:开盘价,最高价,最低价,收盘价和交易量。 这样,我们将消除其他人。
- data$Date <- NULL
- data$Tick <- NULL
由于我们想知道下一次观察的收盘价,因此我们需要将以下值移动到上方一行。 为此,我们创建一个函数并使用新数据在原始数据集中创建一个变量:
- #shifting n rows up of a given variableshift <- function(x, n) { c(x[-(seq(n))], rep(NA, n))}data$shifted <- shift(data$Close, 1)tail(data)
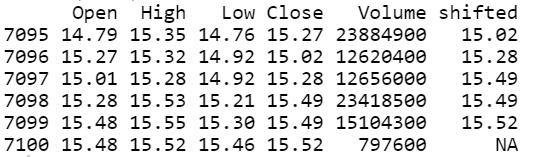
> Data — Image by Author
注意,我们在上面的第一行分配了变量Close的值。 这样,我们在最后一行有一个NA,我们使用na.omit()函数来省略该行:
- #remove NA observationsdata <- na.omit(data)write.csv(data, "data.csv")
完美,我们已准备好数据来开始建模。
分割数据
在此问题中,我们将使用名为H2O.ai的软件包,该软件包为我们提供了用于分析和训练人工智能模型的完整解决方案。 其用户友好的结构使没有数据科学背景的人们能够解决复杂的问题。 首先将库加载到我们的环境中:
- #Installing the packageinstall.packages("h2o")#loading the library library(h2o)
安装和加载后,我们将启动虚拟机,该虚拟机将用作构建模型的基础。 启动虚拟机时,我们必须设置所需的内核数和内存参数:
- #Initializing the Virtual Machine using all the threads (-1) and 16gb of memoryh2o.init(nthreads = -1, max_mem_size = "16g")
导入数据:
- h2o.importFile("data.csv")h2o.describe(data)
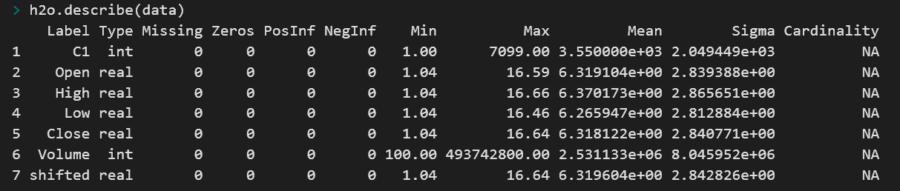
> Data into h2o — Image by Author
现在,我们定义我们要在数据集中预测的变量以及将用于"教导"模型的变量。
- y <- "shifted" #variable we want to forecastx <- setdiff(names(data), y)
然后,我们按训练数据的80%的比例将数据分为训练和测试。
- parts <- h2o.splitFrame(data, .80)train <- parts[[1]]test <- parts[[2]]
分割数据后,我们转到H2O.ai软件包不可思议的部分。
选择模型
每个数据科学家在创建其机器学习项目时需要执行的任务之一就是确定最佳模型或一组模型以进行预测。 这需要大量的知识,尤其是扎实的数学基础,才能为特定任务选择最佳知识。
借助H2O.ai软件包,我们可以要求它为我们选择最佳模型,同时还要照顾其他任何问题。 这称为自动建模。 显然,这种魔力可能不是解决问题的最有效方法,但这是一个好的开始。
训练模型
要创建我们的模型,我们调用automl函数并传递必要的参数,如下所示:
- automodel <- h2o.automl(x, y, train, test, max_runtime_secs = 120)
几分钟后,我们将获得按性能排序的模型列表。 要了解有关它们的更多信息,请致电:
automodel@leader
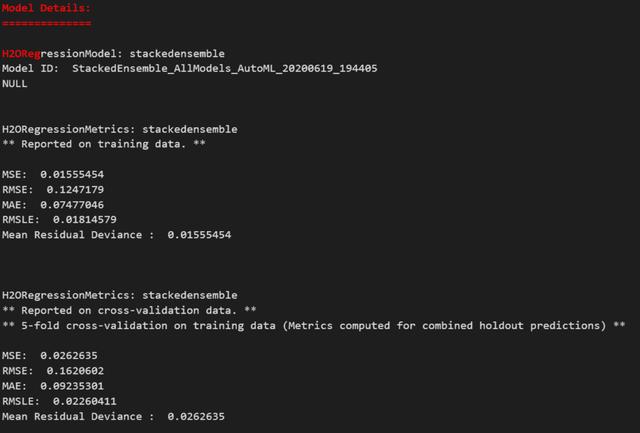
> Model Description — Image by Author
应用模型
现在我们有了领导者,让我们将其应用于测试数据! 这是最酷的部分,因为我们将使用模型尚未观察到的数据来评估性能。
我们将模型和测试数据作为参数调用预测函数!
- predictions <- h2o.predict(automodel@leader, test)
结论
在这篇文章中,我们看到了如何处理和操纵资产的财务数据,并轻松创建了机器学习模型,以便在分析数据后的一小时内对收盘价做出预测。
该模型的评估和优化将在下一篇文章中进行。
下周见!