













聚合是数据分析任务中广泛使用的运算符,Spark为此提供了坚实的框架。 以下是使用Spark可以针对大数据进行聚合的五种不同方式。
RDD上的GroupByKey或ReduceByKey转换:RDD是Spark中分布式数据收集的最早表示,其中数据通过" T"类型的任意Java对象表示。 RDD上的聚合与map-reduce框架中的reduce概念相似,在reduce中,reduce函数(作用于两个输入记录以生成聚合记录)是聚合的关键。 使用RDD时,聚合可以通过GroupByKey或ReduceByKey转换来执行,但是,这些转换仅限于Pair RDD(元组对象的集合,每个元组都由类型为" K"的键对象和类型为" V"的值对象组成) 。
在通过GroupByKey进行聚合的情况下,转换会导致元组对象具有键对象和针对该键对象的所有值对象的集合。 因此,之后需要应用一个映射器(通过map,maptoPair或mapPartitions进行映射转换),以便将每个Tuple对象的值对象的集合减少为一个聚合的值对象。
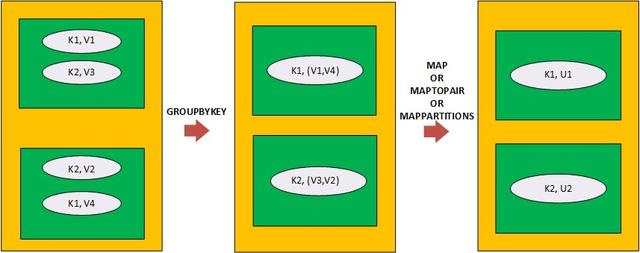
> Aggregation on a Pair RDD (with 2 partitions) via GroupByKey followed via either of map, maptopair
映射程序(例如map,maptoPair和mappartitions转换)包含聚合函数,以将类型为" V"的值对象的集合减少为类型为" U"的聚合对象。 聚合函数可以是任意函数,不需要遵循关联性或交换性状。 GroupByKey转换具有三种风格,它们因应用GroupByKey转换而在RDD的分区规范上有所不同。 GroupByKey可以总结为:
- GroupByKey (PairRDD) => PairRDD> Map (PairRDD>) => PairRDD
如果通过ReduceByKey进行聚合,则转换将直接导致具有键对象和针对该键对象的聚合对象的元组对象。 与GroupByKey一样,在ReduceByKey之后不需要映射器。 ReduceByKey转换采用关联和可交换的聚合函数,以便在跨分区聚合记录之前,可以在本地聚合位于同一分区的记录。 同样,聚合函数接受两个说类型为" V"的值对象,并返回一个类型为" V"的对象。 与GroupByKey相似,ReduceByKey转换也具有三种风格,它们的区别在于通过应用ReduceByKey转换而导致的RDD分区规范。 ReduceByKey可以总结为:
- ReduceByKey(PairRDD, Function) => PairRDD
在GroupByKey和ReduceByKey中,前者更通用,可以与任何聚合函数一起使用,而后者则更有效,但仅适用于前面所述的一类聚合函数。
RDD或数据集上的Mappartitions:如先前博客中所述,Mappartitions是功能强大的窄转换之一,可在RDD和Dataset(Spark中的数据表示)上使用,以明智地执行各种操作。 这样的操作之一也包括聚合。 但是,唯一需要满足的条件是,属于相同分组关键字的记录应位于单个分区中。 在涉及分组密钥的混排操作中实现的RDD或数据集(要聚合)中可以隐式满足此条件。 同样,可以通过首先基于分组密钥对RDD或数据集进行重新分区来明确实现该条件。
在用于典型聚合流的mappartitions内,必须首先实例化一个Hashmap,将Hashmap与相应的分组键相对应地存储聚合的Value Objects。 然后,在迭代基础分区的数据收集时,将重复更新此Hashmap。 最后,返回包含在映射中的聚合值/对象(可选以及关联的分组键)的迭代器。
由于基于Mappartitions的聚合涉及将Hashmap保留在内存中以保存键和聚合的Value对象,因此,如果大量唯一分组键驻留在基础分区中,则Hashmap将需要大量堆内存,因此可能导致 相应执行程序的内存不足终止的风险。 从此以后,不应该歪曲跨分区的分组密钥分配,否则会由于过度提供执行程序内存来处理偏斜而导致执行程序内存浪费。 此外,由于需要基于堆内存的聚合哈希图,因此与Spark中的专用聚合运算符相比,对内存的相对内存分配更多,但是如果内存不是约束,则基于Mappartitions的聚合可以提供良好的性能提升。
用于数据帧或数据集的UDAF:与上述方法不同,UDAF基于聚合缓冲区的概念以及在此缓冲区上运行的一组方法来实现聚合。
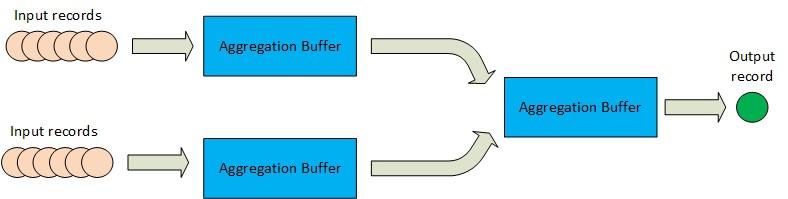
> Aggregation buffer based aggregation flow in Spark (for Datasets and Dataframe)
到目前为止,UDAF是为Spark中的分布式数据收集的Dataframe或Dataset表示编写聚合逻辑的最常用方法。 UDAF在数据收集的无类型视图上工作,在该视图中,数据记录被视为(表的)一行,其架构定义了该行中每一列的类型和可空性。 通过扩展包" org.apache.spark.sql.expressions"中存在的" UserDefinedAggregationFunction"类并覆盖基类中以下方法的实现,可以在Spark中创建UDAF:
- /*Return schema for input column(s) to the UDAF, schema being built using StructType*/
- => public StructType inputSchema()
- /*Return schema of aggregation buffer, schema being built using StructType */
- => public StructType bufferSchema()
- /*DataType of final aggregation result*/
- => public DataType dataType()
- /*Initialize aggregation buffer*/
- => public void initialize(MutableAggregationBuffer buffer)
- /*Update aggregation buffer for each of the untyped view (Row) of an input object*/
- => public void update(MutableAggregationBuffer buffer, Row row)
- /*Update current aggregation buffer with a partially aggregated buffer*/
- => public void merge(MutableAggregationBuffer buffer, Row buffer)
- /*Evaluate final aggregation buffer and return the evaluated value of DataType declared earlier */
- => public Object evaluate(Row buffer)
除了覆盖上述方法外,还可以始终声明其他字段(在UDAF构造函数中使用可选的初始化)和自定义UDAF类中的其他方法,以便在覆盖方法中使用它们以实现聚合目标。
在使用UDAF之前,必须先在Spark框架中注册相同的实例:
- spark.udf.register('sampleUDAF, new SampleUDAF());
注册后,可以在Spark SQL查询中使用UDAF来聚合整个数据集/数据框或数据集/数据框中的记录组(通过一列或多列分组)。 除了直接在Spark SQL查询中使用外,还可以通过数据框/数据集聚合API(例如" agg")使用UDAF。
UDAF虽然是定义自定义聚合的一种流行方法,但是当在聚合缓冲区中使用复杂的数据类型(数组或映射)时,会遇到性能问题。 这是由于以下事实:在UDAF中的每次更新操作期间,对于复杂的数据类型,将scala数据类型(用户特定)转换为相应的催化剂数据类型(催化剂内部数据类型)(反之亦然)变得非常昂贵。 从内存和计算的角度来看,此成本都更高。
数据集的聚合器:聚合器是对数据集执行聚合的最新方法,类似于UDAF,它也基于聚合缓冲区的概念以及在该缓冲区上运行的一组方法。 但是,聚合器进行聚合的方式称为类型化聚合,因为它涉及对各种类型的对象进行操作/使用各种类型的对象进行操作。 聚合器的输入,聚合缓冲区和最终的聚合输出(从缓冲区派生)都是具有相应Spark编码器的某些类型的对象。 用户可以通过使用为IN定义的类型(输入记录类型)扩展抽象的通用'Aggregator '类(在包'org.apache.spark.sql.expressions中提供)来定义自己的自定义Aggregator。 ,为BUF(聚合缓冲区)定义的类型和为OUT(输出记录类型)定义的类型,以及在基类中重写以下方法的实现:
- /* return Encoder for aggregation buffer of type BUF. This is required for buffer ser/deser during shuffling or disk spilling */
- => public Encoder<BUF> bufferEncoder()
- /* return Encoder for output object of type OUT after aggregation is performed */
- => public Encoder<OUT> outputEncoder()
- /* return updated aggregation buffer object of type BUF after aggregating the existing buffer object of type BUF with the input object of type IN*/
- => public BUF reduce(BUF buffer, IN input) ()
- /* return updated aggregation buffer of type BUF after merging two partially aggregated buffer objects of type BUF */
- => public BUF merge(BUF buffer1, BUF buffer2)
- /* return output object of type OUT from evaluation of aggregation buffer of type BUF */
- => public OUT finish(BUF arg0)
- /* return buffer object of type BUF after initializing the same */
- => public BUF zero()
由于Aggregator本机支持将聚合缓冲区作为对象,因此它是高效的,并且不需要与从Scala类型转换为催化剂类型(反之亦然)相关的不必要的开销(与UDAF一样)。 同样,聚合器的聚合方式在编写聚合逻辑时提供了更多的灵活性和编程的美感。 聚合器也已集成到无类型聚合流中,以支持SQL,例如即将发布的版本中的查询。
预定义的聚合功能:Spark提供了各种预构建的聚合功能,可用于分布式数据收集的数据框或数据集表示形式。 这些预先构建的函数可以在SPARK SQL查询表达式中使用,也可以与为Dataframe或Dataset定义的聚合API一起使用。 在org.apache.spark.sql包中,所有预先构建的聚合函数都定义为"函数"类的静态方法。 带下划线的链接可以列出所有这些功能的列表。
预定义的聚合函数经过高度优化,在大多数情况下可以直接与Spark tungusten格式一起使用。 因此,如果" functions"类中存在预先构建的聚合函数,则Spark程序员应始终偏向于使用它们。 万一那里没有所需的聚合函数,那么只有一个可以诉诸于编写自定义聚合函数。
如果您对Spark Aggregation框架有更多查询,请随时在评论部分提问。




















