













作者简介
顾黄亮,十年研发运维经验,涵盖基础架构、应用架构、数据库、DevOps,有互联网,电商,金融从业经历。专注于 DevOps 在企业中的应用和落地,致力于企业智慧运维体系的打造。
参加多个行业、国家标准的编写,《开源许可证使用指南(2018)》作者之一,国标《研发运营一体化(DevOps)能力成熟度模型》作者之一,《企业IT运维发展白皮书》作者之一,曾供职于航天晨光、上汽集团云计算中心,现任苏宁消费金融安全运维部负责人。
前言
在数据的输出和变现的过程中,场景化作为最终落地的载体,而运维数据的输出和变现能力最终还是依靠前期的数据建设和质量管理,本文中,我们着重对运维领域的数据建设和管理进行展开,来描述运维数据的管理方式。
一、运维数据的变现历程
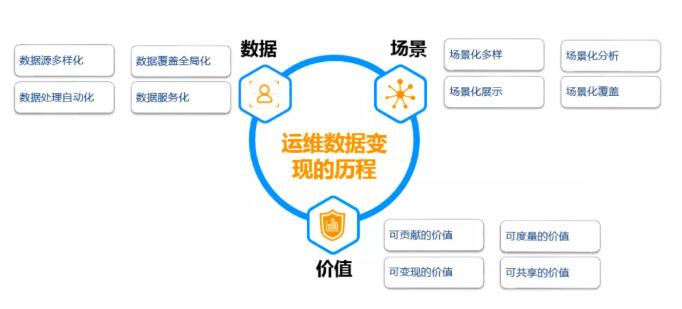
运维数据的规模和企业规模、业务形态和运维能力有很大的关系,根据信通院的《企业IT运维发展白皮书》中所述,企业规模越大、业务形态越复杂、运维能力越高的企业,运维所纳管的数据越多,运维数据变现的效果越好,相对应的,运维数据建设的层次越高,通常使用较为前沿的大数据和AI技术作载体来进行数据的价值交付。典型场景为,知识图谱、智能监控、动态阈值、根因分析和故障自愈。
在企业规模较小、业务形态较为单一、运维能力较为一般的企业,运维数据变现较弱,更多的数据输出强依赖场景,因此在这个阶段,场景成为运维数据的唯一突破口,主要进行数据的被动采集、被动存储和被动消费,特征为数据割裂和数据关联性较弱,典型的场景化驱动主要为,资源管理、基础架构监控、业务连续性保障和应急知识库。
在运维数据的变现过程中,一般需要关注三个阶段,数据由少到多、单维到多维、覆盖面由内到外的阶段;数据处理由简单到复杂、技术单一到多样化的阶段;场景由基于需求到基于规划、输出能力由浅到深、自动化到智能化的阶段,总的概括如下。
1、从数据获取渠道出发,由少到多
在初级阶段,运维数据来源局限于运维侧自身,如资源数据、监控数据、文本数据、日志数据,随着数据源接入进入全覆盖的时候,运维数据已经覆盖业务运营数据、后台支撑数据、财务数据。需要说明的是,运维数据的获取离不开运维数据输出的强依赖条件,那就是场景输出的需要,一切数据的根本都要基于运维能力输出。
2、数据处理的能力决定了数据价值的范围,覆盖面由内到外
在这里,很多人可能疑惑,这不是大数据做的事吗?说到底,大数据只是一个工具,而非一个职能,因此运维数据处理的能力与否,决定了数据汇聚层的价值模型,也间接的影响数据输出的覆盖场景,这也就是我们所理解的运维数据中台。在这期间,重点要做的是数据的处理能力和数据的衍生能力。
3、有价值的场景化选型决定了数据变现能力,变现能力由浅到深
在我们所理解的变现过程中,其实是最终的价值输出模型,最终也会得到三个结果,优化、反馈和贡献价值。因此,有价值的场景化选型也必须遵照,从运维内部的优化开始,到信息科技领域的度量反馈(《建立数据指标体系,推动 DevOps 全链路度量闭环》一文详细阐述),最后到数据衍生体系的贡献价值,例如智慧运维、项目后评价体系、信息科技的成本复盘、成本中心的利润测算。
下面通过一张图可以通俗的理解。
二、运维数据的管理
做过数据项目的都知道,数据项目的建设是一个循序渐进、持续优化的过程,不可一蹴而就,运维数据的管理也是如此,和业务数据不同,运维数据较为难找,且离散。一般来说,运维数据的管理一般经历四个过程,简单归结为:找数据、建模型、接数据、抓变现。
1、数据的寻找
在运维的数据体系构建过程中,找数据是个很头痛的问题,这点和业务的数据体系有很大的区别,业务数据的管理大都由前置目标驱动,而运维数据的管理大都由后置目标驱动,这就造成找数据阶段需要自上而下进行数据的梳理和调研。这个特性和运维的职能相关,在运维领域,安全、稳定、高效和低成本是运维的能力输出框架,前两个和数据低耦合,而后两个和数据高耦合。
参考数据资源普查的方法,因运维输出场景的后置性只能采取自上而下的方式,而自上而下的方式一般会用到 IPR(信息资源规划)。关于IPR的描述是这样的,信息资源规划(Information Resource Planning ,简称 IRP),是指对所在单位信息的采集、处理、传输和使用的全面规划。其核心是运用先进的信息工程和数据管理理论及方法,通过总体数据规划,奠定资源管理的基础,促进实现集成化的应用开发,构建信息资源网。
这里通过运维语言进行拆解,简单的说,根据运维数据的价值输出模型可以这样描述。我们也可以从“初态、终态和去处”三个维度来解读,在运维数据的梳理范围过程中,通常会扩大到各种系统配置信息、监控系统采集的系统数据、指标数据、固定阈值或动态阈值产生的复杂告警信息、以及各种系统定义的五花八门的海量日志数据等等。而随着运维能力输出的泛化,开发和运维的边界上的模糊和融合,以及大数据技术的发展,运维数据和生产数据的边界也不再那么清晰,如公司业务的用户点击数据既属于运维数据的范畴也是业务数据的重要组成。
随着业务的发展,运维数据在阶段性过程中产生了爆发式的增长,可惜的是,运维数据的消费方式还是通过竖井式的方案,以不同的系统分别处理,主要还是展现给 DevOps 或其他使用人员来进行决策。
例如,监控系统以获取监控数据为始,以输出规则定义的告警信息给使用人员为终;日志系统已获取和索引日志内容信息为始,以提供复杂的搜索和内容展现给使用人员为终。运维数据的价值挖掘受制于孤立的运维系统的处理能力和运维人员自身的“带宽”。因此,我们通过IPR找数据的过程中,会形成一个误区,总是站在运维的角度来找数据,最终找到的都是掐头去尾的数据,下面我们通过简单的一张图来描述,如何找数据。
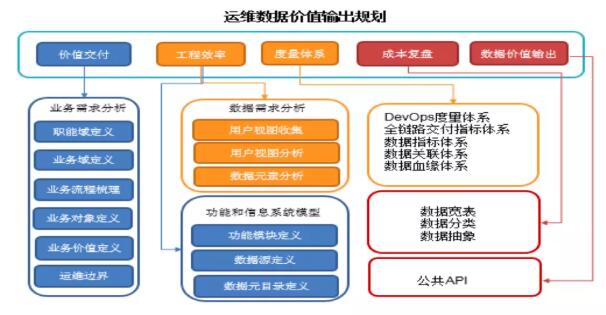
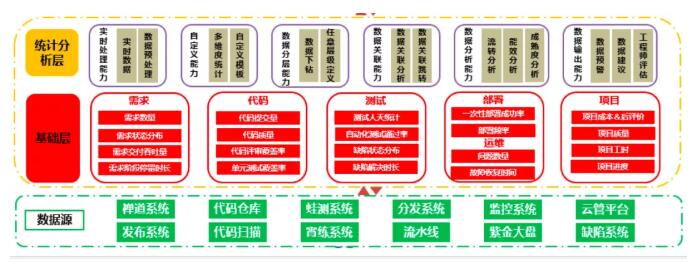
在这个阶段通常是运维工具化一切的阶段,而自上而下的梳理方式更能够对现有数据资源有全面、系统的认识。特别是通过对数据职能域之间交叉信息的梳理,使我们更加清晰地了解到数据信息的来龙去脉,有助于我们把握各类信息的源头,有效地消除“信息孤岛”和数据冗余、控制数据的唯一性和准确性,确保获取信息的有效性。在找数据的同时,也可以助推工具化的进一步查漏补缺和优化,下图为常见的一些数据源。
2、数据的模型
数据模型的阶段对于运维领域来说,体现在数据识别方面。在传统的数据模型理论中,运维数据并没有明确的操作数据层、明细数据层、汇总数据层和应用数据层的划分,这是运维边界所造成。在模型建设过程中,更多的是基于数据的特征来考量,主要有如下几点:
- 运维数据的业务价值,如偏业务连续性的运维数据。
- 运维数据的共享,此部分的数据主要用来和业务系统之间进行共享的数据,如组织数据、技术组件数据、框架配置数据。
- 运维数据的实体独立性,主要体现在资产管理和容量管理。
- 运维数据的唯一识别,这是运维数据形成网状拓扑的核心能力,一般以CMDB为基准,采取多节点衔接延伸的方式,如基于业务系统的IP进行南北向的资产数据拓扑扩展,基于员工的工号进行东西向工程效率和人效的度量。
- 运维数据的长期有效性,运维数据模型的基本要素,主要用于数据基线、链路基线、容量成本基线。
在模型阶段,由于运维数据独特性,污染比较严重,质量也良莠不齐,所以治理和验证的过程是一个难题。主要体现在运维数据的强即时性方面,某些基础架构故障会引发一连串的系统级和业务级的故障,在业务较为复杂的情况下,这部分数据的污染性更为动态和复杂,因此需要模型具备一定的降噪和治理能力。
3、数据的接入和接出
运维数据的接入主要为工具数据的接入,较为常见的数据来源为资产管理数据和运维自动化工具所留存的数据,而工具留存的数据存在较多的不确定性,如数据保存方式不同、数据标签不同、数据定义不同、数据管理方式不同,因此需要在接入层对数据进行加工和清洗。
数据接入是将数据从数据源系统汇集到数据平台的过程。该过程需要对接入的数据进行清洗、转换、映射、去重、合并、加载,通过一系列的数据加工和处理形成标准统一的主数据。常用的数据汇集方式包括:(1)ETL抽取,采用ETL工具的方式从数据源系统将数据采集到运维数据数据中台。(2)文件传输,采用文件传输方式将文件中的数据导入到运维数据数据中台。(3)消息推送,采用消息的方式从数据源系统将数据采集到运维数据数据中台。(4)接口推送,采用接口方式从数据源系统将主数据采集到运维数据数据中台。(5)内容爬虫,一般用于WEB页面的数据爬取,适用于无数据留存场景的汇集。
运维数据的接出,是将标准化的数据分发共享给下游系统使用的过程。在数据接出过程中使用的技术与数据汇集技术基本一致。在运维侧实施数据接出过程中,需要根据不同场景选择不同的集成方式。

在此有几个大家都比较关心的问题需要探讨,运维数据中台是否需要将CMDB、监控平台、流水线、持续交付、度量体系的数据集中到一起,这是运维中台在建设过程中遇到的第一个问题。数据的接入过程其实是多源的运维数据导入过程,其中未必所有的数据都是有用的,监控数据和日志平台是典型的代表。
在此期间,接入的运维数据往往存在大量的重复和冗余,以监控数据为例,同一个事件可能导致大量重复的指标、告警、日志等,笔者在实施过程中将更接近数据源的位置及早过滤冗余,这不仅会节省时间,而且也能够节省用在冗余的垃圾数据上的存储和计算成本。
因此,比较理想的方案是在临近数据源的地方进行实时数据处理,尽早进行降噪和聚合,完成自动模式发现、异常检测等算法,只把具备历史分析价值的数据流传到数据中台进行历史分析。总体来说,如果我们使用主数据和元数据的概念来便于理解,运维能力子域的工具和系统所留存的数据为主数据范畴,而数据中台的数据为元数据范畴,二者的关系更多的通过单维到多维来识别。
回到数据集中的问题,笔者在实施过程中,CMDB、监控平台、流水线、持续交付、度量体系的数据依旧维持原状,接入的数据保持按需接入的同时,更多的体现在多个数据源的多维度的海量异构数据。
4、数据的变现
数据的变现是实现数据价值的唯一标准,和数据的商业化不同,运维数据的变现主要取决于数据的热点运用,使用的热度越高,越是黄金数据,也可以称为核心数据资产。在运维领域,数据的变现主要有以下方面。
(1)整体协同、降本增效
提升组织级的能效和质量是 DevOps 的价值输出唯一标准,因此通过数据驱动的方式来达到端到端的流水线交付、端到端的资源交付、端到端的安全输出、端到端的价值交付。在这个期间,需要运维数据标准统一,来打通项目、需求、研发、测试、运维和资源的各个环节,大幅提升科技各子域的协作效率,减少因数据不一致导致数据传递交换的沟通成本。
(2)数据驱动、智能决策
在数据驱动阶段,通过数据的反馈来优化价值交付链路过程中的问题和缺陷,通过对过程性数据的持续收集和分析发现交付过程中存在的瓶颈,通过对软件产品和用户的线上数据获取反馈并且及时作出调整,通过结果性数据去评价团队的成效。从而体现数据价值输出能力和决策成效。
(3)数据即服务、资产
可以通过数据的不断优化来提升数据共享和交换能力,另一方面,通过对数据进行标签化和整合,结合各种不同的场景输出提供给数据使用部门,从而实现整个企业级的全局数据打通。
三、总结
随着运维的技术发展不断加快,职能边界也逐渐模糊,随之而来的不光是数据的量级呈现几何级的增长,业务连续性的容忍性也趋于变窄。因此运维数据所凸显的价值输出能力得到进一步的提高,对于数据的使用和管理给运维带来了新的困难和挑战,相应的也促使智能运维的出现和发展,提前预告下一篇,运维数据的质量管理。























