【51CTO.com快译】作为一款分析平台,Snowflake数据仓库(Data Warehouse)以其超快的查询性能蜚声于业界。不过,我们对Snowflake既无法建立索引,又不可捕获统计信息,更无法管理分区。那么,您该如何优化Snowflake数据库,以达到更好的查询性能呢?本文将介绍有关如何将系统调整到最大吞吐量的三个主要方面,即:数据提取、数据转换和最终用户的查询。
影响Snowflake查询性能的因素
作为技术人员,我们经常需要在对问题不甚了了的情况下,提出并实施解决方案。那么总的说来,我们在分析平台上的性能问题时,通常会从如下三个方面入手:
i. 数据的加载速度:应具有能够快速加载大量数据的能力。
ii. 数据的转换:应具有最大化吞吐量,并将原始数据快速地转换为适合查询格式的能力。
iii. 数据的查询速度:能够最大程度地减少每次查询的延迟,并尽快将结果提供给商业智能用户。
1.Snowflake的数据加载
避免扫描文件
下图展示了将数据批量加载到Snowflake处的最常见方法。该方法主要是将数据从本地(on-premise)系统传输到云端存储,然后使用COPY命令加载到Snowflake中。
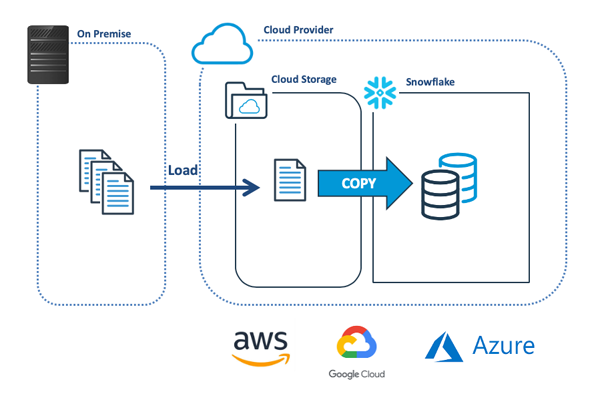
那么在复制数据之前,Snowflake会检查文件是否已被加载。这是通过限制针对某个特定目录的COPY,来实现最大化加载性能的第一种、也是最简单的方法。如下代码段展示了一系列COPY操作。
SQL
-- Slowest method: Scan entire stage
copy into sales_table
from @landing_data
pattern='.*[.]csv';
-- Most Flexible method: Limit within directory
copy into sales_table
from @landing_data/sales/transactions/2020/05
pattern='.*[.]csv';
-- Fastest method: A named file
copy into sales_table
from @landing_data/sales/transactions/2020/05/sales_050.csv;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
可见,最快捷的方法是:命名一个特定的文件,并用通配符来体现其灵活性。当然,我们也可以在加载完毕后立即删除目标文件。
调整虚拟仓库和文件的大小
下图展示了:在将大型数据文件加载到Snowflake中时,设计人员往往趋向于扩展出更大的虚拟仓库,以加快整个加载过程。这是一个常见的误区。实际上,在这种情况下,给仓库扩容并不会带来任何性能上的优势。
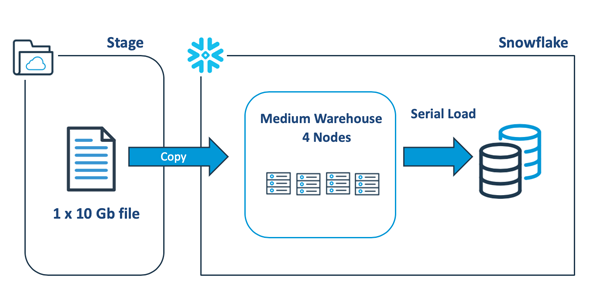
也就是说,上面的COPY语句将打开一个10 Gb的数据文件,并使用某个线程在一个节点上顺次加载数据,而其余的服务器则保持为空闲的状态。通过基准测试,我们发现:通常情况下,加载的速率约为每分钟9 Gb。我们可以设法提高该速度。
下图给出了一种更好的方法--将单个10Gb文件分解为100个100 Mb的文件,以充分利用Snowflake的自动化并行处理功能。
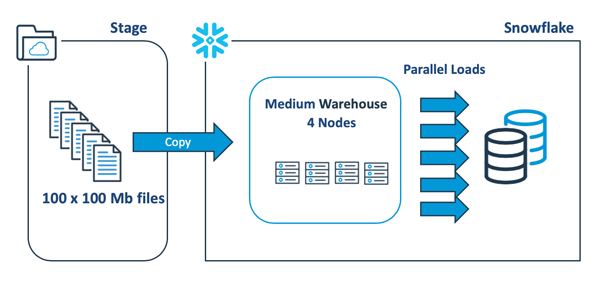
2.Snowflake的转换性能
延迟与吞吐量
虽然优化SQL是减少时间开销的最有效方法,但是设计人员通常不太好把握时机。除了减少单个查询的延迟,最大化吞吐量(即:在尽可能短的时间内实现数据交付的最大化)也是非常重要的。
下图展示了典型的数据转换模式,该模式会在虚拟仓库中执行一系列的批处理作业。只有在前一项任务完成时,后一项任务才会开始:

我们很容易想到的解决方案是:将其扩展到更大的虚拟仓库中,以更快地完成作业任务。不过,该方案往往会受到硬件资源的极限限制。此外,虽然此举能够提高查询的性能,但是也会造成大量仓库资源未被充分利用。
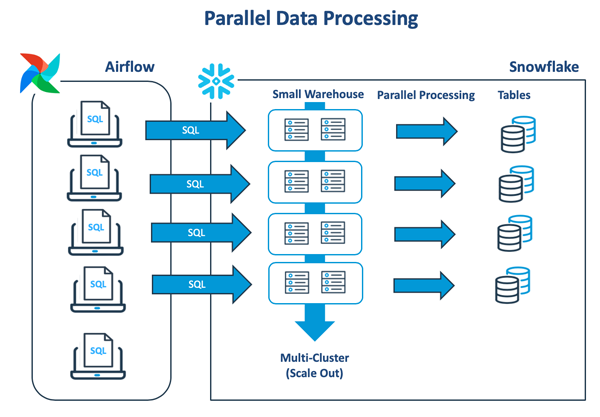
如上图所示,Apache Airflow可被用于执行与Snowflake的多个独立连接。其中,每个线程会针对同一虚拟仓库去执行单个任务。随着工作量的增加,如果可用资源出现不足的情况,作业任务就会开始排队。为了分担负载,我们可以将Snowflake的多集群功能,配置为能够自动创建另一个相同大小的虚拟仓库。
完成任务后,上述解决方案还会自动缩小为单个群集,并且能够在完成了最长的作业后,将群集挂起。目前为止,这是获取自动扩展与收缩能力的最有效方法。
如下SQL代码段展示了创建多集群仓库所需的命令,该仓库将在60秒钟的空闲时间后自动挂起。我们通过ECONOMYE扩展策略,来提高吞吐量,并节省单个查询的等待时间。
SQL
-- Create a multi-cluster warehouse for batch processing
create or replace warehouse batch_vwh with
warehouse_size = SMALL
min_cluster_count = 1
max_cluster_count = 10
scaling_policy. = economy
auto_suspend. = 60
initially_suspended = true;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
3.调整Snowflake的查询性能
选择必要列
与许多其他数据分析平台类似,Snowflake也用到了列式数据存储。如下图所示,该存储被优化为仅获取那些特定查询所需的属性,而非所有列:
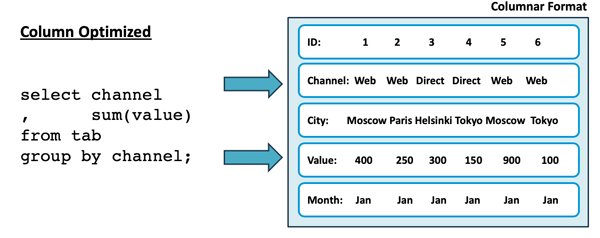
在上图中,该查询只是在上百个列的表中获取了其中的两列。而传统的行存储则需要从磁盘中读取所有列的数据。显然,前者的效率要高出许多。
最大化缓存使用率
下图展示了Snowflake内部架构的重要组成部分,它能够在虚拟仓库和云端服务层之间缓存数据。
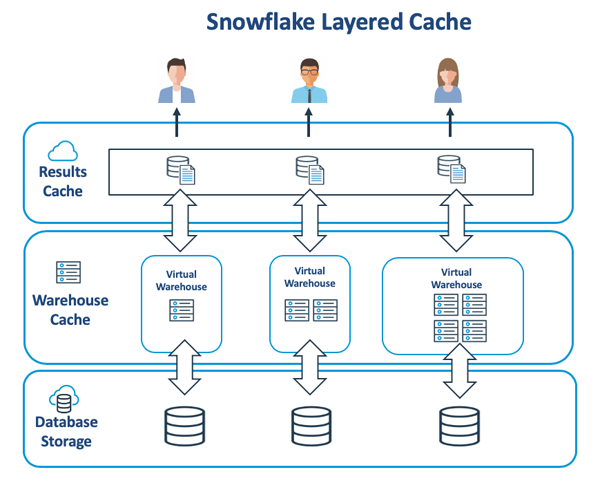
商业智能仪表盘可以通过对同一查询的重新执行,以刷新并显示被更改以后的数据值。Snowflake通过返回最近24小时内查询到的结果缓存(Results Cache)中的内容,来实现对此类查询的自动化调优。
虽然数据也会被缓存到快速SSD(固态硬盘)上的虚拟仓库中,但是不同于上述提到的结果缓存,虚拟仓库是基于最近、最少使用原则,来保存原始数据,因此此类数据很可能已经过期了。不过,我们虽然无法直接调整虚拟仓库中的缓存内容,但是可以通过如下步骤进行优化:
- 获取所需的属性:避免在查询中使用SELECT *,毕竟这会将所有数据的属性,从数据库存储(Database Storage)中全量获取到仓库缓存(Warehouse Cache)中。此举不仅速度缓慢,而且还可能导致那些不需要的数据也被填充到了仓库缓存中。
- 扩容:我们虽然应该避免通过扩容的方式,来应对特定的查询,但是我们需要通过调整仓库本身的大小,以提高整体的查询性能。那些新增的服务器既可以分散突发任务的负担,又能够有效地增加仓库缓存的大小。
- 考虑数据集群:对于大小超过TB的数据表而言,请考虑通过创建集群键(cluster key,请参见--https://www.analytics.today/blog/tuning-snowflake-performance-with-clustering)的方式,最大程度地消除分区(partition)。此举既可以提高单个查询的性能,又可以返回较少的微分区(micro-partitions),从而充分地使用到仓库缓存。
SQL
-- Identify potential performance issues
select query_id as query_id
, round(bytes_scanned/1024/1024) as mb_scanned
, total_elapsed_time / 1000 as elapsed_seconds
, (partitions_scanned /
nullif(partitions_total,0)) * 100 as pct_table_scan
, percent_scanned_from_cache * 100 as pct_from cache
, bytes_spilled_to_local_storage as spill_to_local
, bytes_spilled_to_remote_storage as spill_to_remote
from snowflake.account_usage.query_history
where (bytes_spilled_to_local_storage > 1024 * 1024 or
bytes_spilled_to_remote_storage > 1024 * 1024 or
percentage_scanned_from_cache < 0.1)
and elapsed_seconds > 120
and bytes_scanned > 1024 * 1024
order by elapsed_seconds desc;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
上面的SQL代码段可以帮助我们识别出,那些运行超过了2分钟,并已经扫描了1兆数据量的查询性能问题。如下两个方面特别值得我们的关注:
- 表扫描:在大型数据表中,如果PCT_TABLE_SCAN的值比较高,或MB_SCANNED的量比较大,则都表明查询的选择性比较差。因此,我们需要检查查询中的WHERE子句,并适当地考虑使用集群键。
- 溢出:SPILL_TO_LOCAL或SPILL_TO_REMOTE中的任何值,都表明系统在小型虚拟仓库上进行了大型的操作。因此,我们需要考虑将查询移至更大的仓库中,或适当地对现有的仓库进行扩容。
总结
业界关于Snowflake的一个常见误解是:直接扩容出更大的仓库,是提高查询性能的唯一方案。但这实际上并不一定是绝好的策略。我们需要厘清问题到底是发生在获取数据环节、还是数据转换部分、亦或最终用户的查询中。毕竟设计出可扩容的大型仓库,要比单纯的查询调整,更适合提高数据库的查询性能。
原标题:Top 3 Snowflake Performance Tuning Tactics ,作者: John Ryan
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】