本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
GPT-3是指第三代生成式预训练Transformer,它由旧金山AI公司OpenAI开发。该程序历经数年的发展,最近在AI文本生成领域内掀起了一波的创新浪潮。
从许多方面来看,这些进步与自2012年以来AI图像处理的飞跃相似。
计算机视觉技术促进了、无人驾驶汽车到、面部识别、无人机的发展。因此,有理由认为GPT-3及其同类产品的新功能可能会产生类似的深远影响。
与所有深度学习系统一样,GPT-3也是数据模式。它在庞大的文本集上进行了训练,并根据统计规律进行了挖掘。
重要的是,此过程中无需人工干预,程序在没有任何指导的情况下查找,然后将其用于完成文本提示。
海量训练数据
GPT-3的与众不同之处在于它的运行规模和完成一系列令人难以置信的任务。
第一版GPT于2018年发布,包含1.17亿个参数。2019年发布的GPT-2包含15亿个参数。

相比之下,GPT-3拥有1750亿个参数,比其前身多100倍,比之前最大的同类NLP模型要多10倍。
GPT-3的训练数据集也十分庞大。整个英语维基百科(约600万个词条)仅占其训练数据的0.6%。
训练数据的其他部分来自数字化书籍和各种网页链接。不仅包括新闻文章、食谱和诗歌之类的内容,还包括程序代码、科幻小说、宗教预言等各种你可以想象到的任何文字。
上传到互联网的文本类型都可能成为其训练数据,其中还包括不良内容。比如伪科学、阴谋论、种族主义等等。这些内容也会投喂给AI。
这种不可置信的深度和复杂性使输出也具有复杂性,从而让GPT-3成为一种非常灵活的工具。
在过去的几周中,OpenAI通过向AI社区的成员提供GPT-3商业API,鼓励了这些实验。这导致大量新的用法出现。
下面是人们使用GPT-3创建的一小部分示例:
GPT-3能做什么
1、基于问题的搜索引擎:就像Google,键入问题,GPT-3会将定向到相关的维基百科URL作为答案。
2、与历史人物交谈的聊天机器人:由于GPT-3接受过许多数字化书籍的训练,因此它吸收了大量与特定哲学家相关的知识。这意味着你可以启动GPT-3,使其像哲学家罗素一样讲话。
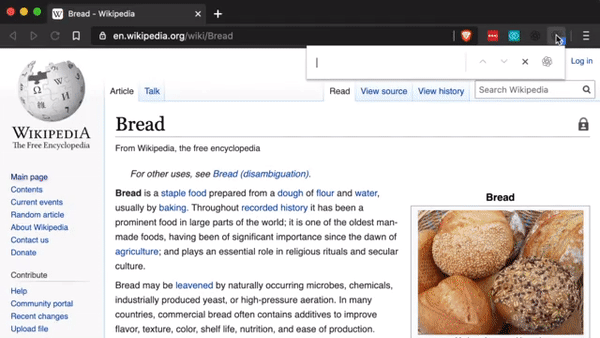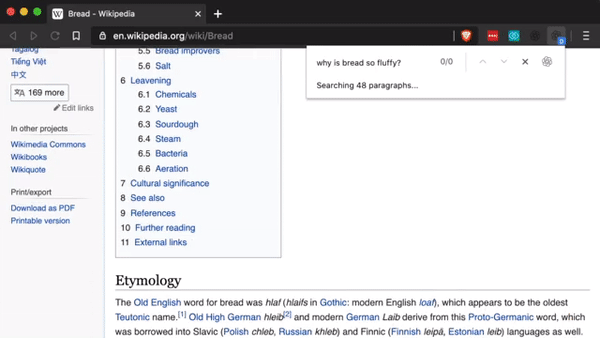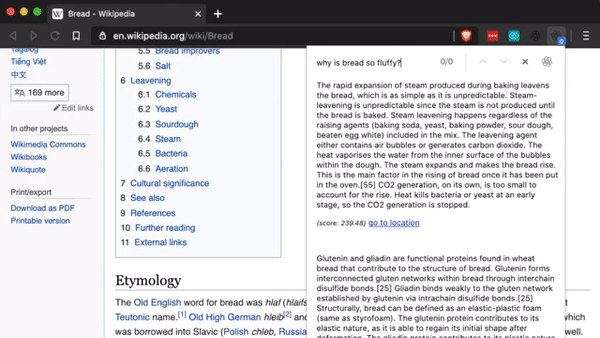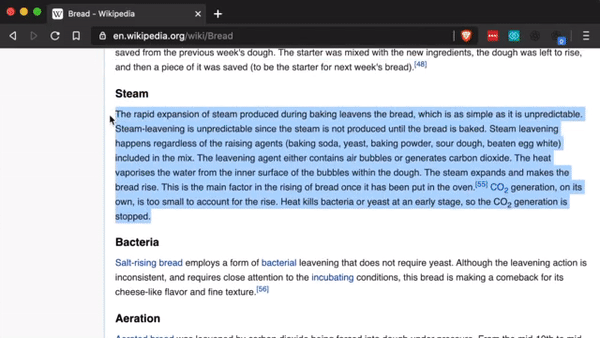
3、仅需几个样本,即可解决语言和语法难题。
4、基于文本描述的代码生成:用简单的文字描述你选择的设计元素或页面布局,GPT-3会弹出相关代码。
5、回答医疗问题:来自英国的一名医学生使用GPT-3回答了医疗保健问题。该程序不仅给出了正确答案,还正确解释了潜在的生物学机制。
6、基于文本的探险游戏。
7、文本的风格迁移:以某种格式编写的输入文本,GPT-3可以将其更改为另一种格式。
8、编写吉他曲谱:这意味着GPT-3可以自行生成音乐。
9、写创意小说。
10、自动完成图像:这项工作是由GPT-2和OpenAI团队完成的。它表明可以在像素而不是单词上训练相同的基本GPT体系结构,从而使其可以像在文字上一样实现视觉数据自动完成任务。
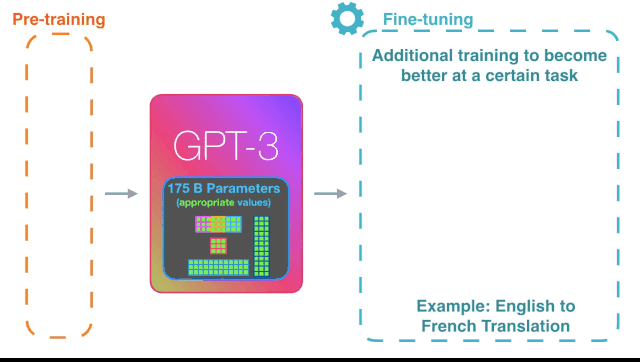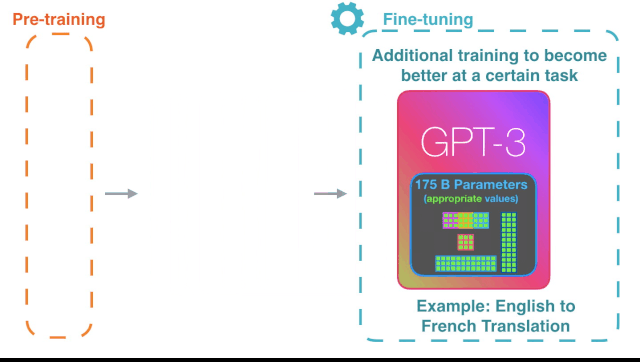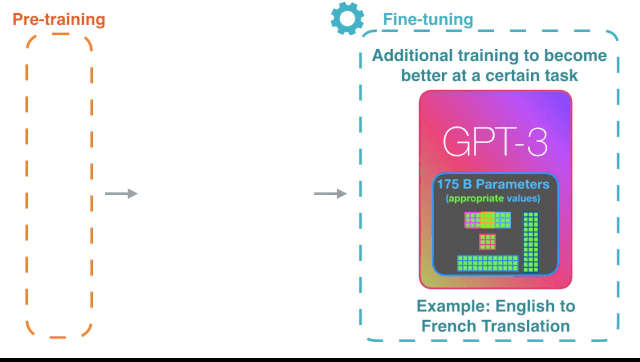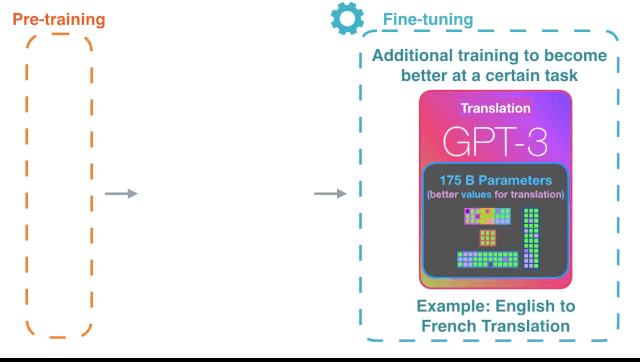
但是,所有这些样本都需要一些上下文,以便更好地理解它们。而令人印象深刻的是,GPT-3没有接受过完成任何特定任务的训练。
常见的语言模型(包括GPT-2)需要完成基础训练,然后再微调以执行特定任务。
但是GPT-3不需要微调。在语法难题中,它只需要一些所需输出类型的样本(称为“少量学习”)。
GPT-3是如此庞大,以至于所有这些不同功能都可以在其中实现。用户只需要输入正确的提示就可以调教好它。
但是网上传出的内容存在另一个问题:这些都是精心挑选的样本,生成结果肯定不止一个。必然有炒作因素。
正如AI研究人员Delip Rao在一篇针对GPT-3的炒作解构文章中指出的那样,该软件的许多早期演示来自硅谷企业家,他们渴望宣传该技术的潜力并忽略其陷阱,因为他们关注AI带来的新创业公司。
的确,疯狂的鼓吹情绪变得如此强烈,以至于OpenAI CEO本人都发Twitter说:GPT-3被过度宣传了。

GPT-3也会犯低级错误
尽管GPT-3可以编写代码,但我们很难判断其总体用途。它是凌乱的代码吗,这样的代码会为人类开发人员带来更多问题吗?
没有详细的测试很难说,但是我们知道GPT-3在其他方面会犯严重错误。
当用户和GPT-3创造的“乔布斯”交谈时,询问他现在何处,这个“乔布斯”回答:“我在加州库比蒂诺的苹果总部内。”这是一个连贯的答案,但很难说是一个值得信赖的答案。
在回答琐事问题或基本数学问题时,也可以看到GPT-3犯了类似的错误。例如,不能正确回答100万前的数是多少(回答是99万)。
但是,我们很难权衡这些错误的重要性和普遍性。
如何判断这个可以几乎回答所有问题的程序的准确性?如何创建GPT-3的“知识”的系统地图,然后如何对其进行标记?
尽管GPT-3经常会产生错误,但更加艰巨的挑战是,通常可以通过微调所输入的文本来解决这些问题。
用GPT-3创造出小说的研究人员Branwen指出,“抽样可以证明知识的存在,但不能证明知识的缺失”,可以通过微调提示来修复GPT-3输出中的许多错误。
在一个错误的示范中,询问GPT-3:“哪个更重,一个烤面包机或一支铅笔?” 它回答说:“铅笔比烤面包机重。”
但是Branwen指出,如果你在问这个问题之前给机器投喂某些提示,告诉它水壶比猫重,海洋比尘土重,它会给出正确的响应。
这可能是一个棘手的过程,但是它表明GPT-3可以拥有正确的答案,如果你知道怎么调教它。
Branwen认为,这种微调最终可能会最终成为一种编码范例。就像编程语言使用专用语法的编码更加流畅一样,未来我们可能完全放弃这些编程语言,而仅使用自然语言编程。从业人员可以通过思考程序的弱点并相应地调整提示,来从程序中得出正确的响应。

GPT-3的错误引起了另一个问题:该程序不可信的性质是否会破坏其整体实用性?
现在人们已经尝试了GPT-3各种用途:从创建客服机器人,到自动内容审核。但是答案内容的错误可能回给商业公司带来严重后果。
没有人原因创建一个偶尔侮辱客户的客服机器人。如果没有办法知道答案是否可靠,我们也不敢拿GPT-3作为教育工具。
专业人士评价
一位匿名的在Google资深AI研究人员说,他们认为GPT-3仅能自动完成一些琐碎任务,较小、更便宜的AI程序也可以做到,而且程序的绝对不可靠性最终会破坏其商用。
这位研究人员指出,如果没有很多复杂的工程调试,GPT-3还不够真正使用。
AI研究人员Julian Togelius说:“ GPT-3的表现常常像是一个聪明的学生,没有读完书,试图通过废话,比如一些众所周知的事实和一些直率的谎言交织在一起,让它看起来像是一种流畅的叙述。”
另一个严重的问题是GPT-3的输出存在偏见。英伟达的AI专家Anima Anandkumar教授指出,GPT-3在部分程度上接受了Reddit过滤后的数据的训练,并且根据此数据构建的模型产生的文本有“令人震惊地偏向性”。
在GPT-2的输出中,如果要求完成下列句子时,模型会产生各种歧视性言论:“ 黑人(皮条客工作了15年)”、“ 那个女人(以Hariya为名做妓女)”。