在机器学习的流程中数据挖掘是重要的一环。数据挖掘是从大量数据中提取隐藏的或未知,但可能有用信息的过程。这些数据最终会被加上标签,用于模型的训练。很多的数据科学家和机器学习工程师都有其熟悉的数据挖掘工具,但市场上也不乏许多开源的数据挖掘工具。
Apache Mahout
Apache Mahout是流行的分布式线性代数框架。该框架是具有数学表达能力的Scala DSL,能够让统计学家和数据科学家以更快的方式实现其算法。它构建了一个用于快速创建可扩展且性能驱动的机器学习应用程序的环境。

Apache Mahout有诸多优势,比如它允许应用程序以更快的方式分析大型数据集;支持数学表达式Scala DSL;支持多个分布式后端,包括Apache Spark;适用于CPU/GPU/CUDA加速的模块化本机求解器。
DataMelt
DataMelt或DMelt是用于数值计算,数学、统计、符号计算,数据分析和数据可视化的开源软件。该平台是Python,Ruby,Groovy等各种脚本语言的组合,以及其他Java软件包。
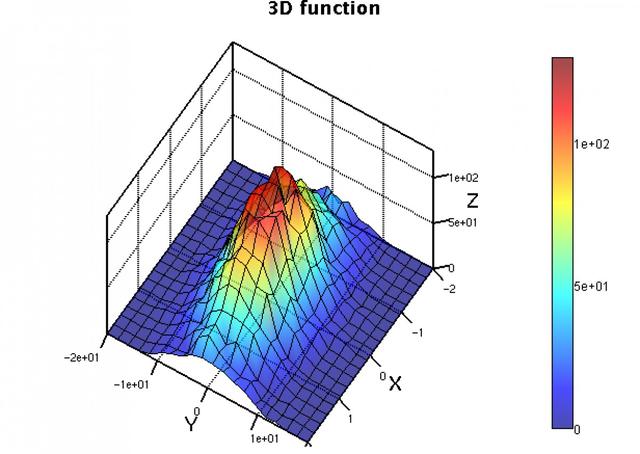
DMelt是一个计算平台,可以在各种操作系统上与不同的编程语言一起使用;DataMelt可以与Java平台的几种脚本语言一起使用,例如Jython(Python编程语言),Groovy,JRuby(Ruby编程语言)和BeanShell;它可创建高质量的矢量图形图像(SVG,EPS,PDF等),这些图像可以包含在LaTeX和其他文本处理系统中。
ELKI
由Index-Structures或ELKI支持的开发KDD应用程序的环境,是用Java语言编写的开源数据挖掘软件。该平台能够研究算法,重点是聚类分析和离群值检测中的无监督方法。
它提供了数据索引结构,例如R*树,可显著提高性能;方便该领域的研究人员和学生进行扩展;ELKI提供了大量可高度参数化的算法。
Knime
KNIME Analytics Platform用Java编写,基于Eclipse,是用于承载数据科学任务的开源软件。它是一种多语言软件开发环境,包括一个集成开发环境(IDE)和一个可扩展的插件系统。Knime是一个免费的数据分析,报告和集成平台。
它允许用户从2000多个节点中进行选择来构建工作流程;允许使用直观的拖放式图形界面,创建可视化工作流程,而无需编程。
Orange
Orange是一款开源的,基于组件的数据挖掘软件,用于机器学习和数据可视化。它包括一系列数据可视化、搜索、预处理和建模技术,并且可以用作Python编程语言的模块。
Orange具有交互式数据可视化功能,还可以执行简单的数据分析;它包括交互式数据搜索,可通过清晰的可视化进行快速定性分析。
Rattle
Rattle用R语言编写,是流行的用于数据挖掘的开源GUI,可显示数据的统计和可视摘要。它可以转换数据,以便可以对其进行建模。它根据数据构建无监督和受监督的机器学习模型,以图形方式显示模型的性能,并对新数据集进行评分以部署到生产中。
Rattle通过GUI展示R Statistics软件的功能,它提供了可观的数据挖掘功能;通过图形用户界面进行的所有交互都被捕获为R脚本,可以独立于Rattle界面在R中轻松执行;该工具可用于学习和发展R的技能,然后在Rattle中构建初始模型。
scikit-learn
scikit-learn是一个流行的Python库,用于数据分析和数据挖掘,它建立在SciPy,Numpy和Matplotlib的基础上。scikit学习的主要功能为分类、回归、聚类、降维、模型选择以及数据预处理。
scikit-learn包括用于预测数据分析的简单有效的工具;它提供了流行的模型,包括降维、交叉验证集成方法、参数调整等等。
Weka
Weka或Waikato知识分析环境是一种流行的开源机器学习软件,可以通过图形用户界面,标准终端应用程序或Java API进行访问。它是用于解决实际数据挖掘问题的机器学习算法的集合。它是用Java编写的,几乎可以在任何平台上运行。
Weka包含大量用于标准机器学习任务的内置工具,它提供对著名工具箱,如scikit-learn,R以及Deeplearning4j的透明访问。