












整体架构最近看到了我在Github上写的rabbitmq-examples陆续被人star了,就想着写个rocketmq-examples。对rabbitmq感兴趣的小伙伴可以看我之前的文章。下面把RocketMQ的各个特性简单介绍一下,这样在用的时候心里也更有把握。
全网最全RabbitMQ总结,别再说你不会RabbitMQ
RocketMQ是阿里自研的消息中间件,RocketMQ的整体架构如下
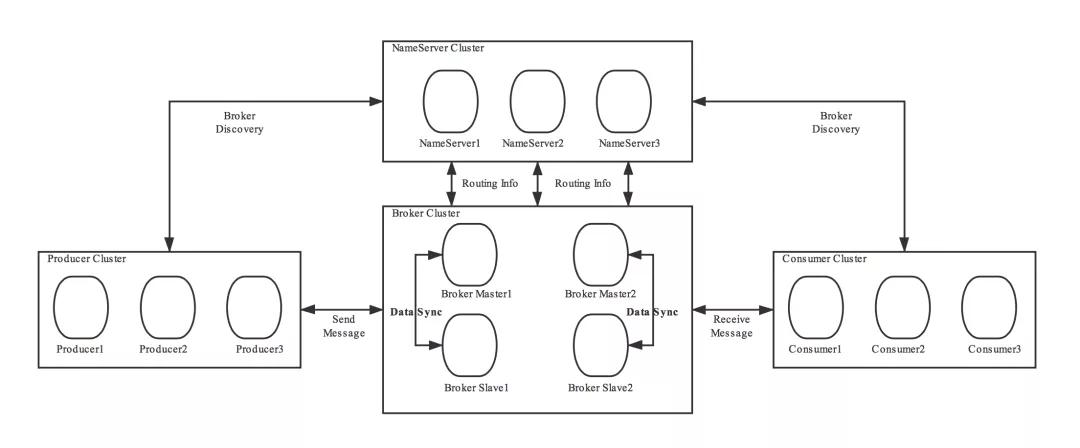
主要有4个角色
Producer:消息生产者。类似,发信者 Consumer:消息消费者。类似,收信者 BrokerServer:消息的存储,投递,查询。类似,邮局 NameServer:注册中心,支持Broker的动态注册与发现。类似,邮局的管理结构
再介绍几个基本概念
Topic(主题):一类消息的集合,Topic和消息是一对多的关系。每个Broker可以存储多个Topic的消息,每个Topic也可以分片存储于不同的Broker
Tag(标签):在Topic类别下的二级子类别。如财务系统的所有消息的Topic为Finance_Topic,创建订单消息的Tag为Create_Tag,关闭订单消息的Tag为Close_Tag。这样就能根据Tag消费不同的消息,当然你也可以为创建订单和关闭订单的消息各自创建一个Topic
Message Queue(消息队列):相当于Topic的分区,用于并行发送和消费消息。Message Queue在Broker上,一个Topic默认的Message Queue的数量为4
Producer Group(生产者组):同一类Producer的集合。如果发送的是事务消息且原始生产者在发送之后崩溃,Broker会联系统一生产者组内的其他生产者实例以提交或回溯消费
Consumer Group(消费者组):同一类Consumer的集合。消费者组内的实例必须订阅完全相同的Topic
Clustering(集群消费):相同Consumer Group下的每个Consumer实例平均分摊消息
Broadcasting(广播消费):相同Consumer Group的每个Consumer实例都接收全量的消息
用图演示一下Clustering和Broadcasting的区别
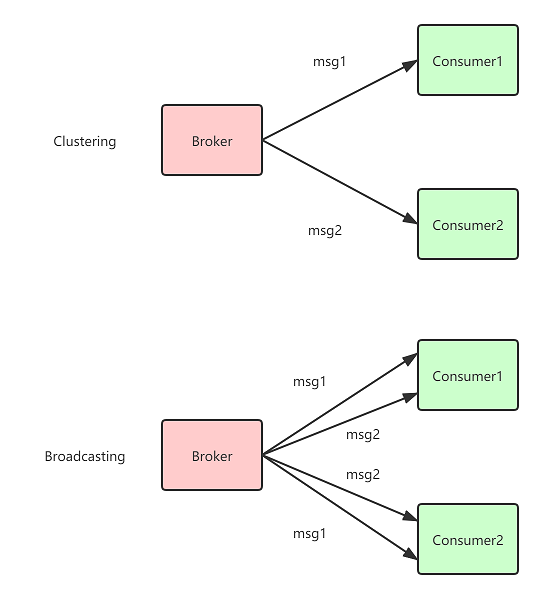
如果我有一条订单程成交的消息,财务系统和物流系统都要同时订阅消费这条消息,该怎么办呢?定义2个Consumer Group即可
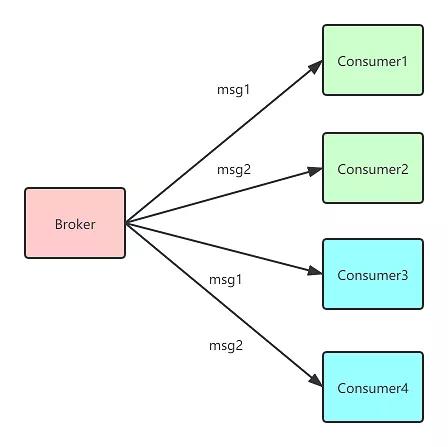
Consumer1和Consumer2属于一个Consumer Group,Consumer3和Consumer4属于一个Consumer Group,消息会全量发送到这2个Consuemr Group,至于这2个Consumer Group是集群消费还是广播消费,自己定义即可
工作流程在官方文档写的很详细,不再深入了
https://github.com/apache/rocketmq/tree/master/docs/cn
Message消息的各种处理方式涉及到的内容较多,所以我就不在文章中放代码了,直接放GitHub了,目前还在不断完善中
地址为:https://github.com/erlieStar/rocketmq-examples,
和之前的RabbitMQ一个风格,基本上所有知识点都涉及到了
地址为:https://github.com/erlieStar/rabbitmq-example
每个消息必须属于一个Topic。RocketMQ中每个消息具有唯一的Message Id,且可以携带具有业务标识的Key,我们可以通过Topic,Message Id或Key来查询消息
消息消费的方式
- Pull(拉取式消费),Consumer主动从Broker拉取消息
- Push(推送式消费),Broker收到数据后会主动推送给Consumer,实时性较高
消息的过滤方式
- 指定Tag
- SQL92语法过滤
消息的发送方式
- 同步,收到响应后才会发送下一条消息
- 异步,一直发,用异步的回调函数来获取结果
- 单向(只管发,不管结果)
消息的种类
- 顺序消息
- 延迟消息
- 批量消息
- 事务消息
顺序消息
顺序消息分为局部有序和全局有序
官方介绍为普通顺序消息和严格顺序消息
局部有序:同一个业务相关的消息是有序的,如针对同一个订单的创建和付款消息是有序的,只需要在发送的时候指定message queue即可,如下所示,将同一个orderId对应的消息发送到同一个队列
- SendResult sendResult = producer.send(message, new MessageQueueSelector() {
- /**
- * @param mqs topic对应的message queue
- * @param msg send方法传入的message
- * @param arg send方法传入的orderId
- */
- @Override
- public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
- // 根据业务对象选择对应的队列
- Integer orderId = (Integer) arg;
- int index = orderId % mqs.size();
- return mqs.get(index);
- }
- }, orderId);
消费者所使用的Listener必须是MessageListenerOrderly(对于一个队列的消息采用一个线程去处理),而平常的话我们使用的是MessageListenerConcurrently
全局有序:要想实现全局有序,则Topic只能有一个message queue。
延迟消息
RocketMQ并不支持任意时间的延迟,需要设置几个固定的延时等级,从1s到2h分别对应着等级1到18
- // org.apache.rocketmq.store.config.MessageStoreConfig
- private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h"
批量消息
批量发送消息能显著提高传递小消息的性能,限制是这批消息应该有相同的topic,相同的waitStoreMsgOK,而且不能是延时消息,一批消息的总大小不应超过1MB
事务消息
事务在实际的业务场景中还是经常遇到的,以转账为例子
张三给李四转账100元,可以分为如下2步
- 张三的账户减去100元
- 李四的账户加上100元
这2个操作要是同时成功,要是同时失败,不然会造成数据不一致的情况,基于单个数据库Connection时,我们只需要在方法上加上@Transactional注解就可以了。
如果基于多个Connection(如服务拆分,数据库分库分表),加@Transactional此时就不管用了,就得用到分布式事务
分布式事务的解决方案很多,RocketMQ只是其中一种方案,RocketMQ可以保证最终一致性
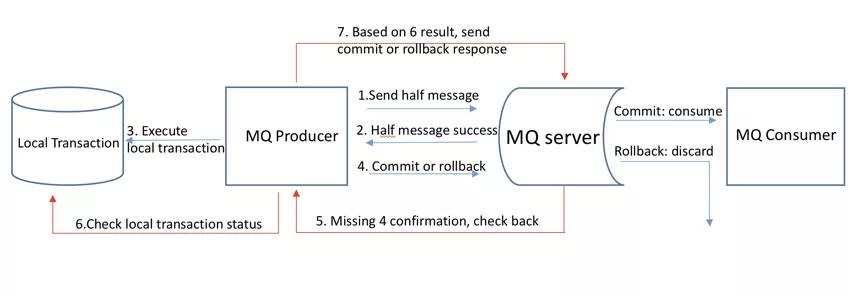
RocketMQ实现分布式事务的流程如下
- producer向mq server发送一个半消息
- mq server将消息持久化成功后,向发送方确认消息已经发送成功,此时消息并不会被consumer消费
- producer开始执行本地事务逻辑
- producer根据本地事务执行结果向mq server发送二次确认,mq收到commit状态,将消息标记为可投递,consumer会消费该消息。mq收到rollback则删除半消息,consumer将不会消费该消息,如果收到unknow状态,mq会对消息发起回查
- 在断网或者应用重启等特殊情况下,步骤4提交的2次确认有可能没有到达mq server,经过固定时间后mq会对该消息发起回查
- producer收到回查后,需要检查本地事务的执行状态
- producer根据本地事务的最终状态,再次提交二次确认,mq仍按照步骤4对半消息进行操作
理解了原理,看代码实现就很容易了,放一个官方的example
- public class TransactionListenerImpl implements TransactionListener {
- private AtomicInteger index = new AtomicInteger(0);
- private ConcurrentHashMap<String, Integer> localTrans = new ConcurrentHashMap<>();
- @Override
- public LocalTransactionState executeLocalTransaction(Message msg, Object arg) {
- int value = index.getAndIncrement();
- int status = value % 3;
- localTrans.put(msg.getTransactionId(), status);
- return LocalTransactionState.UNKNOW;
- }
- @Override
- public LocalTransactionState checkLocalTransaction(MessageExt msg) {
- Integer status = localTrans.get(msg.getTransactionId());
- if (status != null) {
- switch (status) {
- case 0:
- return LocalTransactionState.UNKNOW;
- case 1:
- return LocalTransactionState.COMMIT_MESSAGE;
- case 2:
- return LocalTransactionState.ROLLBACK_MESSAGE;
- default:
- return LocalTransactionState.COMMIT_MESSAGE;
- }
- }
- return LocalTransactionState.COMMIT_MESSAGE;
- }
- }
实现分布式事务需要实现TransactionListener接口,2个方法的作用如下
- executeLocalTransaction,执行本地事务
- checkLocalTransaction,回查本地事务状态
针对这个例子,所有的消息都会回查,因为返回的都是UNKNOW,回查的时候status=1的数据会被消费,status=2的数据会被删除,status=0的数据会一直回查,直到超过默认的回查次数。
发送方代码如下
- public class TransactionProducer {
- public static final String RPODUCER_GROUP_NAME = "transactionProducerGroup";
- public static final String TOPIC_NAME = "transactionTopic";
- public static final String TAG_NAME = "transactionTag";
- public static void main(String[] args) throws Exception {
- TransactionListener transactionListener = new TransactionListenerImpl();
- TransactionMQProducer producer = new TransactionMQProducer(RPODUCER_GROUP_NAME);
- ExecutorService executorService = new ThreadPoolExecutor(2, 5, 100, TimeUnit.SECONDS,
- new ArrayBlockingQueue<>(100), new ThreadFactory() {
- @Override
- public Thread newThread(Runnable r) {
- Thread thread = new Thread();
- thread.setName("transaction-msg-check-thread");
- return thread;
- }
- });
- producer.setExecutorService(executorService);
- producer.setTransactionListener(transactionListener);
- producer.start();
- for (int i = 0; i < 100; i++) {
- Message message = new Message(TOPIC_NAME, TAG_NAME,
- ("hello rocketmq " + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
- SendResult sendResult = producer.send(message);
- System.out.println(sendResult);
- }
- TimeUnit.HOURS.sleep(1);
- producer.shutdown();
- }
- }
看到这,可能有人会问了,我们先执行本地事务,执行成功后再发送消息,这样可以吗?
其实这样做还是有可能会造成数据不一致的问题。假如本地事务执行成功,发送消息,由于网络延迟,消息发送成功,但是回复超时了,抛出异常,本地事务回滚。但是消息其实投递成功并被消费了,此时就会造成数据不一致的情况
那消息投递到mq server,consumer消费失败怎么办?
如果是消费超时,重试即可。如果是由于代码等原因真的消费失败了,此时就得人工介入,重新手动发送消息,达到最终一致性。
消息重试
发送端重试
producer向broker发送消息后,没有收到broker的ack时,rocketmq会自动重试。重试的次数可以设置,默认为2次
- DefaultMQProducer producer = new DefaultMQProducer(RPODUCER_GROUP_NAME);
- // 同步发送设置重试次数为5次
- producer.setRetryTimesWhenSendFailed(5);
- // 异步发送设置重试次数为5次
- producer.setRetryTimesWhenSendAsyncFailed(5);
消费端重试
顺序消息的重试
对于顺序消息,当Consumer消费消息失败后,RocketMQ会不断进行消息重试,此时后续消息会被阻塞。所以当使用顺序消息的时候,监控一定要做好,避免后续消息被阻塞
无序消息的重试
当消费模式为集群模式时,Broker才会自动进行重试,对于广播消息是不会进行重试的
当consumer消费消息后返回ConsumeConcurrentlyStatus.CONSUME_SUCCESS表明消费消息成功,不会进行重试
当consumer符合如下三种场景之一时,会对消息进行重试
- 返回ConsumeConcurrentlyStatus.RECONSUME_LATER
- 返回null
- 主动或被动抛出异常
RocketMQ默认每条消息会被重试16次,超过16次则不再重试,会将消息放到死信队列,当然我们也可以自己设置重试次数
每次重试的时间间隔如下
| 第几次重试 | 与上次间隔时间 | 第几次重试 | 与上次间隔时间 |
|---|---|---|---|
| 1 | 10s | 10 | 7分钟 |
| 2 | 30s | 11 | 8分钟 |
| 3 | 1分钟 | 12 | 9分钟 |
| 4 | 2分钟 | 13 | 10分钟 |
| 5 | 3分钟 | 14 | 20分钟 |
| 6 | 4分钟 | 15 | 30分钟 |
| 7 | 5分钟 | 16 | 1小时 |
| 8 | 6分钟 | 17 | 2小时 |
重试队列和死信队列
当消息消费失败,会被发送到重试队列
当消息消费失败,并达到最大重试次数,rocketmq并不会将消息丢弃,而是将消息发送到死信队列
死信队列有如下特点
- 里面存的是不能被正常消费的消息
- 有效期与正常消息相同,都是3天,3天后会被删除
- 每个死信队列对应一个Consumer Group ID,即死信队列是消费者组级别的
- 如果一个Consumer Group没有产生死信消息,则RocketMQ不会创建对应的死信队列
- 死信队列包含了一个Consumer Group下的所有死信消息,不管该消息属于哪个Topic
- 重试队列的命名为 %RETRY%消费组名称 死信队列的命名为 %DLQ%消费组名称
RocketMQ高性能和高可用的方式
整体架构
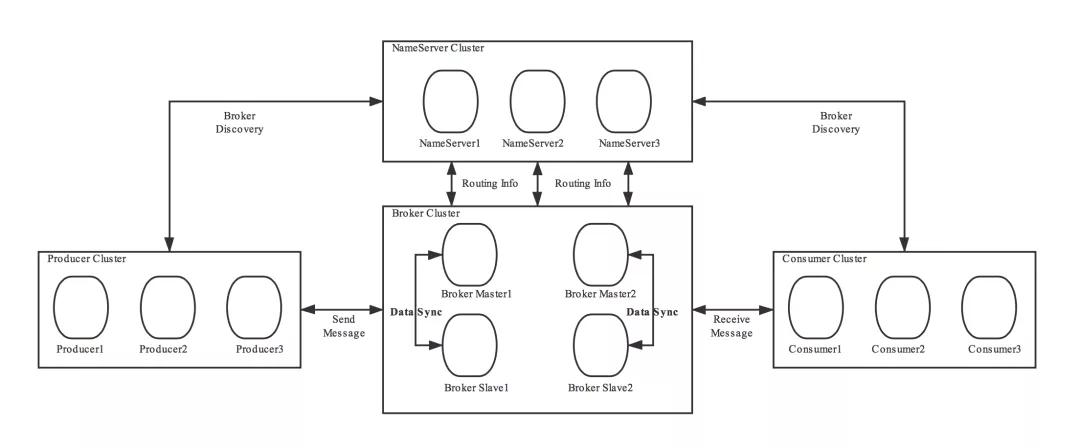
rocketmq是通过broker主从机制来实现高可用的。相同broker名称,不同brokerid的机器组成一个broker组,brokerId=0表明这个broker是master,brokerId>0表明这个broker是slave。
消息生产的高可用:创建topic时,把topic的多个message queue创建在多个broker组上。这样当一个broker组的master不可用后,producer仍然可以给其他组的master发送消息。rocketmq目前还不支持主从切换,需要手动切换
消息消费的高可用:consumer并不能配置从master读还是slave读。当master不可用或者繁忙的时候consumer会被自动切换到从slave读。这样当master出现故障后,consumer仍然可以从slave读,保证了消息消费的高可用
消息存储结构
RocketMQ需要保证消息的高可靠性,所以要将数据通过磁盘进行持久化存储。
将数据存到磁盘会不会很慢?其实磁盘有时候比你想象的快,有时候比你想象的慢。目前高性能磁盘的顺序写速度可以达到600M/s,而磁盘的随机写大概只有100k/s,和顺序写的性能相差6000倍,所以RocketMQ采用顺序写。
并且通过mmap(零拷贝的一种实现方式,零拷贝可以省去用户态到内核态的数据拷贝,提高速度)具体原理并不是很懂,有兴趣的小伙伴可以看看相关书籍
总而言之,RocketMQ通过顺序写和零拷贝技术实现了高性能的消息存储
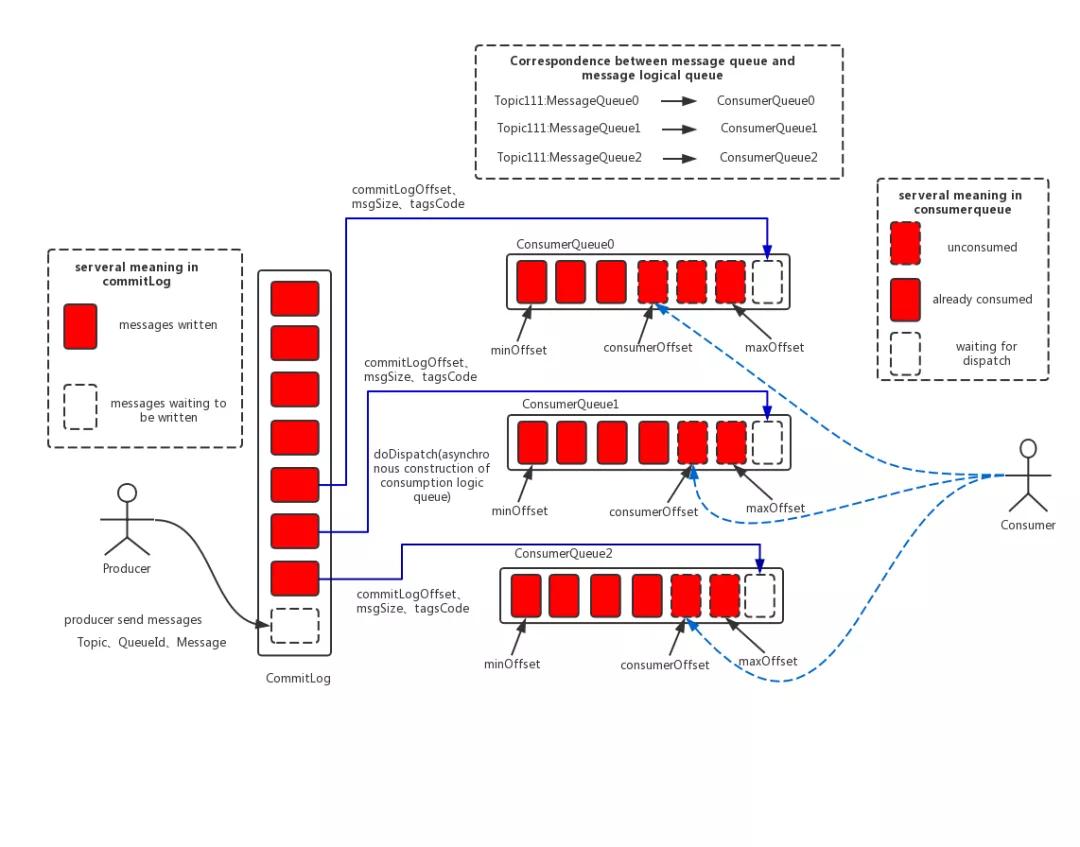
和消息相关的文件有如下几种
- CommitLog:存储消息的元数据
- ConsumerQueue:存储消息在CommitLog的索引
- IndexFile:提供了一种通过key或者时间区间来查询消息的方法
刷盘机制
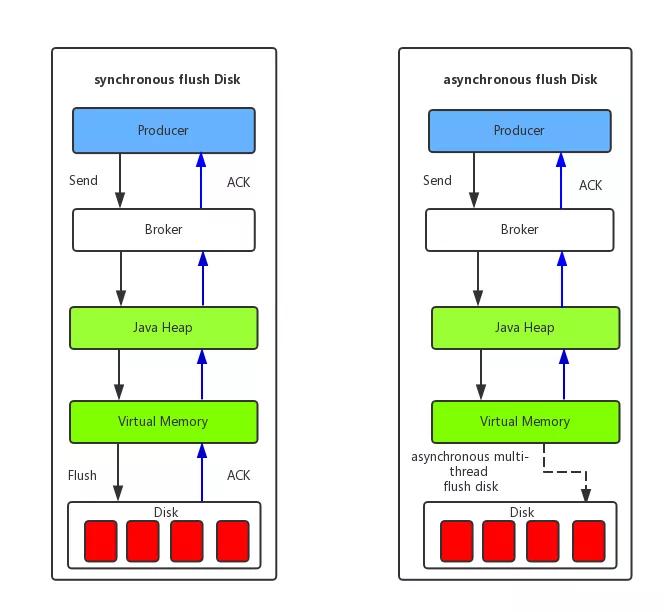
- 同步刷盘:消息被写入内存的PAGECACHE,返回写成功状态,当内存里的消息量积累到一定程度时,统一触发写磁盘操作,快速写入 。吞吐量低,但不会造成消息丢失
- 异步刷盘:消息写入内存的PAGECACHE后,立刻通知刷盘线程刷盘,然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,给应用返回消息写成功的状态。吞吐量高,当磁盘损坏时,会丢失消息
主从复制
如果一个broker有master和slave时,就需要将master上的消息复制到slave上,复制的方式有两种
- 同步复制:master和slave均写成功,才返回客户端成功。maste挂了以后可以保证数据不丢失,但是同步复制会增加数据写入延迟,降低吞吐量
- 异步复制:master写成功,返回客户端成功。拥有较低的延迟和较高的吞吐量,但是当master出现故障后,有可能造成数据丢失
负载均衡
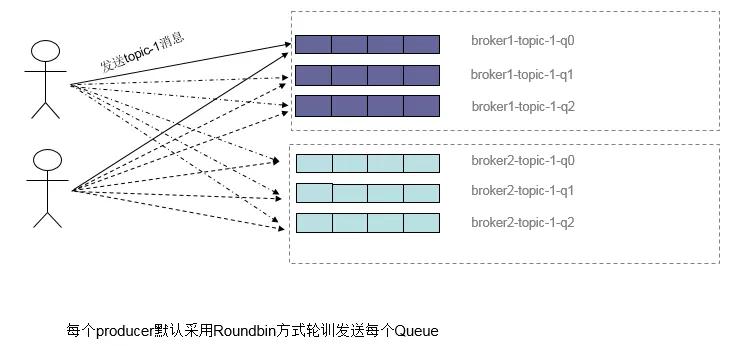
Producer负载均衡
producer在发送消息时,默认轮询所有queue,消息就会被发送到不同的queue上。而queue可以分布在不同的broker上
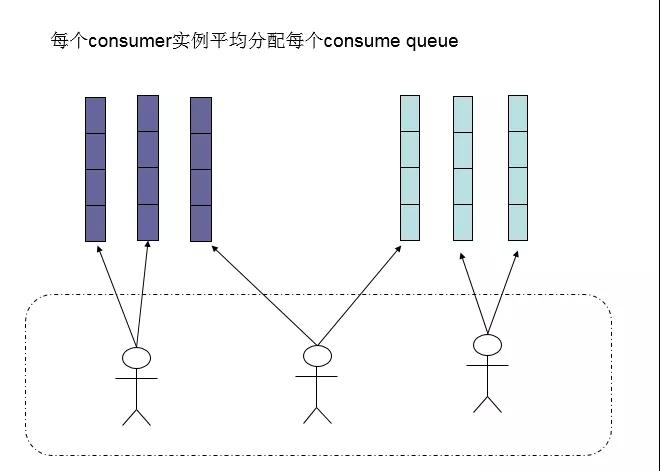
Consumer负载均衡
默认的分配算法是AllocateMessageQueueAveragely,如下图
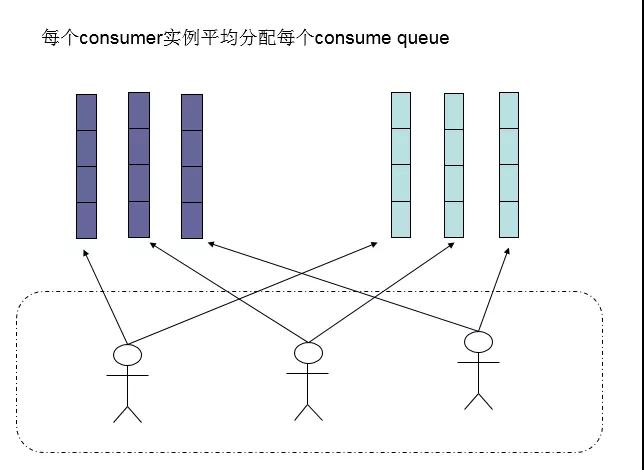
还有另外一种平均的算法是AllocateMessageQueueAveragelyByCircle,也是平均分摊queue,只是以环状轮流分queue的形式,如下图:
如果consumer数量比message queue还多,则多会来的consumer会被闲置。所以不要让consumer的数量多于message queue的数量
图形化管理工具
在rocketmq-externals这个项目中提供了rocketmq的很多扩展工具
github地址如下:https://github.com/apache/rocketmq-externals
其中有一个子项目rocketmq-console提供了rocketmq的图像化工具,提供了很多实用的功能,如前面说的通过Topic,Message Id或Key来查询消息,重新发送消息等,还是很方便的
本文转载自微信公众号「Java识堂」,可以通过以下二维码关注。转载本文请联系Java识堂公众号。

























