













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
是否还记得前阵子爆火的SM娱乐公司电子屏海浪?

人工制作那样的特效,可能需要花费……嗯,毕竟被称为「每滴水都是粉丝贡献的钱」。
但现在,DeepMind和斯坦福等一众科学家研究出了一款图网络模拟器——GNS框架,AI只需要“看着”场景中的流体,就能将它模拟出来。
无论是流体、刚性固体还是可变形材料,GNS都能模拟的惟妙惟肖。研究人员还称:
GNS框架是迄今为止最精确的通用学习物理模拟器。
并且,这项研究最近还被顶刊 Science 收录。

这也不禁让人联想起,清华姚班毕业生胡渊鸣开发的太极 (Taichi),不仅大幅降低了CG特效门槛,效果还是十分逼真。
而在 DeepMind 和斯坦福大学的这项工作中,胡渊鸣的太极,依然发挥了作用。
他们正是利用胡同学的太极,来生成2D和3D的挑战场景,作为基线效果之一。
效果好到什么程度?Science在社交网络评价说:

「好莱坞或许会投资这款模拟器吧」。
是你印象中的画面了
我们人类通过「经验」,说到一个场景时,能很快脑补出那种动态画面。
那么AI「脑补」出来的画面效果,是否和你想象的一样呢?
首先,是水落入玻璃容器中的3D效果。

和我们想象中的物理效果一模一样,有木有!
左侧的基线方法叫做SPH (smoothed particle hydrodynamics),这是1992年提出的一种基于颗粒的模拟流体的方法。
而右侧,AI通过「看」而预测得到的结果,就是研究人员提出来的GNS方法。
来看下二者在慢动作下的细节差异。

不难看出,GNS方法在细节处理上,例如溅起的水花,更加细粒度,也更逼近我们印象中的样子。
当然,GNS不仅能够处理液体,还能够模拟其他状态的物体。
例如,颗粒状的沙子。

还有粘性的物体。

上面两个效果中的基线方法是MPM (material point method),1995年提出,适用于相互作用的可变形材料。
同样,在颗粒散落在玻璃容器壁上的细节上,GNS的预测结果更加符合现实物理世界的效果。
那么,如此逼真的效果是如何做到的呢?
图网络模拟器模拟流体
传统特效计算方法
此前,对于真实物体的模拟,需要通过大量计算来实现,上文中提到的MPM就是其中的一种。
这种方法被称为物质点法(Material Point Method),将一块材料离散成非常多的颗粒,并计算空间导数和求解动量方程。
经过胡渊鸣等人改进的MLS-MPM,模拟物体的速度有了很大的提升,相比于原来的MPM快了两倍左右。

除此之外,一种名为PBD的方法,可以计算模拟出一个方块漂浮在水上的动态效果;

而这两种方法之外,还有一种被叫做SPH的~~古老~~经典方法,用于计算生成水的3D特效。

相比于这些采用大量计算模拟出来的真实场景,如果用神经网络对它们进行训练,是不是能模拟出物体在真实场景中受到撞击的效果,而且和用这些方法生成的效果非常相似?
网友对这样的想法感到惊奇,毕竟,人脑对于流体或是物体撞击效果的模拟,并非通过大量力学计算得出,而是通过神经网络模拟的。
DeepMind在这样的想法上,采用了GNS对生成的这些模型进行训练,用于模拟物体在真实场景下的特效。
图网络预测物体特效
GNS模拟物体最根本的原理,是将一块体积不变的物体模型X,分散成许多颗粒,并通过一个模拟器sθ,转变成它受到撞击后的形态。
从下图可见,模拟器sθ的用处,是将这块流体输入到一个动力学模型dθ中,并将产生的一帧帧结果用于更新物体变形的过程。

只要模拟器更新的时间够快,我们看见的就是这块物体在玻璃盒中受到撞击、不断变形的样子。

△ 图右为模拟器生成的效果
关键来了,动力学模型dθ要怎么实现?
团队采用了“三步走”的方法,将模型分为编码器、处理器和解码器三部分。

一块物体经过编码器后,编码器会将物体中原本分散的各颗粒架构起来,组成一个“看不见的”图。
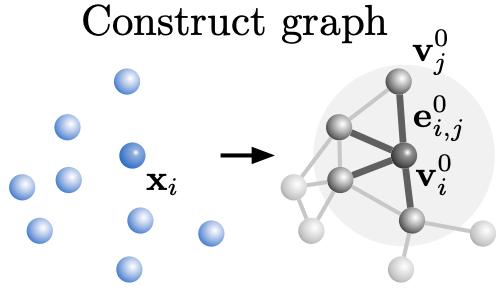
而在处理器中,图中各颗粒的关系会不断发生变化,图网络学习得到的传递信息将会在图上迭代M次。
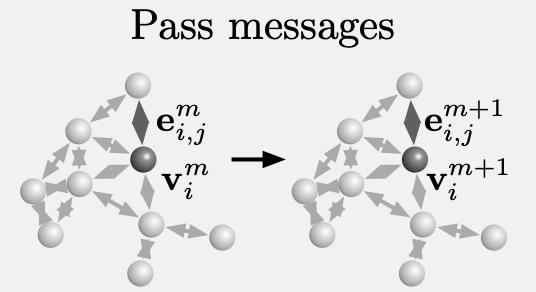
最后,解码器会将迭代好的动力学信息Y,从最后一次迭代出的图中提取出来。
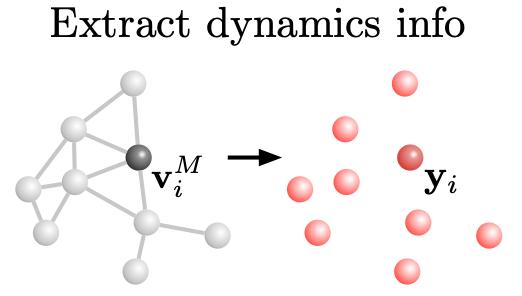
反馈回物体X上后,物体中的颗粒便能一进行一帧帧改变,连续起来就是模拟出的液体形态。
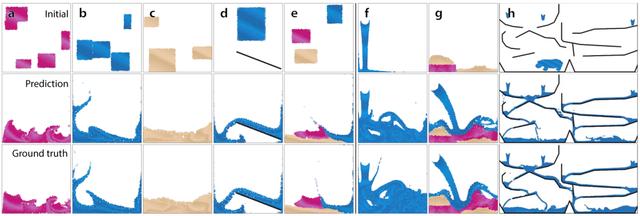
可以看见,无论是哪种物体形态,GNS预测的效果都与真值非常相近。
创新点
与之前一些模拟液体的神经网络相比,GNS最大的改进在于,它将不同的物体类型,转变成了输入向量的一个特征。
只需要将不同的物体类型(例如沙子、水、胶质物等)用不同特征区分,就能表现出它们的状态。
相比之下,此前一个名为DLP的、基于神经网络的液体模拟器,与GNS相比就过于复杂。
同样是模拟各种流体模型,DLP则需要不断地保存颗粒之间的相对位移,甚至需要修改模型来满足不同的流体类型——所需要的运算量过于庞大。
不仅如此,GNS的模拟效果竟然还比基于DLP的模拟器更好。
细节更出众
下面是GNS与一款基于DLP原理的增强版CConv模拟器的效果对比。
与CConv相比,GNS在不同物体类型的模拟表现上依旧非常优秀,下图是二者共同模拟一个漂浮在水上的方块时,所生成的效果。

可以看见,GNS生成的方块和真值一样,在水中漂浮自如;相比之下,CConv生成的方块直接在水的冲击下变了形(被生活击垮)。
如果采用与真实值相比的均方误差(MSE)进行对比的话,在各种物体形态下,GNS都要比CConv效果更佳。
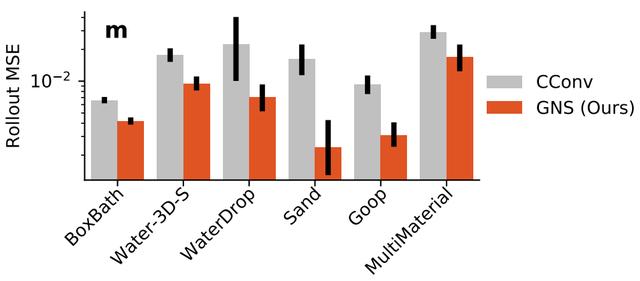
除此之外,下图展示了GNS分别采用强化学习中Rollout和One-step两种算法策略的均方误差效果。(以及迭代次数、是否共享GN参数、连接半径、训练噪声量、关联/独立编码器等)
可见,采取Rollout的效果(下半部分)在各方面都要比采取One-step的效果好得多。
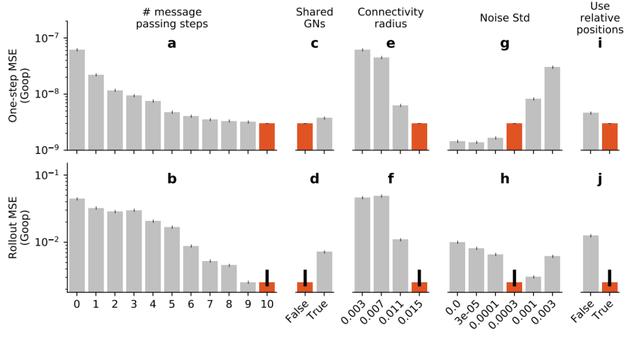
不仅如此,红色部分是GNS模型最终采用的策略,可见,所有策略都将均方误差降到了最低。
四位共同一作
这项研究主要由DeepMind和斯坦福大学合作。
论文的共同一作共四位。
△ Alvaro Sanchez-Gonzalez
Alvaro Sanchez-Gonzalez 本科和硕士攻读的专业分别是物理和计算机,基于这样的背景,在博士期间,他主要专注于使用计算机方法来解决物理研究中的一些挑战。
2017年加入谷歌DeepMind团队,研究主要集中在结构化方法、强化学习等。
△ Jonathan Godwin
Jonathan Godwin在2018年3月加入DeepMind,并于2019年11月晋升为高级研究工程师。
此前,他也有过自己创业的经历,分别是信息科技服务公司Bit by Bit Computer Consulting和金融公司Community Capital的CEO。
在创业后和加入DeepMind之前,他还在计算机软件公司Bloomsbury AI做了一年多的机器学习工程师。
△Tobias Pfaff
Tobias Pfaff 是DeepMind的一名研究科学家,从事物理模拟和机器学习的交叉研究。
分别在苏黎世联邦理工学院和加州伯克利分校,完成博士和博士后的学习任务。
△Rex Ying
第四位共同一作是Rex Ying,目前在斯坦福大学攻读博士学位,研究主要集中在开发应用于图形结构数据的机器学习算法。
2016年以最高荣誉毕业于杜克大学,主修计算机科学和数学两个专业。
……
最后,对于AI通过「看」来模拟如此复杂的流体运动,网友认为:
脑能模拟各种复杂运动,靠的就是神经网络,而不是复杂的力学公式。

不仅如此,这项技术或许还大幅降低影视、游戏行业特效成本。
那么,这样的技术,你看好吗?















