本文转载自微信公众号「phodal」,作者phodal 。转载本文请联系phodal公众号。
最近,因为公司项目的原因,对一个大型的系统做了一个简要的架构分析。由于,时间上的限制,所以在这里我也只能做一个快速的分析,并没有其它的可能性。
太长不看版步骤:
- clone 项目的代码,以及相关的依赖
- 尝试编译系统
- 借助目录 + 编辑器进行初步分析
- 借助工具进行可视化分析
- 配置 IDE,进行源码分析
- 绘制架构图
- 从用户旅程验证架构正确性
- 总结输出
- 回溯版本,进一步验证
PS:这里所针对的情况是,没有现有架构图的情况。如果已经有现成的架构,那么它的步骤应该是不一样的。依我之间的经验来看,它应该是这样的:
- 寻找架构图
- 寻找相关的阅读代码文档、日记
- 其它同上
0. clone
多数情况下,把远程的代码 clone 到本地,是一件非常简单的事情。但是,并非所有的情况都是如此,因为对一个大型的系统来说,我们要面对着这么一些情况:
- 代码库过多
- 代码量过大
于是,在我所需要分析的这个系统里,它采用了 Google 的多仓库管理工具 Repo。这样就从一定程度上解决代码库过多的问题——对于我们来说,我们只需要执行一个 repo sync,它就可以帮助我们把所有的代码 clone 下来。而后,我们只需要等待几小时,或者几天,就可以下到我们的代码库了。
1. 尝试编译系统
有了代码之后,我们就可以尝试按文档的步骤来构建应用。期间,我们还需要解决一些工具上的问题,又或者是按官方的 issue 来处理一些异常情况。
与此同时,你还可能会遇到我在这个项目上遇到的问题:当前版本是无法成功构建的。
于是,我还需要重新花一天时间,再找到某一个特定版本的代码……。
2. 借助目录 + 编辑器进行初步分析
与此同时,在我们进行编译的时候,还可以同时简单地对项目进行分析:
- 目录结构分析。通过查看目录名称和目录结构,分析项目的组成关系。
- 代码简单分析。嗯,从一个入口点,一步步查看调用关系等。
之所以,我们还不能用 IDE 进行分析的一个原因是:对于这样的一个系统来说,IDE 是一个庞大的吃内存怪物。而在当前时刻,我们还在尝试构建这个系统,它不仅吃内存,还吃 CPU。甚至于,你的电脑还会因此而卡住。
3. 工具可视化
进一步地考虑到了项目的代码量的问题,简单地靠人力分析起来比较困难。我们就需要借助于一些工具来对代码进行分析。
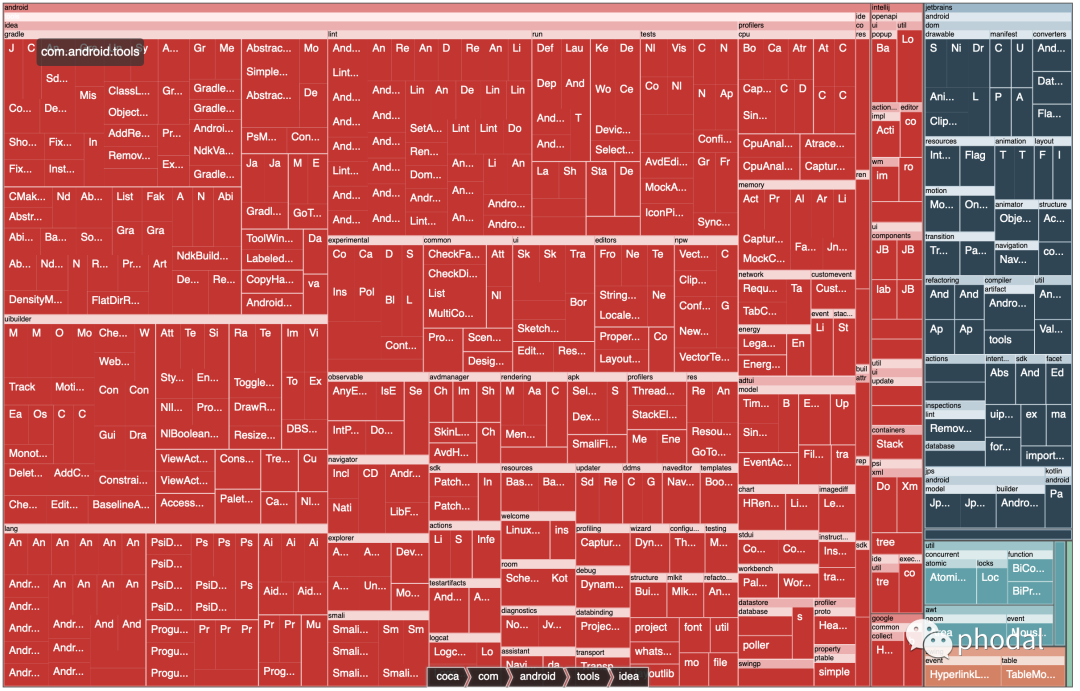
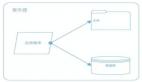
由于这是一个 Java 项目,我就可以用我之前写的系统分析工具:Coca。用它来绘制基本的架构图:
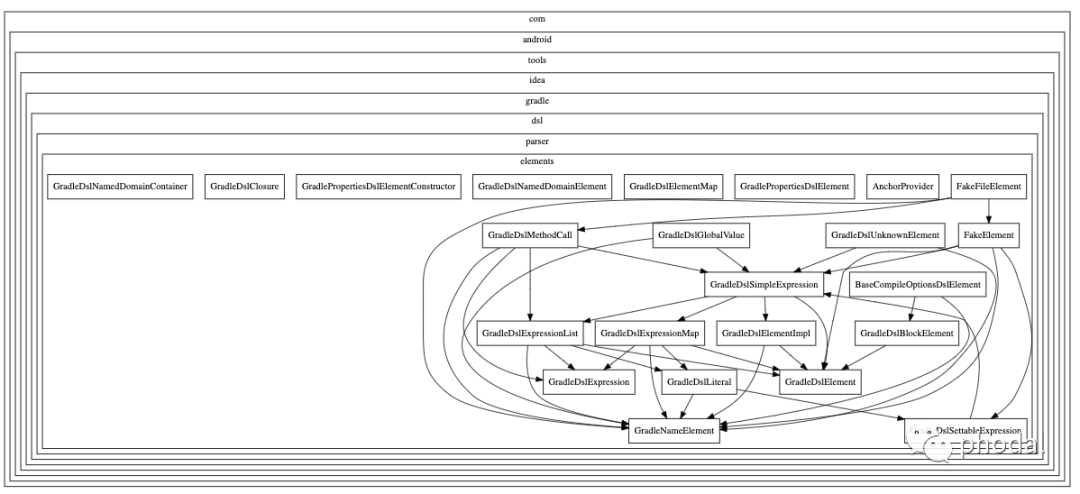
Package Arch Demo
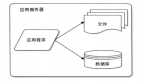
还有某一个方法或者是类的上下调用关系:
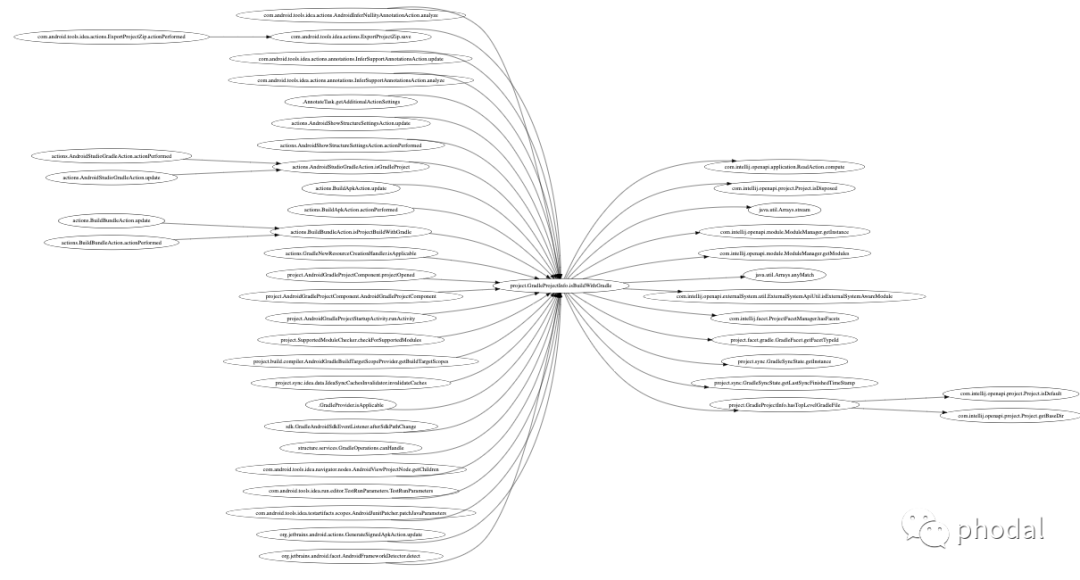
call
4. 配置 IDE,进行源码分析
在腾出了足够的 CPU + 内存资源之后,我们就可以轻松愉快地打开 IDE,进行源码分析。于是,很快地,我就需要等待 IDE 把代码索引完。
好了,IDE 卡住了。
模块分析
接着,我尝试了另外一种可能性,打开其中的某一个工程查看源码,但是很快地我发现了:缺少依赖。因为总体的构建失败,导致了总工程的一些依赖无法构建成功。
于是乎,我尝试了另外一种可能性:提取生产环境的依赖。毕竟,我所需要的依赖是一些 jar 包,而 jar 包会伴随着系统一起分发。这样一来,我就能从发布包中复制依赖到工程中使用,然后愉快地继续阅读代码了 —— 顺便地也能从依赖分析项目的情况。
工程内依赖分析
嗯,对于某些模块来说,它的产出是一个 jar 包,那么我们不一定需要阅读它地源码。只需要理清单个模块的构建产物,以及它的作用即可。
5. 绘制架构图
嗯,有了上面的基础之后,我们就可以绘制架构图了。
暂时没啥好的工具推荐,Google Slides、Sketch 这一类的都可以。
如果是调用关系的话,可以用 Graphviz 来绘制。只是呢,我已经用 Coca 来自动化绘制这个依赖关系了。哈哈
6. 用户旅程验证
我们阅读代码时,都是从入口开始验证。如基于 Spring 的微服务项目,都是从 API 注解作为入口点,一步步分析这个系统的架构;如 Angular 开发的前端应用,是从 main.ts 开始的。如 IDEA 插件,是从 plugin.xml 开始的,从 Action 绑定用户行为。
以类似的方式,我们就可以在不能调试的情况下,进一步验证架构的提炼是否合理。
7. 回溯版本,重复
考虑到我使用的版本是不能成功编译地版本,所以又花了点时间再下一个旧版本的系统,以验证部分关系是否是正确的。
毕竟只有成功编译地版本,才是正常的版本。
8. 总结输出
这些相关的产物可以有:
- 过程日志
- 问题总结
- 架构图
- 仿制的 MVP demo
在这里,我们还是强调一下最后一个,我经常拿这种方式来创造轮子。
人生苦短,我有 Coca。
http://github.com/phodal/coca