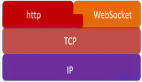
说到NVMe,“快”是它给人们的第一印象。还在两年前,支持NVMe的全闪存阵列数量只占整个存储市场很小的一部分,而今年,你已经很难看到中端以上的存储新品不支持NVMe。
不过,NVMe除了快还有什么?我们经常听到端到端NVMe、NVMe-OF或FC-NVMe,它们又是什么意思呢?
今天小编就来给大家扒一扒NVMe,如果你还不知道就真的out啦。
NVMe的诞生背景
NVMe发展的过程,就是不断给SSD“开绿灯”的过程。
今天我们已经知道,SSD的出现带给存储系统性能提升是革命性的,然而在当时的年代里,SSD的性能想要完全发挥,却面临着诸多瓶颈。
这是因为是当时的存储系统都是面向机械硬盘而设计的。举例来说,早期的全闪或混闪阵列中很多是在使用传统的存储技术——SATA SSD,这类存储基于AHCI(Advanced Host Controller Interface,高级主机控制器接口)命令协议。而AHCI是为机械硬盘而生,采用AHCI的SATA III总线只允许数据传输速度达到600MB/s。
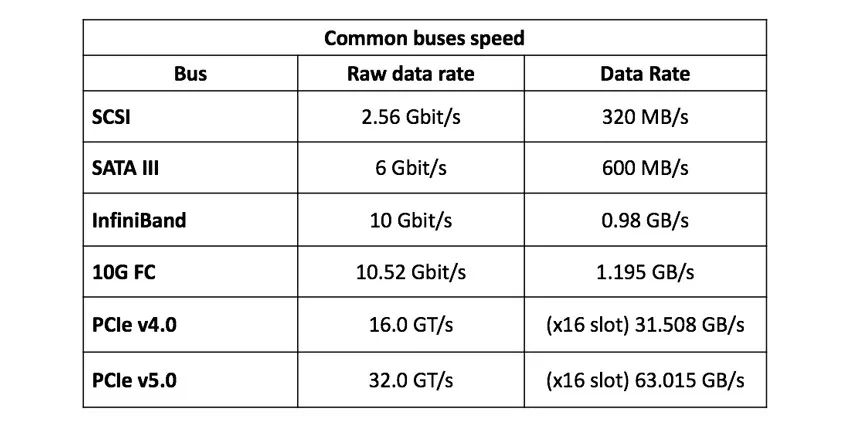
因此,为了让SSD在存储中跑得更畅快,NVMe规范诞生了。
NVMe全称是Nonvolatile Memory Express(非易失性内存标准),在它首次投放市场的时候,许多人认为它只是一个新的、速度更快的SSD。但实际上,NVMe是一种基于性能并从头开始创建新存储协议,它可以使我们能够充分利用SSD和存储类内存(SCM)的速度。
NVMe替代了原有的AHCI规范,并且软件层面的处理命令也进行了重新定义,不再采用SCSI/ATA命令规范。并且NVMe SSD利用了计算机或服务器中的PCIe高速总线,将其直接连接到计算机,从而减少了CPU的开销,简化了操作,降低了延迟,提高了IOPS和吞吐量。
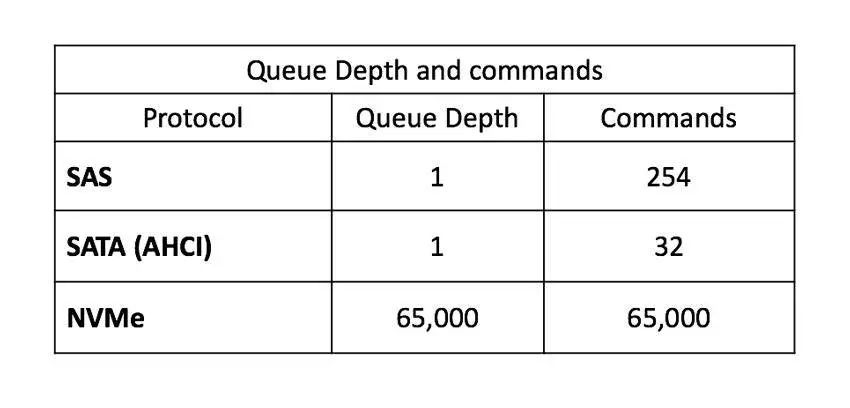
队列深度(QD)是NVMe相对于AHCI的另一个优势。SAS和AHCI只能是单个队列,而且每个队列的深度也比较低,分别是254和32的队列深度。而NVMe协议设计之初就考虑了该问题,它的最大队列数量可以是65K,而且每个队列的深度可以高达65K。除了减少延迟外,这对于提高服务器处理并发请求的能力至关重要。
什么是端到端NVMe?
说完了NVMe,再来说说端到端NVMe。
关注戴尔易安信的童鞋一定经常看到,当我们在描述PowerMax或PowerStore时,会常常使用到支持“端到端NVMe”这个词汇。其实,这也意味着SSD的性能还能得到进一步的释放。

这是因为当时的全闪存阵列大部分是在存储后端支持NVMe SSD,与使用SATA或SAS SSD的全闪存阵列相比,确实带来了性能的提升。然而,这并不意味NVMe SSD已经发挥出了它的性能极限。事实上,NVMe SSD全闪存阵列理论上可以提供更大的性能提升——比使用SAS和SATA SSD的全闪存阵列多10倍性能。
这种巨大的性能差异源于这样一个事实,即当时的全闪存阵列控制器架构也是为了适应机械硬盘而设计的,而在使用NVMe SSD时,这种控制器就成为了阻碍,为此,阵列控制器以及存储网络协议必须不断发展。
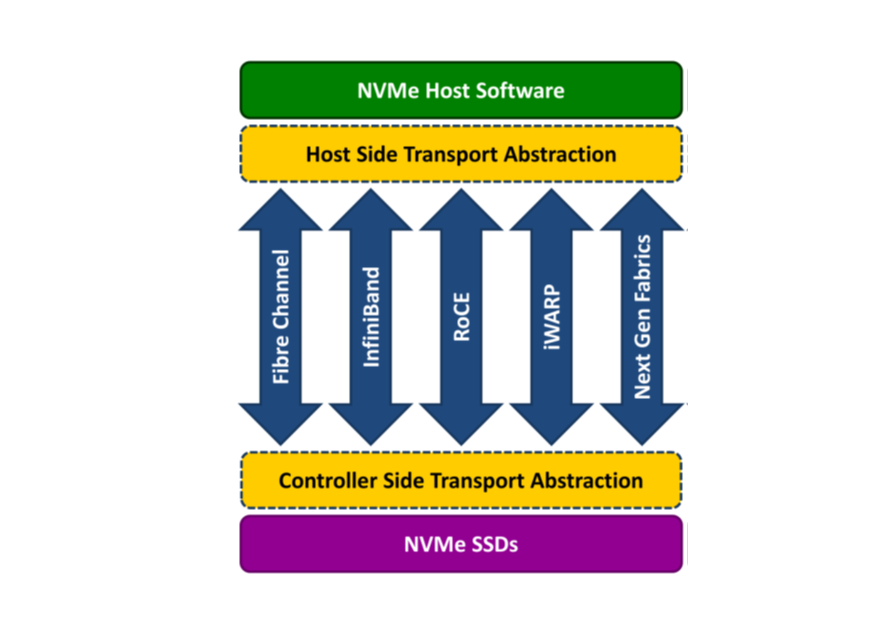
而NVMe over Fabrics(简称NVMe-OF)的出现,就是将NVMe应用到前端,作为存储阵列与前端主机连接的通道,取代过去的FC、iSCSI。由此,主机可以使用本机NVMe协议直接与NVMe SSD通信,从而大幅降低了延迟。
说到这儿,小编必须要提一下2016年发布的DSSD D5存储,它是戴尔易安信推出的业界第一款端到端NVMe存储。这款存储专为性能而生,其控制器、闪存模组到前端主机I/O卡全都是专属规格,其性能可达到千万级的IOPS和100 GB每秒的吞吐量,而且延时能则降到100微秒的延时。这些性能数据足以秒杀当前市面上任何一款存储系统,可谓是不折不扣的性能怪兽。

不过,也许是因为设计理念太过超前,这款产品并没有延续下去,而是转化为宝贵的技术资产,今天戴尔易安信PowerMax和PowerStore上所支持的端到端NVMe技术,实际上就有来自DSSD的技术积淀。
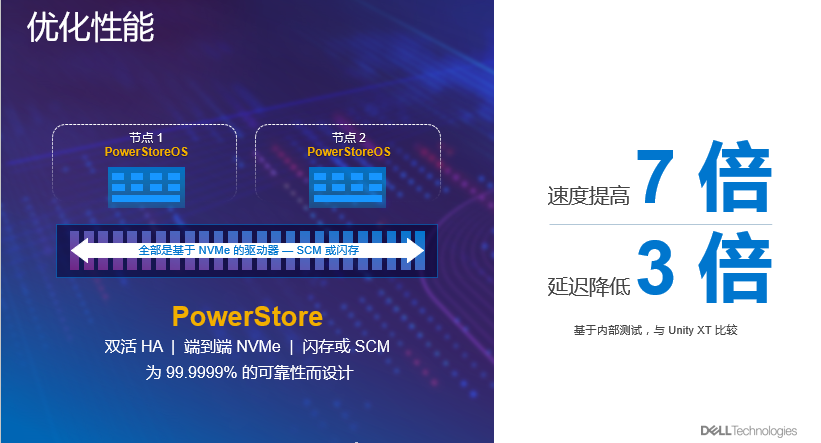
*戴尔易安信PowerStore采用英特尔®至强®可扩展处理器,该处理器可以优化工作负载,可靠性强,还有高计算力、高稳定性和高效敏捷性,不仅帮助PowerStore轻松满足既定工作负载,也可以为数字化变革做好准备。
NVMe-oF传输类型
对于NVMe-oF,传输类型有3种选择,分别是使用光纤通道的NVMe-oF、TCP的NVMe-oF和使用RDMA的NVMe-oF。
Fibre Channel
在光纤通道(FC)上使用NVMe的组合通常被称为FC-NVMe、NVMe over FC,有时也称为NVMe/FC。光纤通道是存储阵列和服务器之间传输数据的强大协议,大多数SAN存储系统都使用它。在FC-NVMe中,SCSI命令被封装在FC帧内。它基于标准的FC规则,与支持访问共享NVMe闪存的标准FC协议相匹配。

TCP
这种传输类型是NVMe-oF的最新发展之一。NVMe over TCP(传输控制协议)使用NVMe-oF和TCP传输协议在IP(以太网)网络上传输数据。NVMe通过以太网作为物理传输,在TCP数据报内进行传输。
尽管有RDMA和光纤通道,TCP提供了一个可能更便宜和更灵活的选择。此外,与同样使用以太网的RoCE相比,NVMe/TCP的表现更像FC-NVMe,因为它们在I/O中使用了消息语义。
RDMA
该规范采用远程直接内存访问(RDMA),使数据和内存能够在计算机和存储设备之间跨网络传输。RDMA是一种在网络中两台计算机的主存储器之间交换信息的方式,不涉及任何一台计算机的处理器、缓存或操作系统。由于RDMA避开了操作系统,因此它通常是网络传输数据的最快、开销最低的机制。
RDMA上的NVMe-oF使用TCP传输协议在IP网络上传输数据,典型的RDMA实现包括虚拟接口架构、聚合以太网上的RDMA(RoCE)、InfiniBand、Omni-Path和iWARP。RoCE、InfiniBand和iWARP是目前使用最多的。
将NVMe-oF与RDMA、光纤通道或TCP一起使用,就可以形成一个完整的端到端NVMe存储解决方案。这些解决方案提供了显著的高性能,同时保持了通过NVMe提供的极低延迟。
今天,NVMe由于其低延迟和高吞吐量的多任务处理速度而变得越来越受欢迎。虽然NVMe也用于个人计算机中以改进视频编辑,游戏和其他解决方案,但通过NVMe-oF在企业中可以看到真正的好处,特别是在分秒必争的企业场景。如实时客户互动,人工智能 (AI)、机器学习 (ML)、大数据和高级分析应用开发运营等。处理和访问数据的速度越快,对业务就越能带来价值。
尊敬的读者
说到NVMe对于机器学习的重要作用
您是否正在为机器学习
生命周期各个阶段细粒度追踪而发愁呢?
下面这个课程
正是为您准备的
戴尔科技精品课
特别带来AI培训课程系列
本次课程
由戴尔科技集团中国研究院
顶级专家团队
为您深入讲解
机器周期学习自动化
的相关内容
欢迎扫描下图二维码
参加我们的课堂

相关内容推荐:SCM渐入舞台,什么应用最需要它?
相关产品:全新 Precision 5750 17英寸移动工作站