文转载自微信公众号「Java3y」,作者Java3y。转载本文请联系Java3y公众号。
到目前为止,三歪也已经接触到了不少的中间件了,比如说「Elasticsearch」「Redis」「HDFS」「Kafka」「HBase」等等。
可以发现的是,它们的持久化机制都差不得太多。今天想来总结一下,一方面想来回顾一下这些组件,一方面给还没入门过这些中间件的同学总结一下持久化的”套路“,后面再去学习的时候就会轻松很多。
这些中间件我的GitHub目录都是在的:
- https://github.com/ZhongFuCheng3y/3y
- https://gitee.com/zhongfucheng/Java3y
持久化
下面我们就直接来分别回顾一下各个中间件/组件的持久化机制,最后再总结就好了(三歪相信大家应该也能从回顾中看出些端倪)
为什么要持久化?原因也很简单:数据需要存储下来,不希望出了问题导致数据丢失
Elasticsearch
Elasticsearch是一个全文搜索引擎,对模糊搜索非常擅长。
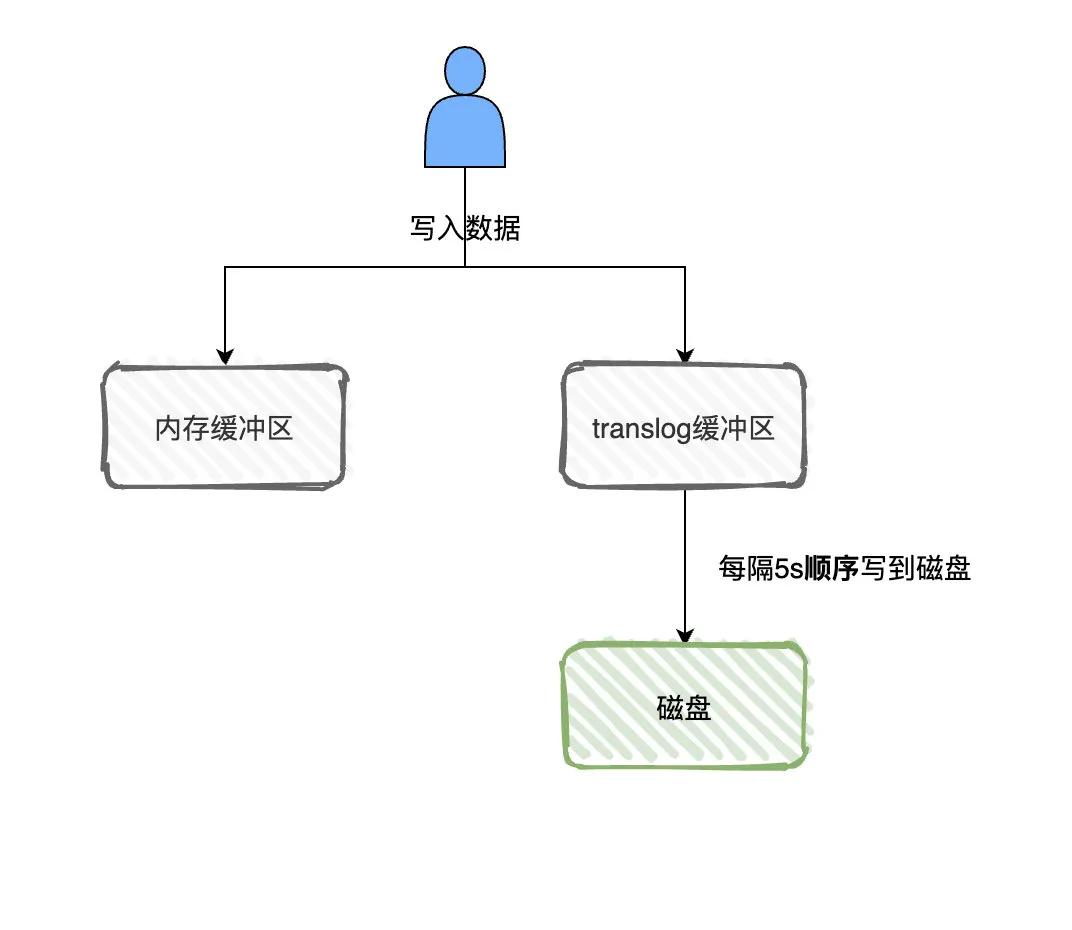
Elasticsearch在写数据的时候,会先写到内存缓存区,然后写到translog缓存区,每隔5s将translog缓冲区的数据刷到磁盘中
Kafka
众所周知,Kafka是一个高吞吐量的消息队列,那它是怎么持久化的呢?
Kafka relies heavily on the filesystem for storing and caching messages.
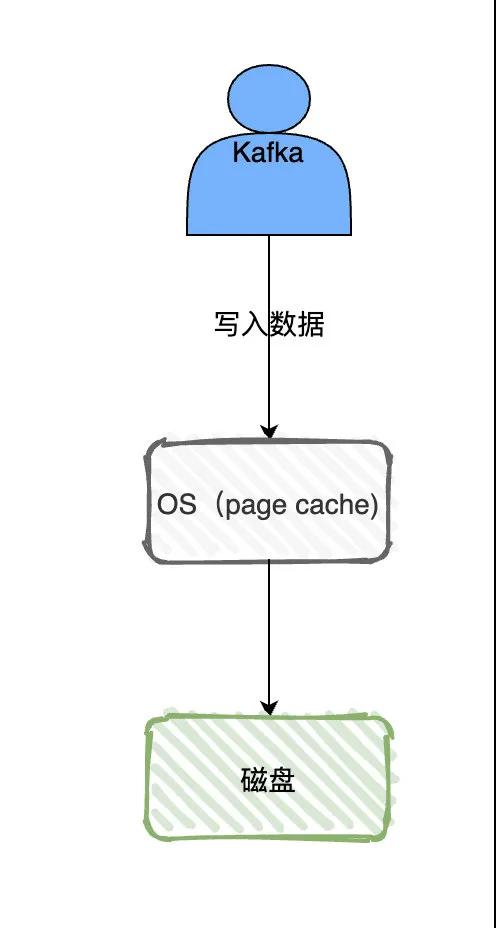
没错Kafka用的是文件系统来存储的。
在Kafka官网上其实也说了,Kafka的持久化依赖操作系统的pagecache和顺序写来实现的。
HDFS
HDFS是分布式文件系统,能存储海量的数据,那HDFS在写入数据的时候是怎么样的呢?
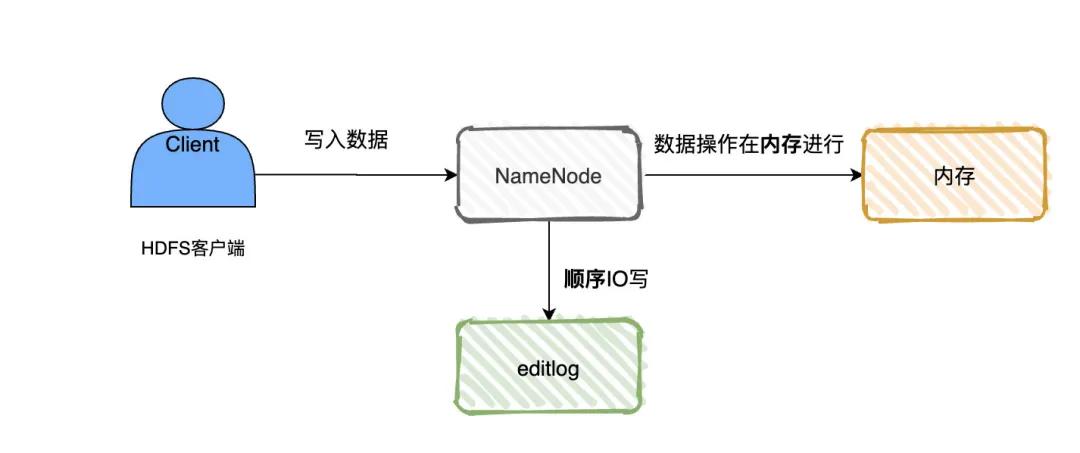
HDFS Client客户端无论读写都需要走到NameNode去获取/增删改文件的元数据,而NameNode则是专门维护这些元数据的地方。
所以,在HDFS写数据,需要先去NameNode上询问这些切分好的block往哪几个DataNode上写数据。
为了提高NameNode的效率,在写数据的时候,NameNode实际上是操作的是内存,然后涉及到增删改的数据顺序写到editlog日志文件上
Redis
Redis是基于内存的,如果不想办法将数据保存在硬盘上,一旦Redis重启(退出/故障),内存的数据将会全部丢失。
我们肯定不想Redis里头的数据由于某些故障全部丢失(导致所有请求都走MySQL),即便发生了故障也希望可以将Redis原有的数据恢复过来,所以Redis有RDB和AOF的持久化机制。
- RDB:基于快照,将某一时刻的所有数据保存到一个RDB文件中。
- AOF(append-only-file),当Redis服务器执行写命令的时候,将执行的写命令保存到AOF文件中。
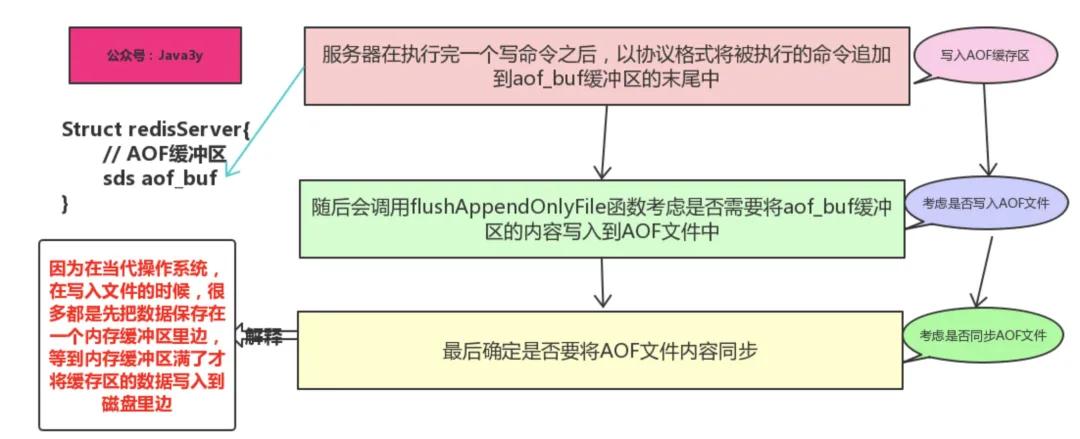
AOF持久化功能的实现可以分为3个步骤:
- 命令追加:命令写入aof_buf缓冲区
- 文件写入:调用flushAppendOnlyFile函数,考虑是否要将aof_buf缓冲区写入AOF文件中
- 文件同步:考虑是否将内存缓冲区的数据真正写入到硬盘
HBase
HBase是一个能存储海量数据的数据库。
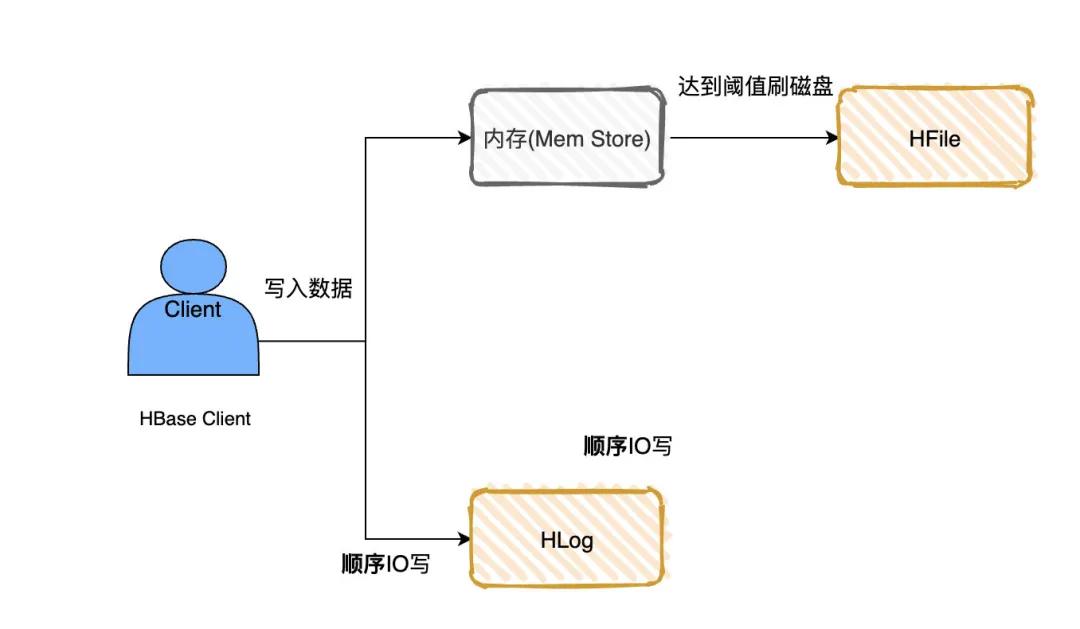
HBase在写数据的时候,会先写到Mem Store,当MemStore超过一定阈值,就会将内存中的数据刷写到硬盘上,形成StoreFile,而StoreFile底层是以HFile的格式保存,HFile是HBase中KeyValue数据的存储格式。
我们写数据的时候是先写到内存的,为了防止机器宕机,内存的数据没刷到磁盘中就挂了。我们在写Mem store的时候还会写一份HLog
MySQL
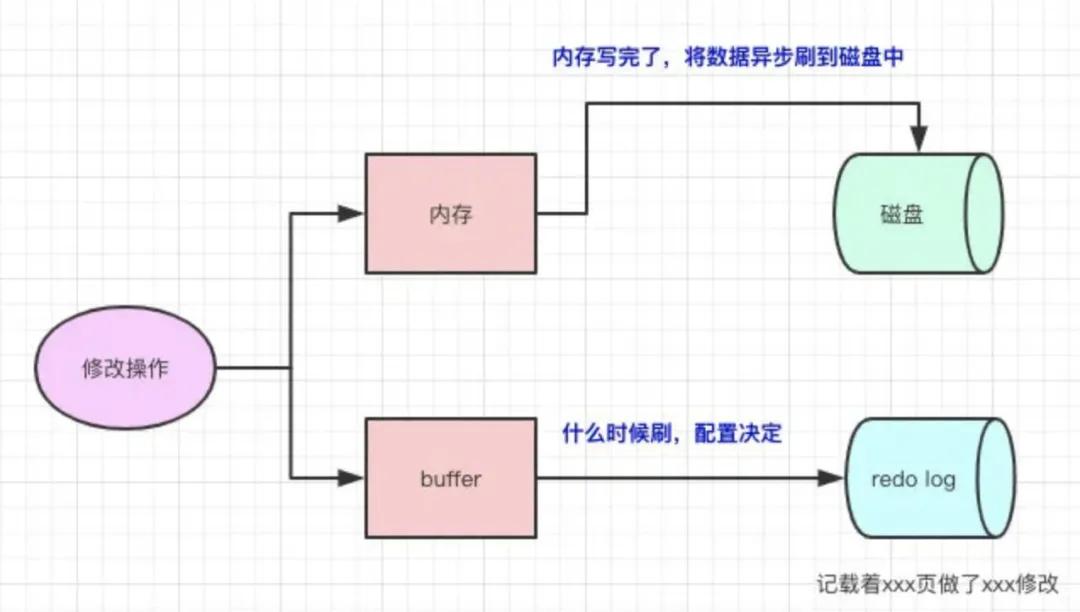
MySQL我们用得最多的InnoDB引擎是怎么存储的呢?它有redo log来支撑持久化的功能。
MySQL引入了redo log,内存写完了,然后会写一份redo log,这份redo log记载着这次在某个页上做了什么修改。
总结看完上面常见的中间件/组件的持久化方式,应该就不用我多说了吧?思想几乎都是一样的,只是他们记录“log”的名字不一样而已。
先写buffer,然后顺序IO写Log。防止buffer的数据还没刷到磁盘,宕机导致数据丢失。
对于Log文件,中间件也不会放任它们一直膨胀,导致体积很大:
- 在Redis里边,会对AOF文件进行重写
- 在HDFS里边,editlog会定时生成fsimage
- 在Elasticsearch里边,translog会根据阈值触发commit操作
- .....